![]()
![]()
![]()
The exercises are numbered according to the numbers of the relevant sections of the manual.
Exercise 2.1 Mean value and variance
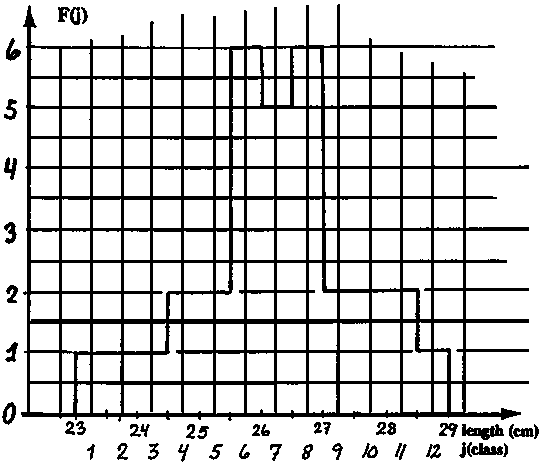
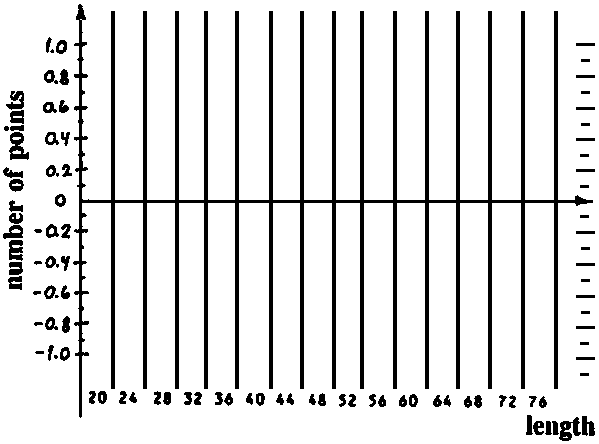
In this exercise we use part of the length-frequency data of the coral trout (Plectropomus leopardus) presented in Fig. 3.4.0.2, namely those in the length interval 23-29 cm. These fish are assumed to belong to one cohort. The length-frequencies are presented in Fig. 17.2.1.
Tasks:
Read the frequencies, F(j) from Fig. 17.2.1 and complete the worksheet. Calculate mean, variance and standard deviation.
Worksheet 2.1
|
j |
L(j) - L(j) + dL |
F(j) |
|
F(j) * |
|
F(j) * ( |
|
1 |
- |
|
|
|
-2.968 |
|
|
2 |
- |
|
|
|
-2.468 |
|
|
3 |
- |
|
|
|
-1.968 |
|
|
4 |
- |
|
|
|
-1.468 |
|
|
5 |
- |
|
|
|
-0.968 |
|
|
6 |
- |
|
|
|
-0.468 |
|
|
7 |
- |
|
|
|
0.032 |
|
|
8 |
26.5-27.0 |
6 |
26.75 |
160.50 |
0.532 |
1.698 |
|
9 |
27.0-27.5 |
2 |
|
54.50 |
1.032 |
2.130 |
|
10 |
27.5-28.0 |
2 |
|
55. 50 |
1.532 |
4.694 |
|
11 |
28.5-29.0 |
2 |
|
56.50 |
2.032 |
8.258 |
|
12 |
|
1 |
|
28.75 |
2.532 |
6.411 |
|
sums |
|
S F(j) |
|
|
|
|
|
|
s2 = |
s = |
||||
Fig. 17.2.1 Length-frequency sample
Exercise 2.2 The normal distribution
This exercise consists of fitting a normal distribution to the length-frequency sample of Exercise 2.1, by using the expression:
(Eq. 2.2.1)
for a sufficient number of x-values allowing you to draw the bell-shaped curve.
For your convenience introduce the auxiliary symbols:
so that the formula above can be written
Since A and B do not depend on L and as they are going to be used many times, it is convenient to calculate them separately before-hand.
Tasks:
1) Calculate A and B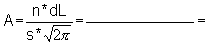
B = -1/(2s2) =
2) Calculate Fc(x) for the following values of x:
Worksheet 2.2
|
x |
Fc(x) |
x |
Fc(x) |
|
22.0 |
|
26.0 |
|
|
22.5 |
|
26.5 |
|
|
23.0 |
|
27.0 |
|
|
23.5 |
|
27.5 |
|
|
24.0 |
|
28.0 |
|
|
24.5 |
|
28.5 |
|
|
25.0 |
|
29.0 |
|
|
25.5 |
|
29.5 |
|
3) Draw the bell-shaped curve on Fig. 17.2.1
Exercise 2.3 Confidence limits
Tasks:
Calculate the 95% confidence interval for the mean value estimated in Exercise 2.1.
Exercise 2.4 Ordinary linear regression analysis
It is often observed that the more boats participate in a fishery the lower the catch per boat will be. This is not surprising when one considers the fish stock as a limited resource which all boats have to share. In Chapter 9 we shall deal with the fisheries theory behind this model.
The data shown below in the worksheet are from the Pakistan shrimp fishery (Van Zalinge and Sparre, 1986).
Tasks:
1) Draw the scatter diagram.
2) Calculate intercept and slope (use the worksheet).
3) Draw the regression line in the scatter diagram.
4) Calculate the 95% confidence limits of a and b.
Worksheet 2.4
|
|
|
number of boats |
|
catch per boat per year |
|
|
|
year |
i |
x(i) |
x(i)2 |
y(i) |
y(i)2 |
x(i) * y(i) |
|
1971 |
1 |
456 |
|
43.5 |
|
19836.0 |
|
1972 |
2 |
536 |
|
44.6 |
|
23905.6 |
|
1973 |
3 |
554 |
|
38.4 |
|
21273.6 |
|
1974 |
4 |
675 |
|
23.8 |
|
16065.0 |
|
1975 |
5 |
702 |
|
25.2 |
|
17690.4 |
|
1976 |
6 |
730 |
532900 |
30.5 |
930.25 |
|
|
1977 |
7 |
750 |
562500 |
27.4 |
750.76 |
|
|
1978 |
8 |
918 |
842724 |
21.1 |
445.21 |
|
|
1979 |
9 |
928 |
861184 |
26.1 |
681.21 |
|
|
1980 |
10 |
897 |
804609 |
28.9 |
835.21 |
|
|
Total |
|
7146 |
|
309.5 |
|
211099.5 |
|
|
|
|||||
|
|
|
|||||
|
|
|
|||||
|
|
||||||
|
|
sx = |
|||||
|
|
sy = |
|||||
|
|
||||||
|
slope: |
intercept: |
|||||
|
variance of b: |
||||||
|
|
sb = |
|||||
|
variance of a: |
||||||
|
|
sa = |
|||||
|
Student's distribution: tn-2 = |
||||||
Exercise 2.5 The correlation coefficient
Refer to Exercise 2.4. Does the correlation coefficient make sense in the example of catch per boat regressed on number of boats? Consider which of the variables is the natural candidate as independent variable. Can we (in principle) decide in advance on the values of one of them?
Tasks:
Irrespective of your findings in the first part of the exercise carry out the calculation of the 95% confidence limits of r.
Exercise 2.6 Linear transformations of normal distributions, used as a tool to separate two overlapping normal distributions (the Bhattacharya method)
Fig. 17.2.6A shows a frequency distribution which is the result of two overlapping normal distributions "a" and "b". We assume that the length-frequencies presented in Fig. 17.2.6B are also a combination of two normal distributions. The aim of the exercise is to separate these two components. The total sample size is 398. Assume that each component has 50% of the total or 199. Further assume that the frequencies at the left somewhat below the top are fully representative for component "a", while those at the bottom of the right side are fully representative for component "b".
Fig. 17.2.6A Combined distribution of two overlapping normal distributions
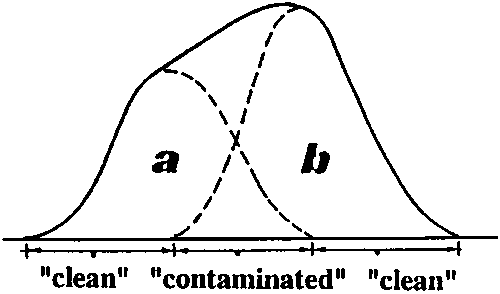
Fig. 17.2.6B Length-frequency sample (assumed to consist of two normal distributions
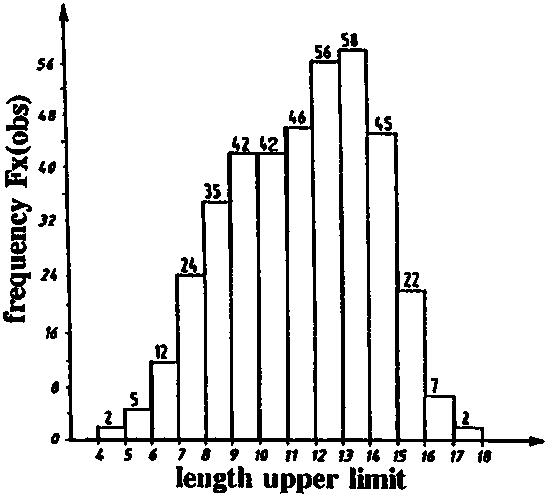
Tasks:
1) Complete Worksheet 2.6a.2) Plot D ln F(z) = y' against x + dL/2 = z and decide which points lie on straight lines with negative slopes (see Fig. 2.6.5).
3) On the basis of the plot select the points to be used for the linear regressions. (Avoid the area of overlap and points based on very few observations). Do the two linear regressions and determine a and b.
4) Calculate
, s2 = -1/b and s = Ö s2 for each component.
5) Draw the two plots which represent each distribution in linear form.
6) We now want to convert the straight lines into the corresponding theoretical (calculated) normal distributions. Using Eq. 2.2.1 calculate Fc(x) for both normal distributions for a sufficient number of x-values to allow you to draw the two bell-shaped curves superimposed on Fig. 17.2.6B. Assume n = 199 for both components. (Use the same method as presented in Exercise 2.2). Complete Worksheet 2.6b.
Worksheet 2.6a
|
interval |
x |
F(x) |
ln F(x) |
D ln F(z) |
z = x + dL/2 |
|
4-5 |
4.5 |
2 |
0.693 |
|
|
|
|
|
|
|
0.916 |
5 |
|
5-6 |
5.5 |
5 |
1.609 |
|
|
|
|
|
|
|
0.875 |
6 |
|
6-7 |
6.5 |
12 |
|
|
|
|
|
|
|
|
|
7 |
|
7-8 |
7.5 |
24 |
|
|
|
|
|
|
|
|
|
|
|
8-9 |
8.5 |
35 |
|
|
|
|
|
|
|
|
|
|
|
9-10 |
9.5 |
42 |
|
|
|
|
|
|
|
|
|
|
|
10-11 |
10. 5 |
42 |
|
|
|
|
|
|
|
|
|
|
|
11-12 |
11.5 |
46 |
|
|
|
|
|
|
|
|
|
|
|
12-13 |
12.5 |
56 |
|
|
|
|
|
|
|
|
|
|
|
13-14 |
13.5 |
58 |
|
|
|
|
|
|
|
|
|
|
|
14-15 |
14.5 |
45 |
|
|
|
|
|
|
|
|
|
|
|
15-16 |
15.5 |
22 |
3.091 |
|
|
|
|
|
|
|
-1.145 |
16 |
|
16-17 |
16.5 |
7 |
1.946 |
|
|
|
|
|
|
|
-1.253 |
17 |
|
17-18 |
17.5 |
2 |
0.693 |
|
|
Worksheet 2.6b
|
First component |
Second component |
||||
|
|
|
||||
|
B = |
B = |
||||
|
|
|
||||
|
|
|||||
|
x |
Fc(x) |
Fc(x) |
x |
Fc(x) |
Fc(x) |
|
1.5 |
|
|
11.5 |
|
|
|
2.5 |
|
|
12.5 |
|
|
|
3.5 |
|
|
13.5 |
|
|
|
4.5 |
|
|
14.5 |
|
|
|
5.5 |
|
|
15.5 |
|
|
|
6.5 |
|
|
16.5 |
|
|
|
7.5 |
|
|
17.5 |
|
|
|
8.5 |
|
|
18.5 |
|
|
|
9.5 |
|
|
19.5 |
|
|
|
10.5 |
|
|
20.5 |
|
|
Exercise 3.1 The von Bertalanffy growth equation
The growth parameters of the Malabar blood snapper (Lutjanus malabaricus) in the Arafura Sea were reported by Edwards (1985) as:
K = 0.168 per year
L¥ = 70.7 cm (standard length)
t0 = 0.418 years
Edwards also estimated the standard length/weight relationship for Lutjanus malabaricus:
w = 0.041 * L2.842 (weight in g and standard length in cm)
as well as the relationship between standard length (S.L.) and total length (T.L.):
T.L. = 0.21 + 1.18 * S.L.
