


In the
most direct approach, plots are placed randomly or systematically over the
entire area. However, such an approach may not be efficient in stands that are
not uniform and where variation is high. In this case, stratified sampling is
more efficient especially when the area has been logged at different times
(temporal differences) and different intensities. For example, cutting
intensities may vary among compartments. Also, there is a tendency to remove
more trees closer to the road and to avoid removing trees in difficult terrain.
Thus it is better to calculate separate estimates for each stratum. Overall estimates
can still be made for the whole stand. Stratified estimates of the population
mean and total produce smaller variance than non-stratified estimates. The
practical implication is that stratified sampling produces more precise
estimates (i.e. the standard error is smaller). Stratified sampling may also
allow a reduction of the total sampling units. However, the advantage of this approach is
realized only if the stratification is done properly. For surveying logged-over
forests, the ability to stratify is very useful. In this study, the
stratification is carried out with the help of satellite data and the strata
are classified based on tree densities.
For
the development of a rapid appraisal technique the stratified sampling design
is the most practical. It minimizes costs by localizing inventory samples. The
stratification of the forest area is undertaken based on recent satellite
images. The timing of the last logging entry could also be used as a
stratification criterion. This approach has been adopted for logged-over
forests by the Forestry Department Peninsular Malaysia in its national forest
inventory. In this study, the condition of the forest was highly variable and
appeared to depend more on the quality of the logging operations than on the
timing of the last logging entry.
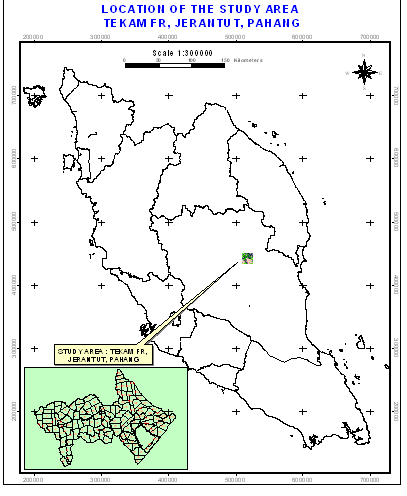
Figure 1. Location of study area
Accessibility within the
logged-over forest is problematic. Therefore, a cluster sampling approach was
adopted to reduce travelling time. In such an approach several plots are
located close to each other to form a sampling unit. Each cluster forms a group
of secondary plots at each location. The unit of observation is not the
individual secondary plots but the entire cluster. In cluster sampling, the first
stage is a selection of primary points rather than finite sampling unit areas.
The second stage is a cluster of sample plots centered on the primary point,
laid out in a pre-determined format.
Table 2. Compartments within the study area showing years after logging
and extent
|
Compartment |
Year since logging (years) |
Size (ha) |
|
75 |
22 |
325.077 |
|
77 |
22 |
230.870 |
|
79 |
25 |
433.444 |
|
81 |
25 |
316.174 |
|
82 |
25 |
209.482 |
|
97 |
25 |
290.275 |
|
98 |
25 |
224.452 |
|
99 |
18 |
217.427 |
|
100 |
18 |
226.375 |
|
118 |
17 |
270.231 |
|
119 |
17 |
409.571 |
|
120 |
15 |
407.207 |
|
121 |
17 |
349.329 |
|
122 |
18 |
192.442 |
|
123 |
18 |
402.613 |
|
124 |
15 |
240.829 |
|
125 |
15 |
228.879 |
|
126 |
15 |
243.230 |
|
127 |
15 |
310.859 |
|
128 |
18 |
315.257 |
|
129 |
18 |
231.012 |
|
130 |
25 |
348.614 |
|
131 |
25 |
367.580 |
|
132 |
25 |
291.443 |
|
133 |
18 |
174.723 |
|
134 |
18 |
385.079 |
|
135 |
19 |
372.667 |
|
Portions of other
compartments |
3 790 |
|
|
Total |
11 805 |
|
To overcome bias, plots are established at the intersection of 1-km grids.
For a rapid appraisal the plots are located in the vicinity of accessible
roads. Each cluster is considered a sampling unit and consists of five plots.