Tasks:
Complete the worksheet and draw the following three curves:1) Standard length as a function of age
2) Total length as a function of age
3) Weight as a function of age
Worksheet 3.1
|
age |
standard length |
total length |
body weight |
age |
standard length |
total length |
body weight |
|
years |
cm |
cm |
g |
years |
cm |
cm |
g |
|
0.5 |
|
|
|
8 |
|
|
|
|
1.0 |
|
|
|
9 |
|
|
|
|
1.5 |
|
|
|
10 |
|
|
|
|
2 |
|
|
|
12 |
|
|
|
|
3 |
|
|
|
14 |
|
|
|
|
4 |
|
|
|
16 |
|
|
|
|
5 |
|
|
|
(do not use ages above 16 in the graph) |
|||
|
6 |
|
|
|
|
|
|
|
|
7 |
|
|
|
20 |
|
|
|
|
|
|
|
|
50 |
|
|
|
Exercise 3.1.2 The weight-based von Bertalanffy growth equation
Pauly (1980) determined the following parameters for the pony fish or slipmouth (Leiognathus splendens) from western Indonesia:
L¥ = 14 cm
q = 0.02332
K = 1.0 per year
t0 = -0.2 year
Tasks:
Complete the worksheet and draw the length and the weight-converted von Bertalanffy growth curves.
Worksheet 3.1.2
|
age |
length |
weight |
age |
length |
weight |
|
0 |
|
|
0.9 |
|
|
|
0.1 |
|
|
1.0 |
|
|
|
0.2 |
|
|
1.2 |
|
|
|
0.3 |
|
|
1.4 |
|
|
|
0.4 |
|
|
1.6 |
|
|
|
0.5 |
|
|
1.8 |
|
|
|
0.6 |
|
|
2.0 |
|
|
|
0.7 |
|
|
2.5 |
|
|
|
0.8 |
|
|
3.0 |
|
|
Exercise 3.2.1 Data from age readings and length compositions (age/length key)
Consider Table 3.2.1.1 (age/length key) and suppose we caught a total of 2400 fish of the species in question during the cruise from which this age/length key was obtained and that only 439 specimens of Table 3.2.1.1 were aged. The remaining fish were all measured for length. To reduce the computational work of the exercise only a part (386 fish) of this length-frequency sample is used. This part is shown in the worksheet.
Tasks:
Estimate how many of these 386 fish belonged to each of the four cohorts listed in Table 3.2.1.1, by completing the worksheet.
Worksheet 3.2.1
|
cohort |
1982 |
1981 |
1981 |
1980 |
|
1982 |
1981 |
1981 |
1980 |
|
length interval |
key |
number in length sample |
numbers per cohort |
||||||
|
35-36 |
0.800 |
0.200 |
0 |
0 |
53 |
42.4 |
10.6 |
0 |
0 |
|
36-37 |
0.636 |
0.273 |
0.091 |
0 |
61 |
38.8 |
16.7 |
5.6 |
0 |
|
37-38 |
|
|
|
|
49 |
|
|
|
|
|
38-39 |
|
|
|
|
52 |
|
|
|
|
|
39-40 |
|
|
|
|
70 |
|
|
|
|
|
40-41 |
|
|
|
|
52 |
|
|
|
|
|
41-42 |
0.222 |
0.444 |
0.222 |
0.111 |
49 |
10.9 |
21.8 |
10.0 |
5.4 |
|
|
|
|
|
total |
386 |
187.2. |
133.8 |
|
|
Exercise 3.3.1 The Gulland and Holt plot
Randall (1962) tagged, released and recaptured ocean surgeon fish (Acanthurus bahianus) near the Virgin Islands. Data of 11 of the recaptured fish are shown in the worksheet, in the form of their length at release (column B) and at recapture (column C) and the length of the time between release and recapture (column D).
Tasks:
1) Estimate K and L for the ocean surgeon fish using the Gulland and Holt plot.
2) Calculate the 95% confidence limits of the estimate of K.
Worksheet 3.3.1
|
A |
B |
C |
D |
E |
F |
|
fish |
L(t) |
L(t + D t) |
D t |
|
|
|
|
cm |
cm |
days |
cm/year |
cm |
|
|
|
|
|
(y) |
(x) |
|
1 |
9.7 |
10.2 |
53 |
|
|
|
2 |
10.5 |
10.9 |
33 |
|
|
|
3 |
10.9 |
11.8 |
108 |
|
|
|
4 |
11.1 |
12.0 |
102 |
|
|
|
5 |
12.4 |
15.5 |
272 |
|
|
|
6 |
12.8 |
13.6 |
48 |
|
|
|
7 |
14.0 |
14.3 |
53 |
|
|
|
8 |
16.1 |
16.4 |
73 |
|
|
|
9 |
16.3 |
16.5 |
63 |
|
|
|
10 |
17.0 |
17.2 |
106 |
|
|
|
11 |
17.7 |
18.0 |
111 |
|
|
|
a (intercept) = |
b (slope) = |
||||
|
K = |
L¥ = |
||||
|
|
|||||
|
sb = |
tn-2 = |
||||
|
confidence interval of K = |
|||||
Exercise 3.3.2 The Ford-Walford plot and Chapman's method
Postel (1955) reports the following length/age relationship for Atlantic yellowfin tuna (Thunnus albacares) off Senegal:
|
age |
fork length |
|
1 |
35 |
|
2 |
55 |
|
3 |
75 |
|
4 |
90 |
|
5 |
105 |
|
6 |
115 |
Tasks:
Estimate K and L¥ using the Ford-Walford plot and Chapman's method.
Worksheet 3.3.2
|
Plot |
FORD-WALFORD |
CHAPMAN |
||
|
t |
L(t) |
L(t + D t) |
L(t) |
L(t + D t) - L(t) |
|
1 |
|
|
|
|
|
2 |
|
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
|
5 |
|
|
|
|
|
a (intercept) |
|
|
|
|
|
b (slope) |
|
|
|
|
|
|
|
|
|
|
|
tn-2 |
|
|
|
|
|
confidence limits of b |
|
|
|
|
|
K |
|
|
|
|
|
L¥ |
|
|
|
|
Exercise 3.3.3 The von Bertalanffy plot
Cassie (1954) presented the length-frequency sample of 256 seabreams (Chrysophrys auratus) shown in the figure. He resolved this sample into normally distributed components (similar to Fig. 3.2.2.2) using the Cassie method (cf. Section 3.4.3) and found the following mean lengths for four age groups (cf. Fig. 17.3.3.3):
|
A |
B |
C |
D |
|
age group |
mean length |
D L/D t |
|
|
0 |
3.22 |
|
|
|
|
|
2.11 |
4.28 |
|
1 |
5.33 |
|
|
|
|
|
2.29 |
6.48 |
|
2 |
7.62 |
|
|
|
|
|
2.12 |
8.68 |
|
3 |
9.74 |
|
|
Note: a Gulland and Holt plot gives (cf. Columns C and D): K = -0.002 and L¥ = -950 inches, which makes no sense whatsoever.
Tasks:
1) Estimate K from the von Bertalanffy plot.
2) Why does it not make sense to ask you to estimate t0?
Exercise 3.4.1 Bhattacharya's method
Weber and Jothy (1977) presented the length-frequency sample of 1069 threadfin breams (Nemipterus nematophorus) shown in Fig. 17.3.4.1A. These fish were caught during a survey from 29 March to 1 May 1972, in the South China Sea bordering Sarawak. The lengths measured are total lengths from the snout to the tip of the lower lobe of the caudal fin.
Figs. 17.3.4.1B and 17.3.4.1C show the Bhattacharya plots for the data in Fig. 17.3.4.1A, where B is based on the original data in 5 mm length intervals and C on the same data regrouped in 1 cm intervals. You should proceed with Fig. C for two reasons: 1) because it appears easier to see a structure in Fig. C than in Fig. B and 2) because the number of calculations is much lower.
Tasks:
1) Resolve the length-frequency sample (1 cm groups, Fig. C) into normally distributed components and estimate thereby mean length and standard deviations for each component. Use the four worksheets and plot the regression lines.2) Estimate L¥ and K using a Gulland and Holt plot. Draw the plot.
3) Do you think the analysis could have been improved by using Fig. B (5 mm length groups) instead of Fig. C (1 cm groups)?
Fig. 17.3.4.1A Length-frequency sample of threadfin breams. Data source: Weber and Jothy, 1977
Worksheet 3.4.1a
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
length interval |
N1+ |
ln N1+ |
D ln N1+ |
L |
D ln N1 |
ln N1 |
N1 |
N2+ |
|
5.75-6.75 |
1 |
0 |
- |
- |
- |
- |
1 |
0 |
|
6.75-7.75 |
26 |
3.258 |
(3.258) |
6.75 |
1.262 |
- |
26 |
0 |
|
7.75-8.75 |
42# |
3.738# |
0.480 |
7.75 |
0.354 |
3.738# |
42# |
0 |
|
8.75-9.75 |
19 |
2.944 |
-0.793 |
8.75 |
-0.554 |
3.183 |
19 |
0 |
|
9.75-10.75 |
5 |
|
|
9.75 |
|
|
|
|
|
10.75-11.75 |
15 |
|
|
10.75 |
|
|
|
|
|
11.75-12.75 |
41 |
|
|
11.75 |
|
|
|
|
|
12.75-13.75 |
125 |
|
|
12.75 |
|
|
|
|
|
13.75-14.75 |
135 |
|
|
13.75 |
|
|
|
|
|
14.75-15.75 |
102 |
|
|
14.75 |
|
|
|
|
|
15.75-16.75 |
131 |
|
|
15.75 |
|
|
|
|
|
16.75-17.75 |
106 |
|
|
16.75 |
|
|
|
|
|
17.75-18.75 |
86 |
|
|
17.75 |
|
|
|
|
|
18.75-19.75 |
59 |
|
|
18.75 |
|
|
|
|
|
19.75-20.75 |
43 |
|
|
19.75 |
|
|
|
|
|
20.75-21.75 |
45 |
|
|
20.75 |
|
|
|
|
|
21.75-22.75 |
56 |
|
|
21.75 |
|
|
|
|
|
22.75-23.75 |
20 |
|
|
22.75 |
|
|
|
|
|
23.75-24.75 |
8 |
|
|
23.75 |
|
|
|
|
|
24.75-25.75 |
3 |
|
|
24.75 |
|
|
|
|
|
25.75-26.75 |
1 |
|
|
25.75 |
|
|
|
|
|
Total |
1069 |
|
|
|
|
|
|
|
|
a (intercept) = |
b (slope) = | |||||||
|
|
| |||||||
Worksheet 3.4.1b
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
interval |
N2+ |
ln N2+ |
D ln N2+ |
L |
D ln N2 |
ln N2 |
N2 |
N3+ |
|
5.75-6.75 |
|
|
|
|
|
|
|
|
|
6.75-7.75 |
|
|
|
6.75 |
|
|
|
|
|
7.75-8.75 |
|
|
|
7. 75 |
|
|
|
|
|
8.75-9.75 |
|
|
|
8.75 |
|
|
|
|
|
9.75-10.75 |
|
|
|
9.75 |
|
|
|
|
|
10.75-11.75 |
|
|
|
10.75 |
|
|
|
|
|
11.75-12.75 |
|
|
|
11.75 |
|
|
|
|
|
12.75-13.75 |
|
|
|
12.75 |
|
|
|
|
|
13.75-14.75 |
|
|
|
13.75 |
|
|
|
|
|
14.75-15.75 |
|
|
|
14.75 |
|
|
|
|
|
15.75-16.75 |
|
|
|
15.75 |
|
|
|
|
|
16.75-17.75 |
|
|
|
16.75 |
|
|
|
|
|
17.75-18.75 |
|
|
|
17.75 |
|
|
|
|
|
18.75-19.75 |
|
|
|
18.75 |
|
|
|
|
|
19.75-20.75 |
|
|
|
19.75 |
|
|
|
|
|
20.75-21.75 |
|
|
|
20.75 |
|
|
|
|
|
21.75-22.75 |
|
|
|
21.75 |
|
|
|
|
|
22.75-23.75 |
|
|
|
22.75 |
|
|
|
|
|
23.75-24.75 |
|
|
|
23.75 |
|
|
|
|
|
24.75-25.75 |
|
|
|
24.75 |
|
|
|
|
|
25.75-26.75 |
|
|
|
25.75 |
|
|
|
|
|
Total |
|
|
|
|
|
|
|
|
|
a (intercept) = |
b (slope) = | |||||||
|
|
| |||||||
Worksheet 3.4.1c
|
A |
B |
C |
D |
E |
P |
G |
H |
I |
|
interval |
N3+ |
ln N3+ |
D ln N3+ |
L |
D ln N3 |
ln N3 |
N3 |
N4+ |
|
5.75-6.75 |
|
|
|
|
|
|
|
|
|
6.75-7.75 |
|
|
|
6.75 |
|
|
|
|
|
7.75-8.75 |
|
|
|
7.75 |
|
|
|
|
|
8.75-9.75 |
|
|
|
8.75 |
|
|
|
|
|
9.75-10.75 |
|
|
|
9.75 |
|
|
|
|
|
10.75-11.75 |
|
|
|
10.75 |
|
|
|
|
|
11.75-12.75 |
|
|
|
11.75 |
|
|
|
|
|
12.75-13.75 |
|
|
|
12.75 |
|
|
|
|
|
13.75-14.75 |
|
|
|
13.75 |
|
|
|
|
|
14.75-15.75 |
|
|
|
14.75 |
|
|
|
|
|
15.75-16.75 |
|
|
|
15.75 |
|
|
|
|
|
16.75-17.75 |
|
|
|
16.75 |
|
|
|
|
|
17.75-18.75 |
|
|
|
17.75 |
|
|
|
|
|
18.75-19.75 |
|
|
|
18.75 |
|
|
|
|
|
19.75-20.75 |
|
|
|
19.75 |
|
|
|
|
|
20.75-21.75 |
|
|
|
20.75 |
|
|
|
|
|
21.75-22.75 |
|
|
|
21.75 |
|
|
|
|
|
22.75-23.75 |
|
|
|
22.75 |
|
|
|
|
|
23.75-24.75 |
|
|
|
23.75 |
|
|
|
|
|
24.75-25.75 |
|
|
|
24.75 |
|
|
|
|
|
25.75-26.75 |
|
|
|
25.75 |
|
|
|
|
|
Total |
|
|
|
|
|
|
|
|
|
a (intercept) = |
b (slope) = | |||||||
|
|
| |||||||
Worksheet 3.4.1d
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
interval |
N4+ |
ln N4+ |
D ln N4+ |
L |
D ln N4 |
ln N4 |
N4 |
N5+ |
|
5.75-6.75 |
|
|
|
- |
|
|
|
|
|
6.75-7.75 |
|
|
|
6.75 |
|
|
|
|
|
7.75-8.75 |
|
|
|
7.75 |
|
|
|
|
|
8.75-9.75 |
|
|
|
8.75 |
|
|
|
|
|
9.75-10.75 |
|
|
|
9.75 |
|
|
|
|
|
10.75-11.75 |
|
|
|
10.75 |
|
|
|
|
|
11.75-12.75 |
|
|
|
11.75 |
|
|
|
|
|
12.75-13.75 |
|
|
|
12.75 |
|
|
|
|
|
13.75-14.75 |
|
|
|
13.75 |
|
|
|
|
|
14.75-15.75 |
|
|
|
14.75 |
|
|
|
|
|
15.75-16.75 |
|
|
|
15.75 |
|
|
|
|
|
16.75-17.75 |
|
|
|
16.75 |
|
|
|
|
|
17.75-18.75 |
|
|
|
17.75 |
|
|
|
|
|
18.75-19.75 |
|
|
|
18.75 |
|
|
|
|
|
19.75-20.75 |
|
|
|
19.75 |
|
|
|
|
|
20.75-21.75 |
|
|
|
20.75 |
|
|
|
|
|
21.75-22.75 |
|
|
|
21.75 |
|
|
|
|
|
22.75-23.75 |
|
|
|
22.75 |
|
|
|
|
|
23.75-24.75 |
|
|
|
23.75 |
|
|
|
|
|
24.75-25.75 |
|
|
|
24.75 |
|
|
|
|
|
25.75-26.75 |
|
|
|
25.75 |
|
|
|
|
|
Total |
|
|
|
|
|
|
|
|
|
a (intercept) = |
b (slope) = | |||||||
|
|
| |||||||
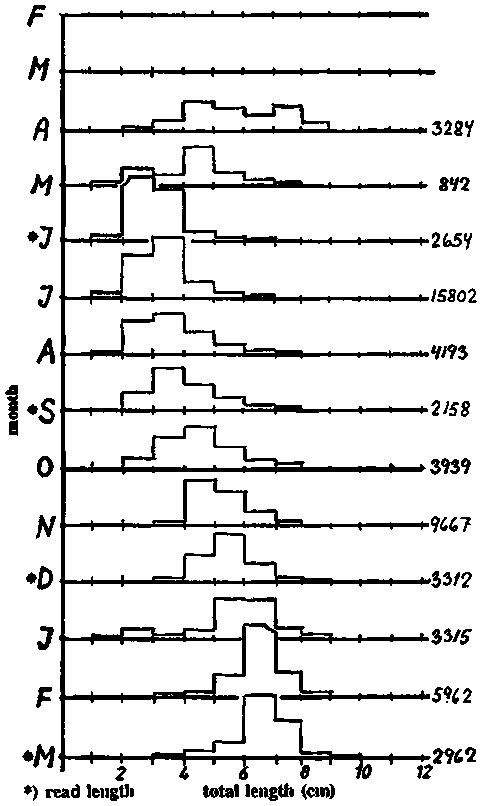
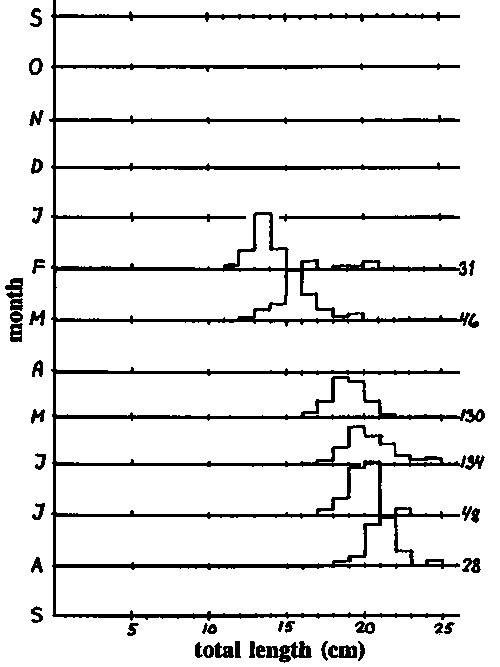
Exercise 3.4.2 Modal progression analysis
Fig. 17.3.4.2A shows a time series over twelve months of ponyfish (Leiognathus splendens) from Manila Bay, Philippines, 1957-58. (Data from Tiews and Caces-Borja, 1965; figure redrawn from Ingles and Pauly, 1984). The numbers at the right hand side of the bar diagram indicate the sample sizes, while the height of the bars represents the percentages of the total number per length group.
Fig. 17.3.4.2B shows a time series of six samples of mackerel, (Rastrelliger kanagurta) from Palawan, Philippines, 1965. (Data from Research Division, BFAR, Manila; figure redrawn from Ingles and Pauly, 1984).
Tasks:
1) Fit by eye growth curves to these two time series, trying to follow the modal progression (as was done in Fig. 3.4.2.6). Start by fitting a straight line and then add some curvature to it, but do not be too particular about it. (Actually one should have carried out a Bhattacharya or similar analysis for each sample, but because of the amount of work involved in that approach, we take the easier, but less dependable, eye-fit. This exercise aims at illustrating only the principles of modal progression analysis - not the exact procedure).2) Read from the eye-fitted growth curves pairs of (t, L) = (time of sampling, length), and use the Gulland and Holt plot to estimate K and L¥ . Assume that the samples were taken on the first day of the month. Read for Leiognathus splendens only the length for the samples indicated by "*" in Fig. A, as the figure is too small for a precise reading of each month. Use the worksheet.
3) Use the von Bertalanffy plot to estimate t0.
Worksheet 3.4.2
A. Leiognathus splendens:
|
|
|
GULLAND AND HOLT PLOT |
VON BERTALANFFY PLOT |
||
|
time of sampling |
L(t) |
D L/D t |
|
t |
- ln (1 - L/L¥ ) |
|
1 June |
|
|
|
|
|
|
1 Sep. |
|
|
|
|
|
|
1 Dec. |
|
|
|
|
|
|
1 March |
|
|
|
|
|
|
a (intercept) |
|
|
|||
|
(slope, -K or K) |
L¥ = - a/b = |
t0 = - a/b = |
|||
|
L(t) = ___________ [1 - exp (- _______ (t - _________ ))] |
|||||
Fig. 17.3.4.2A Time series of length-frequencies of ponyfish. Data source: Tiews and Caces-Borja, 1965
B. Rastrelliger kanagurta:
|
|
|
GULLAND AND HOLT PLOT |
VON BERTALANFFY PLOT |
||
|
time of sampling |
L(t) |
D L/D t |
|
t |
- ln (1 - L/L¥ ) |
|
1 Feb |
|
|
|
|
|
|
1 March |
|
|
|
|
|
|
1 May |
|
|
|
|
|
|
1 June |
|
|
|
|
|
|
1 July |
|
|
|
|
|
|
1 August |
|
|
|
|
|
|
a (intercept) |
|
|
|||
|
(slope, -K or K) |
L¥ = - a/b = |
t0 = - a/b = |
|||
|
L(t) = ___________ [1 - exp (- _______ (t - _________ ))] |
|||||
Fig. 17.3.4.2B Time series of length-frequencies of Indian mackerel. Data source: BFAR, Manila
Exercise 3.5.1 ELEFAN I
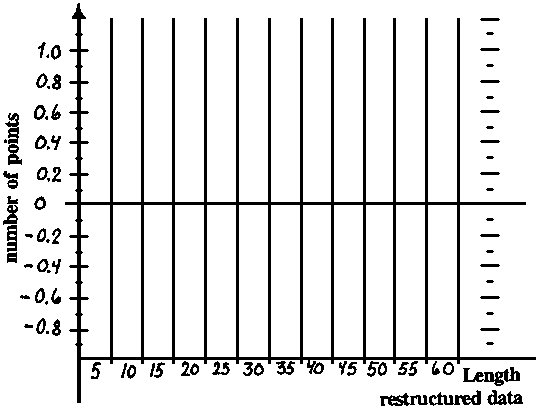
This exercise aims at explaining the details of the length-frequency restructuring process. Fig. 17.3.5.1A shows a (hypothetical) length-frequency sample, where the line shows the moving average. The worksheet table shows the calculation procedure and some results. Further explanations are given below for each step of the procedure.