The centre plot of the cluster is located at the grid intersection while the
other four plots are located at a distance of 100 m to the north, east, south
and west (Figure 2). Thus the effective size of the sampling unit is 100 x
100 m or 1 ha.
The
number of plots depends on the desired level of accuracy. It is also influenced
by the availability of funds, which in turn depends to some degree on the
estimated value of the forest stand. Usually, more valuable stands are sampled
more intensively. In most forest inventory operations the probability level is
accepted at 95 percent. The accepted standard error (SE%) for volume estimates
of production forests can vary from 10 to 20 percent depending on the forest
types and stand conditions. For Peninsular Malaysia, the SE% for national and
management unit inventories is 15 percent for areas logged more then 20 years
ago. For areas logged less then 20 years ago, the SE% is 20 percent. Based on
the formula below, the number of samples for various strata as adopted by the
Forestry Department Peninsular Malaysia is shown in Table 3.
ni = t2 * (CVi%2)/(SEi%2)
ni = total number of plots for stratum
i
t = value on a confidence (probability) level of 95%
2
CVi% = coefficient of variation of stratum
i
SEi% = standard error
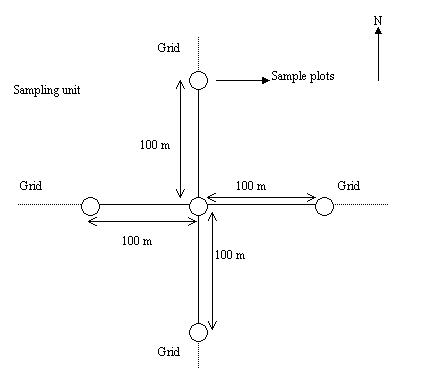
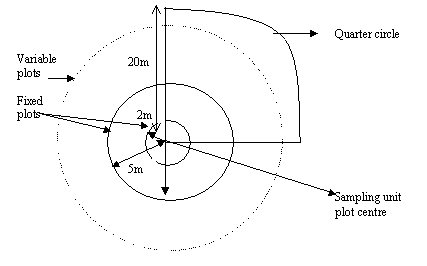
Figure
2. Layout of the sampling unit and plot
layout
Table 3. Number of sample units per stratum at state and
national levels
|
Forest type |
Stratum |
Statistics |
No. of units
per state |
||
|
Name |
No. |
CV% |
SE% |
||
|
Dipterocarp |
Virgin forest – good to superior |
11 |
30 |
15 |
16 |
|
production |
Virgin forest – poor to moderate |
12 |
45 |
15 |
36 |
|
forest |
Logged-over 1-10 years ago |
20 |
50 |
20 |
25 |
|
Logged-over 11-20 years ago |
21 |
45 |
20 |
20 |
|
|
Logged-over 21-30 years ago |
22 |
40 |
15 |
28 |
|
|
Logged-over 31-40 years ago |
23 |
35 |
15 |
22 |
|
|
Logged-over 41+ years ago |
24 |
35 |
15 |
22 |
|
Estimating the sample size required for estimating population based on a two-stage
sampling design requires reliable estimates for both the primary sampling
units (i.e. the forest strata) and the secondary units (i.e. plots within
each stratum). In most situations, this information is unavailable before
the inventory (Shiver and Borders 1996). It is possible to use the information
from the previous national forest inventories as a guide but it may not be
accurate because of the changes and variability between different logged-over
forest stands. However, in general it is the variation between the forest
strata (primary sampling units) that is much greater than the variation between
plots of each stratum (secondary sampling units). Consequently, as the number
of plots is limited, the aim should be to distribute the plots to all the
strata proportionally.
The management unit for
Peninsular Malaysia is the state. Following the stratification by years since
logging, the study area has two strata, namely logged-over (11 to 10 years) and
logged-over (21 to 30 years). The total number of sampling units required based
on the CV for these classes obtained from the Third National Inventory
undertaken in 1991/92 amounts to 48. This information could be used as a guide
but would not be very accurate. However, the study area is much smaller and for
a rapid appraisal the number of plots for each of the classes identified should
be fewer. The calculation of the CV is based on the preliminary inventory
samples and the number of plots is determined for each class. This is
undertaken after the collection of data in the field. At the same time the
stratification is not based on years after logging but on tree density of the
residual stands (see “classification”, below).