Tasks:
1) Fill in the missing figures in the worksheet table.
2) Draw the bar diagram of the restructured data on the worksheet figure (B).
Worksheet 3.5.1
|
RESTRUCTURING OF LENGTH FREQUENCY SAMPLE | ||||||||
|
|
|
STEP |
STEP |
STEP |
STEP |
STEP |
STEP |
STEP |
|
mid-length |
orig. freq. |
MA (L) |
FRQ/MA |
|
zeroes |
de-emphasized |
points |
highest positive points |
|
5 |
4 |
4.6 a) |
0.870 |
- 0.197 h) |
2 |
-0.197 |
-0.109 p) |
|
|
10 |
13 |
4.6 |
|
|
2 |
0.966 k) |
|
0.966 s) |
|
15 |
6 |
4.8 b) |
1.250 e) |
|
1 |
0.123 l) |
0.123 |
|
|
20 |
0 |
4.0 |
0 |
-1.000 |
1 |
|
0 |
|
|
25 |
1 |
|
0.714 |
-0.341 i) |
3 |
-0.341 |
-0.188 |
|
|
30 |
0 |
0.4 |
0 |
-1.000 |
2 |
|
|
|
|
35 |
0 |
1.0 c) |
0 f) |
|
1 |
-1.000 |
|
|
|
40 |
1 |
|
1.000 |
-0.077 |
2 |
-0.077 |
|
|
|
45 |
3 |
|
|
1.770 j) |
2 |
1.062 m) |
1.062 |
|
|
50 |
1 |
|
|
|
1 |
|
-0.127 q) |
|
|
55 |
0 |
|
0 |
-1.000 |
1 |
-1.000 |
0 r) |
|
|
60 |
1 |
0.4 d) |
|
|
3 |
0.523 n) |
|
|
|
S = |
SP = |
| ||||||
|
(S /12) = M = 1.083 g) |
SN = |
ASP = | ||||||
|
|
- SP/SN = R = 0.552 o) |
| ||||||
Fig. 17.3.5.1A Hypothetical length-frequency sample. Line indicates moving average over 5 neighbours
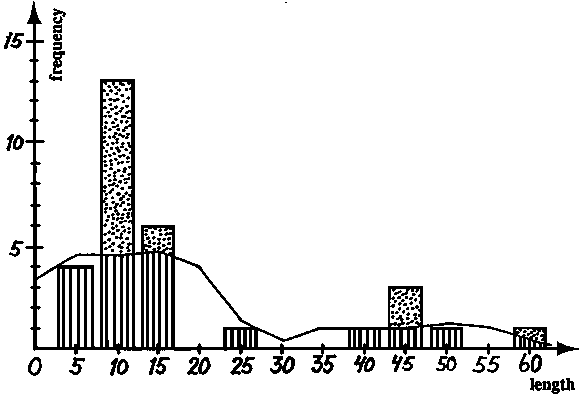
Step 1: Calculate the moving average, MA(L) over 5 neighbours.
Examples: (see Fig. 17.3.5.1 A and worksheet table)MA (5) = (0 + 0 + 4 + 13 + 6)/5 = 4.6 a)
(two zeroes added at start of the sample)MA (15) = (4 + 13 + 6 + 0 + 1)/5 = 4.8 b)
MA (35) = (1 + 0 + 0 + 1 + 3)/5 = 1.0 c)
MA (60) = (1 + 0 + 1 + 0 + 0)/5 = 0.4 d)
Step 2: Divide the original frequencies, FRQ(L), by the moving average (MA) and calculate their mean value, M:
Examples:6/4.8 = 1.25 e)
0/1 = 0 f)
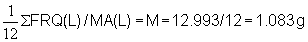 (12 = number of length intervals)
(12 = number of length intervals)
Step 3: Divide FRQ/MA by M and subtract 1
Examples:0.870/1.083 - 1 = -0.197 h)
0.714/1.083 - 1 = -0.341 i)
3.000/1.083 - 1 = 1.770 j)
Step 4a: Count numbers of "zero neighbours" among the four neighbours (two zeroes added to each end of the sample).
Step 4b: De-emphasize positive isolated values: For each "zero-neighbour" the isolated point is reduced by 20%:
and if there are "zero-neighbours" then multiply this value by [1 - 0.2 * (no. of zeroes)]Examples:
1.610 * (1 - 0.2 * 2) = 0.966 k)
0.154 * (1 - 0.2 * 1) = 0.123 l)
1.770 * (1 - 0.2 * 2) = 1.062 m)
1.308 * (1 - 0.2 * 3) = 0.523 n)
Note: In the most recent version (Gayanilo, Soriano and Pauly, 1988) the de-emphasizing has been made more pronounced by using the factor:
Step 4c: Calculate sum, SP, of positive (restructured) FRQs and calculate sum, SN, of negative (restructured) FRQs and calculate the ratio R = - SP/SN
Example:SP = 0.966 + 0.123 + 1.062 + 0.523 = 2.674
SN = -0.197 - 1 - 0.340 - 1 - 1 - 0.076 - 0.230 - 1 = -4.845
R = - SP/SN = 2.674/4.845 = 0.552 o)
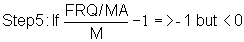
then multiply this value by R. Values > 0 are not changed.Examples:
-0.197 * 0.552 = -0.109 p)
-0.231 * 0.552 = -0.123 q)
FRQ (55) = 0 r)
Plot the points in the diagram (Fig. 17.3.5.1B).
Step 6: Calculate ASP (available sum of peaks). Identify the highest point in each sequence of intervals with positive points (a "sequence" may consist of a single interval)
Examples:0.966 is the highest point in the positive sequence 10-15 cm s)
1.062 is the highest point in the positive sequence 45-45 cm
0.523 is the highest point in the positive sequence 60-60 cmASP = 0.966 + 1.062 + 0.523 = 2.551
Fig. 17.3.5.1B Diagram for plotting points obtained after Step 5 (see text)
Exercise 3.5.1a ELEFAN I, continued
This exercise aims at illustrating the importance of the choice of the size of the length interval (cf. Exercise 3.4.1).
Fig. 17.3.5.1C1 shows a length-frequency sample (from Macdonald and Pitcher, 1979) of 523 pike from Heming Lake, Canada, grouped in 2 cm length intervals. There are five cohorts, determined on the basis of age reading of scales with the mean lengths shown in the following table:
|
age |
mean length |
standard deviation |
|
1 |
23.3 |
2.44 |
|
2 |
33.1 |
3.00 |
|
3 |
41.3 |
4.27 |
|
4 |
51.2 |
5.08 |
|
5 |
61.3 |
7.07 |
These data put us in a position to test ELEFAN I.
Fig. 17.3.5.1C2 shows the normally distributed components derived from scale readings, and Fig. C3 shows the restructured data.
Except for the largest fish ELEFAN I manages to place the ASPs (indicated by arrows) close to where the "true" mean lengths of the cohorts are, but like all other methods ELEFAN I has difficulties in handling the largest (oldest) fish.
Tasks:
Repeat the restructuring using Worksheet 3.5.1a on the basis of 4 cm intervals (see worksheet figure) instead of 2 cm intervals. Compare the results with those presented in Figs. 17.3.5.1C1 and C2.
Fig. 17.3.5.1D Regrouped length-frequency data, 4 cm length intervals (see Fig. 17.3.5.1C)
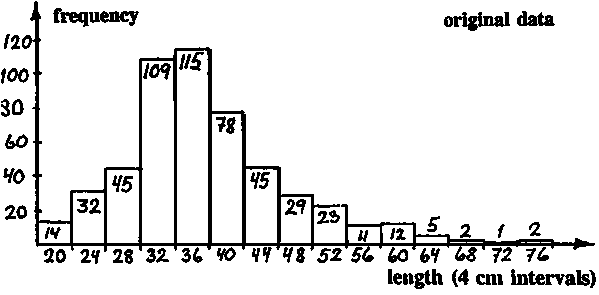
Worksheet 3.5.1a
|
RESTRUCTURING OF LENGTH FREQUENCY SAMPLE | ||||||||
|
|
|
STEP |
STEP |
STEP |
STEP |
STEP |
STEP |
STEP |
|
mid-length |
orig. freq. |
MA(L) |
FRQ/MA |
|
zeroes |
de-emphasized |
points |
highest positive points |
|
20 |
14 |
|
|
|
|
|
|
|
|
24 |
32 |
|
|
|
|
|
|
|
|
28 |
45 |
|
|
|
|
|
|
|
|
32 |
109 |
|
|
|
|
|
|
|
|
36 |
115 |
|
|
|
|
|
|
|
|
40 |
78 |
|
|
|
|
|
|
|
|
44 |
45 |
|
|
|
|
|
|
|
|
48 |
29 |
|
|
|
|
|
|
|
|
52 |
23 |
|
|
|
|
|
|
|
|
56 |
11 |
|
|
|
|
|
|
|
|
60 |
12 |
|
|
|
|
|
|
|
|
64 |
5 |
|
|
|
|
|
|
|
|
68 |
2 |
|
|
|
|
|
|
|
|
72 |
1 |
|
|
|
|
|
|
|
|
76 |
2 |
|
|
|
|
|
|
|
|
S = |
SP = |
| ||||||
|
(S /15) = M = |
SN = |
ASP = | ||||||
|
|
-SP/SN = R = |
| ||||||
Fig. 17.3.5.1E Diagram for plotting points obtained after Step 5 using data from Fig. 17.3.5.1D
Exercise 4.2 The dynamics of a cohort (exponential decay model with variable Z)
Consider a cohort of a demersal fish species recruiting at an age t, which is arbitrarily put to zero. Recruitment is N (0) = 10000.
Tasks:
1) Calculate, using the worksheet, for the first ten half year periods the number of survivors at the beginning of each period and the numbers caught when mortality rates are as shown below:
|
age group |
natural mortality |
fishing mortality |
Comments |
|
t1 - t2 |
M |
F |
|
|
0.0-0.5 |
2.0 |
0.0 |
Cohort still on the nursery ground and exposed to heavy predation due to small size |
|
0.5-1.0 |
1.5 |
0.0 |
|
|
1.0-1.5 |
0.5 |
0.2 |
Cohort under migration to fishing ground. Some fish escape through meshes |
|
1.5-2.0 |
0.3 |
0.4 |
|
|
2.0-2.5 |
0.3 |
0.6 |
Cohort under full exploitation |
|
2.5-3.0 |
0.3 |
0.6 |
|
|
3.0-3.5 |
0.3 |
0.6 |
|
|
3.5-4.0 |
0.3 |
0.6 |
Predation pressure reduced |
|
4.0-4.5 |
0.3 |
0.6 |
|
|
4.5-5.0 |
0.3 |
0.6 |
|
|
Recruitment: N (0) = 10000 | |||
2) Give a graphical presentation of the results.
Worksheet 4.2
|
t1 - t2 |
M |
F |
Z |
e-0.5Z |
N(t1) |
N(t2) |
N(t1) - N(t2) |
F/Z |
C(t1, t2) |
|
0.0-0.5 |
2.0 |
0.0 |
|
|
|
|
|
|
|
|
0.5-1.0 |
1.5 |
0.0 |
|
|
|
|
|
|
|
|
1.0-1.5 |
0.5 |
0.2 |
|
|
|
|
|
|
|
|
1.5-2.0 |
0.3 |
0.4 |
|
|
|
|
|
|
|
|
2.0-2.5 |
0.3 |
0.6 |
|
|
|
|
|
|
|
|
2.5-3.0 |
0.3 |
0.6 |
|
|
|
|
|
|
|
|
3.0-3.5 |
0.3 |
0.6 |
|
|
|
|
|
|
|
|
3.5-4.0 |
0.3 |
0.6 |
|
|
|
|
|
|
|
|
4.0-4.5 |
0.3 |
0.6 |
|
|
|
|
|
|
|
|
4.5-5.0 |
0.3 |
0.6 |
|
|
|
|
|
|
|
Exercise 4.2a The dynamics of a cohort (the formula for average number of survivors, Eq. 4.2.9)
Tasks:
Calculate the average number of survivors during the last 3 years for the cohort dealt with in Exercise 4.2 using the exact expression (Eq. 4.2.9) and the approximation demonstrated in Fig. 4.2.3, i.e. calculate N(2.0, 5.0).
Exercise 4.3 Estimation of Z from CPUE data
Assume that in Table 3.2.1.2 the numbers observed are the numbers caught of each cohort per hour trawling on 15 October 1983.
Tasks:
Estimate the total mortality for the stock under the assumption of constant recruitment, using Eq. 4.3.0.3:
Worksheet 4.3
|
|
|
cohort |
1982 A |
1982 S |
1981 A |
1981 S |
1980 A 1) |
|
age t2 |
1.14 |
1.64 |
2.14 |
2.64 |
3.14 |
||
|
CPUE |
111 |
67 |
40 |
24 |
15 |
||
|
cohort |
age t1 |
CPUE |
|
|
|
|
|
|
1983 S |
0.64 |
182 |
|
|
|
|
|
|
1982 A |
1.14 |
111 |
------ |
|
|
|
|
|
1982 S |
1.64 |
67 |
------ |
------ |
|
|
|
|
1981 A |
2.14 |
40 |
------ |
------ |
------ |
|
|
|
1981 S |
2.64 |
24 |
------ |
------ |
------ |
------ |
|
|
1) A = autumn, S = spring |
|||||||
Exercise 4.4.3 The linearized catch curve based on age composition data
Use the data presented in Table 4.4.3.1 of North Sea whiting (1974-1980).
Tasks:
Estimate Z from the catches of the 1974-cohort after plotting the catch curve. Calculate the confidence limits of the estimate of Z.
Worksheet 4.4.3
|
age |
year |
C(y, t, t+1) |
ln C(y, t, t+1) |
remarks |
|
(x) |
|
|
(y) |
|
|
0 |
|
|
|
|
|
1 |
|
|
|
|
|
2 |
|
|
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
|
5 |
|
|
|
|
|
6 |
|
|
|
|
|
7 |
1981 |
- |
- |
|
|
slope: b = |
sb2 = [(sy/sx)2 - b2]/(n-2) = | |||
|
sb = |
sb * tn-2 = ________________ z = _______ ± _______ | |||
Exercise 4.4.5 The linearized catch curve based on length composition data
Length-frequency data from Ziegler (1979) for the threadfin bream (Nemipterus japonicus) from Manila Bay are given in the worksheet below, L¥ = 29.2 cm, K = 0.607 per year.
Tasks:
1) Carry out the length-converted catch curve analysis, using the worksheet.
2) Draw the catch curve.
3) Calculate the confidence limits for each estimate of Z.
Worksheet 4.4.5
|
L1 - L2 |
C (L1, L2) |
t(L1) |
D t |
|
|
z |
remarks |
|
|
|
a) |
b) |
c) |
(y) |
|
|
|
7-8 |
11 |
|
|
|
|
|
not used, not under full exploitation |
|
8-9 |
69 |
|
|
|
|
|
|
|
9-10 |
187 |
|
|
|
|
|
|
|
10-11 |
133 |
|
|
|
|
|
? |
|
11-12 |
114 |
|
|
|
|
|
? |
|
12-13 |
261 |
|
|
|
|
|
? |
|
13-14 |
386 |
|
|
|
|
|
? |
|
14-15 |
445 |
|
|
|
|
|
? |
|
15-16 |
535 |
|
|
|
|
|
? |
|
16-17 |
407 |
|
|
|
|
|
? |
|
17-18 |
428 |
|
|
|
|
|
? |
|
18-19 |
338 |
|
|
|
|
|
? |
|
19-20 |
184 |
|
|
|
|
|
? |
|
20-21 |
73 |
|
|
|
|
|
? |
|
21-22 |
37 |
|
|
|
|
|
? |
|
22-23 |
21 |
|
|
|
|
|
? |
|
23-24 |
19 |
|
|
|
|
|
? |
|
24-25 |
8 |
|
|
|
|
|
? |
|
25-26 |
7 |
|
|
|
|
|
too close to L¥ |
|
26-27 |
2 |
|
|
|
|
|
|
Formulas to be used:
a) Eq. 3.3.3.2
b) Eq. 4.4.5.1
c) Eq. 4.4.5.2
Details of the regression analyses:
|
length group |
slope |
number of obs. |
Student's distrib. |
variance of slope |
stand. dev. of slope |
confidence limits of Z |
|
L1 - L2 |
Z |
n |
tn-2 |
sb2 |
sb |
Z ± tn-2 * sb |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Exercise 4.4.6 The cumulated catch curve based on length composition data (Jones and van Zalinge method)
Length-frequency data from Ziegler (1979) for the threadfin bream (Nemipterus japonicus) from Manila Bay are given in the worksheet below,
L¥ = 29.2 cm, K = 0.607 per year.
Tasks:
1) Determine Z/K by the Jones and van Zalinge method, using the worksheet. (Start cumulation at largest length group).2) Plot the "catch curve".
3) Calculate the 95% confidence limits for each estimate of Z (worksheet).
Worksheet 4.4.6
|
L1 - L2 |
C(L1, L2) |
S C (L1, L¥ ) cumulated |
ln S C (L1, L¥ ) |
ln (L¥ - L1) |
Z/K |
remarks |
|
|
|
|
(y) |
(x) |
(slope) |
|
|
7-8 |
11 |
|
|
|
|
not used, not under full exploitation |
|
8-9 |
69 |
|
|
|
|
|
|
9-10 |
187 |
|
|
|
|
|
|
10-11 |
133 |
|
|
|
|
? |
|
11-12 |
114 |
|
|
|
|
? |
|
12-13 |
261 |
|
|
|
|
? |
|
13-14 |
386 |
|
|
|
|
? |
|
14-15 |
445 |
|
|
|
|
? |
|
15-16 |
535 |
|
|
|
|
? |
|
16-17 |
407 |
|
|
|
|
? |
|
17-18 |
428 |
|
|
|
|
? |
|
18-19 |
338 |
|
|
|
|
? |
|
19-20 |
184 |
|
|
|
|
? |
|
20-21 |
73 |
|
|
|
|
? |
|
21-22 |
37 |
|
|
|
|
? |
|
22-23 |
21 |
|
|
|
|
? |
|
23-24 |
19 |
|
|
|
|
? |
|
24-25 |
8 |
|
|
|
|
? |
|
25-26 |
7 |
|
|
|
|
too close to L¥ |
|
26-27 |
2 |
|
|
|
|
|
Details of the regression analyses
|
length group |
slope |
number of obs. |
Student's distrib. |
variance of slope |
stand. dev. of slope |
confidence limits of Z |
|
L1 - L2 |
Z |
n |
tn-2 |
sb2 |
sb |
Z ± K * tn-2 * sb |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Exercise 4.4.6a The Jones and van Zalinge method applied to shrimp
Carapace length-frequency data for female shrimp (Penaeus semisulcatus) from Kuwait waters, 1974-1975, from Jones and van Zalinge (1981), are presented in the worksheet below. L¥ = 47.5 mm (carapace length). Input data are total landings in millions of shrimps per year by the Kuwait industrial shrimp fishery.
Note: In this case the length intervals have different sizes, because the length groups have been derived from commercial size groups, which are given in number of tails per pound (1 kg = 2.2 pounds).
Tasks:
1) Determine Z/K by the Jones and van Zalinge method using the worksheet.
2) Plot the "catch curve".
3) Calculate the 95 % confidence limits for each estimate of Z/K.
Worksheet 4.4.6a
|
carapace length |
numbers landed/year |
cumulated numbers/year |
|
|
|
remarks |
|
L1 - L2 |
C(L1, L2) |
S C(L1, L¥ ) |
ln S C(L1, L¥ ) |
ln (L¥ - L1) |
Z/K |
|
|
|
|
|
(y) |
(x) |
(slope) |
|
|
11.18-18.55 |
2.81 |
|
|
|
|
|
|
18.55-22.15 |
1.30 |
|
|
|
|
|
|
22.15-25.27 |
2.96 |
|
|
|
|
|
|
25.27-27.58 |
3.18 |
|
|
|
|
|
|
27.58-29.06 |
2.00 |
|
|
|
|
|
|
29.06-30.87 |
1.89 |
|
|
|
|
|
|
30.87-33.16 |
1.78 |
|
|
|
|
|
|
33.16-36.19 |
0.98 |
|
|
|
|
|
|
36.19-40.50 |
0.63 |
|
|
|
|
|
|
40.50-47.50 |
0.63 |
|
|
|
|
|
Details of the regression analyses:
|
lower length |
slope |
number of obs. |
Student's distrib. |
variance of slope |
stand. dev. of slope |
confidence limits of slope |
|
L1 |
Z/K |
n |
tn-2 |
sb2 |
sb |
Z/K ± tn-2 * sb |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Exercise 4.5.1 Beverton and Holt's Z-equation based on length data (applied to shrimp)
The same data as for Exercise 4.4.6a (from Jones and van Zalinge, 1981) on Penaeus semisulcatus are given in the worksheet below. L¥ = 47.5 mm (carapace length).
Tasks:
Estimate Z/K using Beverton and Holt's Z-equation (Eq. 4.5.1.1) and the worksheet (start cumulations at largest length group).
Worksheet 4.5.1
|
A |
B |
C |
D |
E |
F |
G |
H |
|
carapace length group |
numbers landed/year |
cumulated catch |
mid-length |
*) |
*) |
*) |
*) |
|
L' (L1) - L2 |
C(L1, L2) |
S C(L1, L¥ ) |
|
|
|
|
Z/K |
|
11.18-18.55 |
2.81 |
|
|
|
|
|
|
|
18.55-22.15 |
1.30 |
|
|
|
|
|
|
|
22.15-25.27 |
2.96 |
|
|
|
|
|
|
|
25.27-27.58 |
3.18 |
|
|
|
|
|
|
|
27.58-29.06 |
2.00 |
|
|
|
|
|
|
|
29.06-30.87 |
1.89 |
|
|
|
|
|
|
|
30.87-33.16 |
1.78 |
|
|
|
|
|
|
|
33.16-36.19 |
0.98 |
|
|
|
|
|
|
|
36.19-40.50 |
0.63 |
|
|
|
|
|
|
|
40.50-47.50 |
0.63 |
|
|
|
|
|
|
|
*) Column E: catch per length group * mid length | |||||||
Exercise 4.5.4 The Powell-Wetherall method
Fork-length distribution (in %) of the blue-striped grunt (Haemulon sciurus) caught in traps at the Port Royal reefs off Jamaica during surveys in 1969-1973, are given in the worksheet below (from Munro, 1983, Table 10.35 p. 137).
Tasks:
1) Complete the worksheet, from the bottom.2) Make the Powell-Wetherall plot and decide on the points to be included in the regression analysis.
3) Estimate Z/K and L (in fork-length).
4) What are the basic assumptions underlying the method?
Worksheet 4.5.4
|
A |
B |
C |
D *) |
E *) |
F *) |
G *) |
H *) |
|
L1 - L2 |
C(L1, L2) (% catch) |
|
S C(L',¥) |
|
|
|
|
|
(x) |
|
|
|
|
|
|
(y) |
|
14-15 |
1.8 |
14.5 |
|
|
|
|
|
|
15-16 |
3.4 |
15.5 |
|
|
|
|
|
|
16-17 |
5.8 |
16.5 |
|
|
|
|
|
|
17-18 |
8.4 |
17.5 |
|
|
|
|
|
|
18-19 |
9.1 |
18.5 |
|
|
|
|
|
|
19-20 |
10.2 |
19.5 |
|
|
|
|
|
|
20-21 |
14.3 |
20.5 |
|
|
|
|
|
|
21-22 |
13.7 |
21.5 |
|
|
|
|
|
|
22-23 |
10.0 |
22.5 |
|
|
|
|
|
|
23-24 |
6.3 |
23.5 |
|
|
|
|
|
|
24-25 |
6.4 |
24.5 |
|
|
|
|
|
|
25-26 |
5.3 |
25.5 |
|
|
|
|
|
|
26-27 |
3.3 |
26.5 |
|
|
|
|
|
|
27-28 |
1.8 |
27.5 |
|
|
|
|
|
|
28-29 |
0.3 |
28.5 |
|
|
|
|
|
|
*) Column D: sum column B (from the bottom) | |||||||
Exercise 4.6 Plot of Z on effort (estimation of M and q)
For the trawl fishery in the Gulf of Thailand the effort (in millions of trawling hours) and the mean lengths of bulls eye (Priacanthus tayenus) over the years 1966-1974 were taken from Boonyubol and Hongskul (1978) and South China Sea Fisheries Development Programme (1978) and presented in the worksheet below (L¥ = 29.0 cm, K = 1.2 per year, Lc = 7.6 cm).
Tasks:
1) Calculate Z, using the worksheet.
2) Plot Z against effort and determine M (intercept) and q (slope).
3) Calculate the 95% confidence limits for the estimates of M and q.
Use the following two sets of input data (years):
a) The years 1966-1970
b) The years 1966-1974 and comment on the results.
Worksheet 4.6
|
year |
effort a) |
mean length |
|
|
1966 |
2.08 |
15.7 |
1.97 |
|
1967 |
2.80 |
15.5 |
|
|
1968 |
3.50 |
16.1 |
|
|
1969 |
3.60 |
14.9 |
|
|
1970 |
3.80 |
14.4 |
|
|
1071 |
no data | ||
|
1972 |
no data | ||
|
1973 |
9.94 |
12.8 |
|
|
1974 |
6.06 |
12.8 |
|
|
a) in millions of trawling hours | |||
Exercise 5.2 Age-based cohort analysis (Pope's cohort analysis)
Catch data by age group of the North Sea whiting (from ICES, 1981a) are presented in Tables 5.1.1 and 4.4.3.1.
Tasks:
1) Calculate fishing mortalities for the 1974 cohort (catch numbers given in Table 5.1.1 and M = 0.2 per year) by Pope's cohort analysis under the two different assumptions on the F for the oldest age group:F6 = 1.0 per year
F6 = 2.0 per year2) Plot F against age for the two cases above as well as for the case of Table 5.1.1, where
F6 = 0.5 per year3) Discuss the significance of the choice of the terminal F (F6). Which of the three alternatives do you prefer? (Base your decision on the solution to Exercise 4.4.3, which deals with the same data set).
Exercise 5.3 Jones' length-based cohort analysis
As in Exercises 4.4.6a and 4.5.1 we use the landings of female Penaeus semisulcatus of the 74/75-cohort from Kuwait waters (from Jones and van Zalinge, 1981). These data were derived from the total number of processed prawns in each of ten market categories (cf. Worksheet 5.3).
Tasks:
1) Using Worksheet 5.3 and the formulas given below, estimate fishing mortalities and stock numbers by means of Jones' length-based cohort analysis, using the parameters:K = 2.6 per year
M = 3.9 per year
L¥ = 47.5 mm (carapace length)2) Give your opinion on our choice of terminal F/Z (= 0.1).
3) Is the cohort analysis a dependable method in this case? (The value of M is a "guesstimate").
Worksheet 5.3
|
length group |
nat. mort. factor |
number caught |
number of survivors |
exploitation rate |
fishing mort. |
total mort. | |
|
g) |
a) |
|
b) |
c) |
d) |
e) | |
|
L1 - L2 |
H(L1, L2) |
C(L1, L2) |
N(L1) |
F/Z |
F |
Z | |
|
11.18-18.55 |
|
2.81 |
|
|
|
| |
|
18.55-22.15 |
|
1.30 |
|
|
|
| |
|
22.1.5-25.27 |
|
2.96 |
|
|
|
| |
|
25.27-27.58 |
|
3.18 |
|
|
|
| |
|
27.58-29.06 |
|
2.00 |
|
|
|
| |
|
29.06-30.87 |
|
1.89 |
|
|
|
| |
|
30.87-33.16 |
|
1.78 |
|
|
|
| |
|
33.16-36.19 |
|
0.98 |
|
|
|
| |
|
36.19-40.50 |
|
0.63 |
|
|
|
| |
|
40.50-47.50 |
|
0.63 f) |
|
|
|
| |
|
a) |
| ||||||
|
b) |
N(L1) = [N(L2) * H(L1, L2) + C(L1, L2)] * H(L1, L2) | ||||||
|
c) |
F/Z = C(L1, L2)/[N(L1) - N(L2)] | ||||||
|
d) |
F = M * (F/Z)/(1 - F/Z) | ||||||
|
e) |
Z = F + M | ||||||
|
f) |
N(last L1) = C(last L1, L¥ )/(F/Z) | ||||||
|
g) |
carapace lengths in mm corresponding to the market categories (in units of number of tails per pound): | ||||||
|
no/lb: |
400 |
110 |
70 |
50 |
40 |
35 |
30 |
25 |
20 |
<15 |
|
L1: |
11.18 |
18.55 |
22.15 |
25.27 |
27.58 |
29.06 |
30.87 |
33.16 |
36.19 |
40.5 |
|
L2: |
18.55 |
22.15 |
25.27 |
27.58 |
29.06 |
30.87 |
33.16 |
36.19 |
40.5 |
47.5 |
Exercise 6.1 A mathematical model for the selection ogive
Tasks:
Draw a selection curve using the parameters:L50% = 13.6 cm and L75% = 14.6 cmUse the logistic curve SL = 1/[1 + exp(S1 - S2 * L)]
Exercise 6.5 Estimation of the selection ogive from a catch curve
Data on catch by length group of Upeneus vittatus were taken from Table 4.4.5.1. K = 0.59 per year, L¥ = 23.1 cm, t0 = -0.08 year
Tasks:
1) Estimate the logistic curve St = 1/[1 + exp(T1 - T2 * t)]
2) Estimate L50% = L¥ * [1 - exp(K * (t0 - t50%))] and L75%
3) Evaluate the choice of first length interval given in Table 4.4.5.1.
Worksheet 6.5
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
length group |
t |
D t |
C(L1, L2) |
ln (C/D t) |
St obs. |
ln (1/S - 1) |
est. |
remarks |
|
|
(x) |
|
|
|
|
(y) |
|
|
|
6-7 |
0.56 |
0.102 |
3 |
3.38 |
|
|
|
(not used) |
|
7-8 |
0.67 |
0.109 |
143 |
7.18 |
|
|
|
|
|
8-9 |
0.78 |
0.116 |
271 |
7.76 |
|
|
|
|
|
9-10 |
0.90 |
0.125 |
318 |
7.86 |
|
|
|
|
|
10-11 |
1.03 |
0.134 |
416 |
8.04 |
|
|
|
|
|
11-12 |
1.17 |
0.146 |
488 |
8.11 |
|
|
|
|
|
12-13 |
1.32 |
0.160 |
614 |
8.25 |
|
|
|
|
|
13-14 |
1.49 |
0.177 |
613f) |
8.15 |
|
|
|
used for the analysis to estimate Z (see Table 4.4.5.1) |
|
14-15 |
1.67 |
0.197 |
493 f) |
7.83 |
|
|
|
|
|
15-16 |
1.88 |
0.223 |
278 f) |
7.13 |
|
|
|
|
|
16-17 |
2.12 |
0.257 |
93 f) |
5.89 |
|
|
|
|
|
17-18 |
2.40 |
0.303 |
73 f) |
5.48 |
|
|
|
|
|
18-19 |
2.74 |
0.370 |
7 f) |
2.94 |
|
|
|
|
|
19-20 |
3.15 |
0.473 |
2 f) |
1.44 |
|
|
|
|
|
20-21 |
3.70 |
0.659 |
2 |
1.11 |
|
|
|
|
|
21-22 |
4.53 |
1.094 |
0 |
- |
|
|
|
|
|
22-23 |
6.19 |
4.094 |
1 |
-1.40 |
|
|
|
|
|
23-24 |
- |
- |
1 |
- |
|
|
|
|
|
a) t [(L1 + L2)/2], age corresponding to interval mid-length b) ln(C/D t), dependent variable in catch curve regression analysis c) S(t) obs. = C/[D t * exp(a - Z * t)], observed selection ogive Z = 4.19 and a = 14.8 (from Table 4.4.5.1) d) ln(1/S - 1), dependent variable in regression e) S(t) est. = 1/[1 + exp(T1 - T2 * t)], theoretical (estimated) selection ogive f) points used in the catch curve analysis (cf. Table 4.4.5.1) | ||||||||
Exercise 6.7 Using a selection curve to adjust catch samples
Tasks:
1) Adjust the length-frequencies for Upeneus vittatus (from the data given in Table 4.4.5.1) using the results of Exercise 6.5:
L50% = 13.6 cm and L75% = 14.6 cm
S1 =
S2 =
SL =
2) Draw a histogram of the original and the adjusted frequencies excluding the raised (estimated unbiased) frequencies which you think are not safely estimated.
Worksheet 6.7
|
length group |
midpoint |
observed biased sample |
selection ogive |
estimated unbiased sample |
|
6-7 |
|
3 |
|
|
|
7-8 |
|
143 |
|
|
|
8-9 |
|
271 |
|
|
|
9-10 |
|
318 |
|
|
|
10-11 |
|
416 |
|
|
|
11-12 |
|
488 |
|
|
|
12-13 |
|
614 |
|
|
|
13-14 |
|
613 |
|
|
|
14-15 |
|
493 |
|
|
|
15-16 |
|
278 |
|
|
|
16-17 |
|
93 |
|
|
|
17-18 |
|
73 |
|
|
|
18-19 |
|
7 |
|
|
|
19-20 |
|
2 |
|
|
|
20-21 |
|
2 |
|
|
|
21-22 |
|
0 |
|
|
|
22-23 |
|
1 |
|
|
|
23-24 |
|
1 |
|
|
Exercise 7.2 Stratified random sampling versus simple random sampling and proportional sampling
This exercise illustrates the gain in precision obtained from stratification. Use Table 7.2.2.
Tasks:
1) Estimate the variance of the mean landing Y from three different sampling methods, when the total sample size is n = 20, using the worksheets.a) Simple random sampling
b) Proportional sampling: a sample of 20% from each stratum
Worksheet 7.2 for a) and b)
|
stratum |
s(j) |
s(j)2 |
N(j) |
|
|
|
1 large |
|
|
|
|
|
|
2 medium |
|
|
|
|
|
|
3 small |
|
|
|
|
|
|
total |
|
|
|
|
|
|
|
|||||
|
a) Simple random sampling
b) Proportional sampling
|
|||||
Worksheet 7.2 for c)
|
stratum |
s(j) * N(j) |
|
|
|
1 large |
|
|
|
|
2 medium |
|
|
|
|
3 small |
|
|
|
|
total |
|
1.00 |
n = 20 |
|
c) Optimum stratified sampling
|
|||
2) Calculate the standard deviations and compare the allocations per stratum.
|
|
random |
proportional |
optimum |
|
|
|
|
|
|
allocation per stratum |
|
|
|
|
1 large |
|
|
|
|
2 medium |
|
|
|
|
3 small |
|
|
|
Exercise 8.3 The yield per recruit model of Beverton and Holt (yield per recruit, biomass per recruit as a function of F)
Pauly (1980) determined the following parameters for Leiognathus splendens (cf. Exercise 3.1.2). W¥ = 64 g, K = 1.0 per year, t0 = -0.2 year, Tr = 0.2 year, M = 1.8 per year.
Tasks:
1) Draw the Y/R and the B/R curves, for three different values of Tc: Tc = Tr = 0.2 year, Tc = 0.3 year and Tc = 1.0 year.
Worksheet 8.3
|
|
Tc = Tr = 0.2 |
Tc = 0.3 |
Tc = 1.0 | |||
|
F |
Y/R |
B/R |
Y/R |
B/R |
Y/R |
B/R |
|
0.0 |
|
|
|
|
|
|
|
0.2 |
|
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
|
0.6 |
|
|
|
|
|
|
|
0.8 |
|
|
|
|
|
|
|
1.0 |
|
|
|
|
|
|
|
1.2 |
|
|
|
|
|
|
|
1.4 |
|
|
|
|
|
|
|
1.6 |
|
|
|
|
|
|
|
1.8 |
|
|
|
|
|
|
|
2.0 |
|
|
|
|
|
|
|
2.2 |
|
|
|
|
|
|
|
2.4 |
|
|
|
|
|
|
|
2.6 |
|
|
|
|
|
|
|
2.8 |
|
|
|
|
|
|
|
3.0 |
|
|
|
|
|
|
|
3.5 |
|
|
|
|
|
|
|
4.0 |
|
|
|
|
|
|
|
4.5 |
|
|
|
|
|
|
|
5.0 |
|
|
|
|
|
|
|
100.0 |
|
|
|
|
|
|
2) Try to explain why MSY increases when Tc increases (without the use of mathematics). Is the above statement a general rule, i.e. does it hold for any increase of Tc?
3) Read the (approximate) values of FMSY and MSY/R from the worksheet. Comment on your findings under the assumption that the present level of F is 1.0.
Exercise 8.4 Beverton and Holt's relative yield per recruit concept
For the swordfish (Xiphias gladius) off Florida, Berkeley and Houde (1980) determined the parameters:
L¥ = 309 cm, K = 0.0949 per year and M = 0.18 per year
Tasks:
Draw the relative yield per recruit curve, (Y/R') as a function of E, for two different values of the 50% retention length:Lc = 118 cm and Lc = 150 cm.
Worksheet 8.4
|
|
Lc = 118 cm |
Lc = 150 cm |
|
|
E |
(Y/R)' |
(Y/R)' |
(F) |
|
0 |
|
|
0 |
|
0.1 |
|
|
0.020 |
|
0.2 |
|
|
0.045 |
|
0.3 |
|
|
0.077 |
|
0.4 |
|
|
0.120 |
|
0.5 |
|
|
M = 0.180 |
|
0.6 |
|
|
0.270 |
|
0.7 |
|
|
0.42 |
|
0.8 |
|
|
0.72 |
|
0.9 |
|
|
1.62 |
|
1.0 |
|
|
¥ |
Exercise 8.6 A predictive age-based model (Thompson and Bell analysis)
In the (hypothetical example) given in the table below a fish stock is exploited by two different gears, viz. beach seines and gill nets. These gears account for the total catch from the stock. A sampling programme for estimation of total numbers caught by age group and by gear has been running for the years 1975-1985.
Based on the total numbers caught a VPA has been made and the estimated F values for the last data year (1985) have been separated into a beach seine component, FB and a gill net component FG (cf. Eq. 8.6.1). The average recruitment (number of 0-group fish) for the years 1975 to 1985 has been estimated from VPA to be 1000000 fish. The natural mortalities are assumed to take the age-specific values. These data are presented in part a of the worksheet.
Tasks:
Use Worksheet 8.6a to solve the following problems:1) Under the assumption that fishing mortality remains the same as in 1985 and that the recruitment is of average size, predict (based on the assumption of equilibrium):
1.1) The number of survivors (stock numbers) by age group.
1.2) Numbers caught by age group for each gear.
1.3) Yield of each gear.Use Worksheet 8.6b to solve the following problems:
2) Under the assumption that the gill net effort remains the same as in 1985 but that the beach seine fishery is closed (and that the recruitment is of average size) predict as 1.1, 1.2 and 1.3 above.
3) Would you, based on the results of 1) and 2) recommend a closure of the beach seine fishery?
Worksheet 8.6
a. No change in fishing effort:
|
age group |
mean weight (g) |
beach seine mortality |
gill net mortality |
natural mortality |
total mortality |
stock number |
beach seine catch |
gill net catch |
beach seine yield |
gill net yield |
total yield |
|
t |
w |
FB |
FG |
M |
Z |
'000 |
CB |
CG |
YB |
YG |
YB + YG |
|
0 |
8 |
0.05 |
0.00 |
2.00 |
|
1000 |
|
|
|
|
|
|
1 |
283 |
0.40 |
0.00 |
0.80 |
|
|
|
|
|
|
|
|
2 |
1155 |
0.10 |
0.19 |
0.30 |
|
|
|
|
|
|
|
|
3 |
2406 |
0.01 |
0.59 |
0.20 |
|
|
|
|
|
|
|
|
4 |
3764 |
0.00 |
0.33 |
0.20 |
|
|
|
|
|
|
|
|
5 |
5046 |
0.00 |
0.09 |
0.20 |
|
|
|
|
|
|
|
|
6 |
6164 |
0.00 |
0.02 |
0.20 |
|
|
|
|
|
|
|
|
7 |
7090 |
0.00 |
0.00 |
0.20 |
|
|
|
|
|
|
|
|
total | |||||||||||
|
Z = FB + FG + M |
N(t + 1) = N(t) * exp(-Z) | ||||||||||
|
CB = FB * N * (1 - exp(-Z))/Z |
CG = FG * N * (1 - exp(-Z))/Z | ||||||||||
|
|
| ||||||||||
b. Closure of the beach seine fishery:
|
age group |
mean weight (g) |
beach seine mortality |
gill net mortality |
natural mortality |
total mortality |
stock number |
beach seine catch |
gill net catch |
beach seine yield |
gill net yield |
total yield |
|
t |
w |
FB |
FG |
M |
Z |
'000 |
CB |
CG |
YB |
YG |
YB + YG |
|
0 |
8 |
|
|
|
|
|
|
|
|
|
|
|
1 |
283 |
|
|
|
|
|
|
|
|
|
|
|
2 |
1155 |
|
|
|
|
|
|
|
|
|
|
|
3 |
2406 |
|
|
|
|
|
|
|
|
|
|
|
4 |
3764 |
|
|
|
|
|
|
|
|
|
|
|
5 |
5046 |
|
|
|
|
|
|
|
|
|
|
|
6 |
6164 |
|
|
|
|
|
|
|
|
|
|
|
7 |
7090 |
|
|
|
|
|
|
|
|
|
|
|
total | |||||||||||
Exercise 8.7 A predictive length-based model (Thompson and Bell analysis)
For this exercise a hypothetical example is used:
M = 0.3 per year, K = 0.3 per year, L¥ = 60.0 cm
Recruitment, N(10, 15) = 1000
|
length class |
fishing mortality |
mean body weight g |
price per kg |
natural mortality factor |
|
L1 - L2 |
F (L1, L2) |
|
(L1, L2) |
H (L2, L2) a) |
|
10-15 |
0.03 |
19.5 |
1.0 |
1.05409 |
|
15-20 |
0.20 |
53.6 |
1.0 |
1.06066 |
|
20-25 |
0.40 |
113.9 |
1.5 |
1.06904 |
|
25-30 |
0.70 |
207.9 |
1.5 |
1.08012 |
|
30-35 |
0.70 |
343.3 |
2.0 |
1.09544 |
|
35-40 |
0.70 |
527.3 |
2.0 |
1.11803 |
|
40-L¥ |
0.70 |
767.7 |
2.0 |
- |
|
a) H(L1, L2) = ((L¥ - L1)/(L¥ - L2))M/2K | ||||
Tasks:
Do the length-converted Thompson and Bell analysis on the example.
Worksheet 8.7
|
length class |
P(L1, L2) |
N(L1) |
N(L2) |
mean biomass |
catch |
yield |
value |
|
10-15 |
0.03 |
1000 |
|
|
|
|
|
|
15-20 |
0.20 |
|
|
|
|
|
|
|
20-25 |
0.40 |
|
|
|
|
|
|
|
25-30 |
0.70 |
|
|
|
|
|
|
|
30-35 |
0.70 |
|
|
|
|
|
|
|
35-40 |
0.70 |
|
|
|
|
|
|
|
40-L¥ |
0.70 |
|
|
f) |
|
|
|
|
|
Total |
_____ |
|
|
|
|
|
|
a) N(L1) of a length group is equivalent to the N(L2) of the previous length group c) C(L1, L2) = F(L1, L2) * Nmean(L1, L2) * D t
e) value(L1, L2) = yield(L1, L2) * price(L1, L2)
| |||||||
Exercise 8.7a A predictive length-based model (yield curve, Thompson and Bell analysis)
Tasks:
1) Do the same exercise as in Exercise 8.7 but under the assumption of a 100% increase in fishing effort (Worksheet 8.7a).
Worksheet 8.7a
|
length class |
F(L1, L2) |
N(L1) |
N(L2) |
mean biomass |
catch |
yield |
value |
|
10-15 |
|
1000 |
|
|
|
|
|
|
15-20 |
|
|
|
|
|
|
|
|
20-25 |
|
|
|
|
|
|
|
|
25-30 |
|
|
|
|
|
|
|
|
30-35 |
|
|
|
|
|
|
|
|
35-40 |
|
|
|
|
|
|
|
|
40-L¥ |
|
|
|
f) |
|
|
|
|
|
Total |
_____ |
|
|
|
|
|
|
a) N(L1) of a length group is equivalent to the N(L2) of the previous length group
where Nmean(L1, L2) * Dt = [N(L1) - N(L2)]/Z(L1, L2) c) C(L1, L2) = F(L1, L2) * Nmean(L1, L2) * D t
e) value(L1, L2) = yield(L1, L2) * price(L1, L2)
| |||||||
2) Use the result of 1) combined with the solution to Exercise 8.7 and the results given in the table below to draw the yield, the mean biomass and the value curves.
|
F-factor |
yield |
mean biomass |
value |
|
x |
|
* D t |
|
|
0.0 |
0.00 |
1445.41 |
0.00 |
|
0.2 |
116.38 |
865.89 |
226.11 |
|
0.4 |
154.48 |
585.63 |
296.49 |
|
0.6 |
165.12 |
426.42 |
312.70 |
|
0.8 |
164.75 |
326.87 |
307.56 |
|
1.0 |
|
|
|
|
1.2 |
153.25 |
213.94 |
277.35 |
|
1.4 |
146.23 |
180.15 |
260.38 |
|
1.6 |
139.37 |
154.84 |
244.14 |
|
1.8 |
132.95 |
135.40 |
229.10 |
|
2.0 |
|
|
|
|
MSY = 165.8 at X = 0.69 biomass at MSY = 378.8 | |||
|
MSE = 312.9 at X = 0.61 biomass at MSE = 405.7 | |||
Exercise 9.1 The Schaefer model and the Fox model
In Worksheet 9.1 are given total catch and total effort in standard boat days for the years 1969 through 1978 for the shrimp fishery in the Arafura Sea. Catches are mainly composed of the five species Penaeus merguiensis, Penaeus semisulcatus, Penaeus monodon, Metapenaeus ensis and Parapenaeopsis sculptilis (from Naamin and Noer, 1980).
Tasks:
1) Calculate Y/f (kg per boat day) and ln (Y/f) and plot them against effort.
2) Estimate MSY and fMSY by the Schaefer model.
3) Estimate MSY and fMSY by the Fox model.
4) Plot yield against effort and draw the yield curves estimated by the two methods.
Worksheet 9.1
|
year |
yield (tonnes) |
effort |
Schaefer |
Fox |
|
i |
Y(i) |
(x) |
(y) |
(y) |
|
1969 |
546.7 |
1224 |
|
|
|
1970 |
812.4 |
2202 |
|
|
|
1971 |
2493.3 |
6684 |
|
|
|
1972 |
4358.6 |
12418 |
|
|
|
1973 |
6891.5 |
16019 |
|
|
|
1974 |
6532.0 |
21552 |
|
|
|
1975 |
4737.1 |
24570 |
|
|
|
1976 |
5567.4 |
29441 |
|
|
|
1977 |
5687.7 |
28575 |
|
|
|
1978 |
5984.0 |
30172 |
|
|
|
mean values |
|
|
|
|
|
standard deviations |
|
|
|
|
|
intercept (Schaefer: a, Fox: c) *) |
|
|
||
|
slope (Schaefer: b. Fox: d) *) |
|
|
||
|
*) a, b replaced by c, d for the Fox model |
||||
continuation of Worksheet 9.1
|
|
Schaefer |
Fox |
|
variance of slope |
|
|
|
standard deviation of slope, sb |
|
|
|
variance of intercept |
|
|
|
standard deviation of intercept |
|
|
|
MSY |
- a2/(4b) = |
-(1/d) * exp(c - 1) = |
|
fMSY |
- a/(2b) = |
- 1/d = |
Worksheet 9.1a (for drawing the yield curves)
|
f |
Schaefer |
Fox |
|
5000 |
|
|
|
10000 |
|
|
|
15000 |
|
|
|
20000 |
|
|
|
25000 |
|
|
|
fMSY |
|
|
|
30000 |
|
|
|
35000 |
|
|
|
fMSY |
|
|
|
40000 |
|
|
|
45000 |
|
|
Exercise 13.8 The swept area method, precision of the estimate of biomass, estimation of MSY and optimal allocation of hauls
The data for this exercise were taken from report no. 8 of Project KEN/74/023: "Offshore trawling survey", which deals with the stock assessment of Kenyan demersal resources from surveys in the period 1979-81. The data used here are a modified set on the catch of the small-spotted grunt, Pomadasys opercularis. The data are given as catch in weight per unit time (Cw/t) in kg per hour trawling for 23 hauls covering two strata (in Worksheet 13.8). The vessel speed, current speed, both in knots (nautical mile per hour) and trawl wing spread (hr * X2) are also given.
Tasks:
1) Apply Eq. 13.5.3 to calculate the distance, D, covered per hour and Eq. 13.5.1 to calculate the area swept per hour, a, for each haul. Calculate the yield, Cw, per unit of area for each haul using Eq. 13.6.2 (data in the worksheet, 1 nautical mile (nm) = 1852 m).2) Calculate for each stratum the estimate of mean catch per unit area Ca and the confidence limits of the estimates (using Eq. 2.3.1). Calculate using Eqs. 13.7.5 and 13.6.3 an estimate of the mean biomass for the total area, when A1 = 24 square nautical miles (sq.nm), A2 = 53 sq.nm and X1 (catchability) is assigned the value 0.5.
3) Estimate MSY using Gulland's formula, with M = Z = 0.6 per year (i.e. we assume a virgin stock).
4) Construct a graph showing the maximum relative error for the mean catch per area against the number of hauls for each of the two strata. We define (cf. Section 7.1, Fig. 7.1.1)
where s is the standard deviation of the estimate of the catch in weight per unit area:
5) Assume that you have financial resources to make 200 hauls. Allocate these 200 hauls between the two strata for optimum stratified sampling (cf. Section 7.2).
Worksheet 13.8
STRATUM 1:
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
|
HAUL |
CPUE |
VESSEL |
CURRENT |
TRAWL |
AREA |
CPUA | |||
|
no. |
Cw/h |
speed |
course |
speed |
direction |
spread |
distance |
swept |
Cw/a = Ca |
|
1 |
7.0 |
2.8 |
220 |
0.5 |
90 |
18 |
|
|
|
|
2 |
7.0 |
3.0 |
210 |
0.5 |
180 |
16 |
|
|
|
|
3 |
5.0 |
3.0 |
200 |
0.3 |
135 |
17 |
|
|
|
|
4 |
4.0 |
3.0 |
180 |
0.4 |
230 |
18 |
|
|
|
|
5 |
1.0 |
3.0 |
90 |
0.5 |
270 |
17 |
|
|
|
|
6 |
4.0 |
3.0 |
45 |
0.4 |
160 |
18 |
|
|
|
|
7 |
9.0 |
3.5 |
25 |
0.4 |
200 |
18 |
|
|
|
|
8 |
0.0 |
3.0 |
210 |
0.3 |
300 |
18 |
|
|
|
|
9 |
0.0 |
3.5 |
0 |
0.4 |
0 |
18 |
|
|
|
|
10 |
14.0 |
2.8 |
45 |
0.6 |
0 |
18 |
|
|
|
|
11 |
8.0 |
3.0 |
120 |
0.3 |
300 |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
STRATUM 2: | |||||||||
|
12 |
42.0 |
4.0 |
30 |
0.5 |
160 |
17 |
|
|
|
|
13 |
98.0 |
3.3 |
215 |
0.4 |
90 |
17 |
|
|
|
|
14 |
223.0 |
3.9 |
30 |
0.0 |
0 |
17 |
|
|
|
|
15 |
59.0 |
3.8 |
35 |
0.3 |
180 |
17 |
|
|
|
|
16 |
32.0 |
3.5 |
210 |
0.5 |
270 |
17 |
|
|
|
|
17 |
6.0 |
2.8 |
210 |
0.5 |
330 |
17 |
|
|
|
|
18 |
66.0 |
3.8 |
45 |
0.5 |
30 |
17 |
|
|
|
|
19 |
60.0 |
4.0 |
30 |
0.5 |
180 |
18 |
|
|
|
|
20 |
48.0 |
4.0 |
210 |
0.5 |
180 |
18 |
|
|
|
|
21 |
52.0 |
3.8 |
20 |
0.4 |
180 |
18 |
|
|
|
|
22 |
48.0 |
4.0 |
30 |
0.5 |
190 |
18 |
|
|
|
|
23 |
18.0 |
3.0 |
210 |
0.3 |
190 |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
Confidence limits of | ||||||
|
stratum |
number of hauls |
|
standard deviation |
|
Student's distr. |
confidence limits for |
|
|
n |
|
s |
s/Ö n |
tn-1 |
|
|
1 |
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
Worksheet 13.8a (for plotting graph maximum relative error)
|
number of hauls |
Student's distribution |
stratum 1 |
stratum 2 |
|
n |
tn-1 |
e a) |
e a) |
|
5 |
2.78 |
|
|
|
10 |
2.26 |
|
|
|
20 |
2.09 |
|
|
|
50 |
2.01 |
|
|
|
100 |
1.98 |
|
|
|
200 |
1.97 |
|
|
|
| |||
Worksheet 13.8b (optimum allocation)
|
stratum |
standard deviation of Ca |
area of stratum |
|
|
|
|
|
s |
A |
A * s |
A * s/S A * s |
200 * A * s/S A * s |
|
1 |
|
|
|
|
|
|
2 |
|
|
|
|
|
|
Total |
|
|
|
|
|
![]()
![]()
![]()
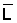 (j)
(j)
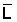 (j)
(j)
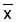
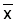 )2
)2
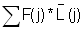
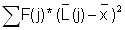
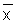 =
=
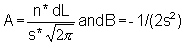
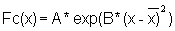
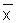 =
=
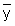 =
=
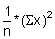 =
=
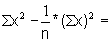
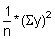 =
=
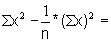
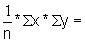
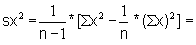
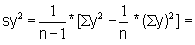
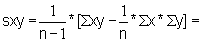
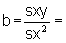
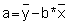 =
=
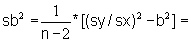
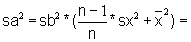
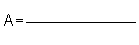
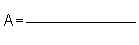
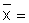
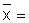
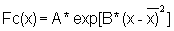
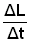
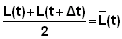
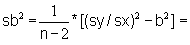
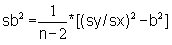
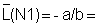
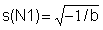
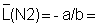
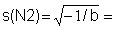
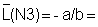
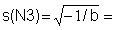
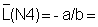
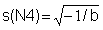 =
=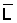
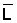
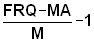
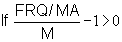
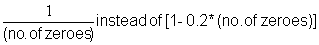
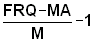
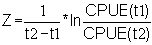
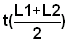
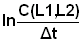
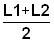
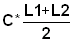
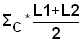
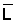
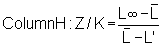
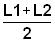
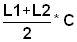
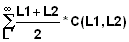
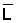
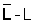
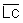 cm
cm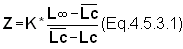
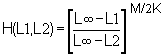
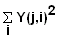
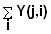
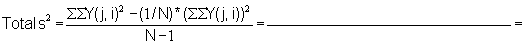
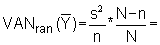
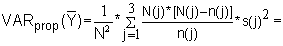
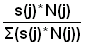
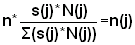
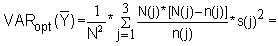
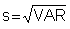
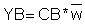
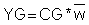
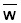
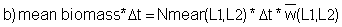
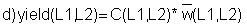
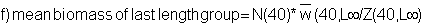
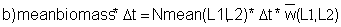
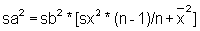

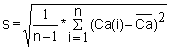
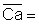
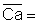



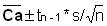
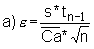
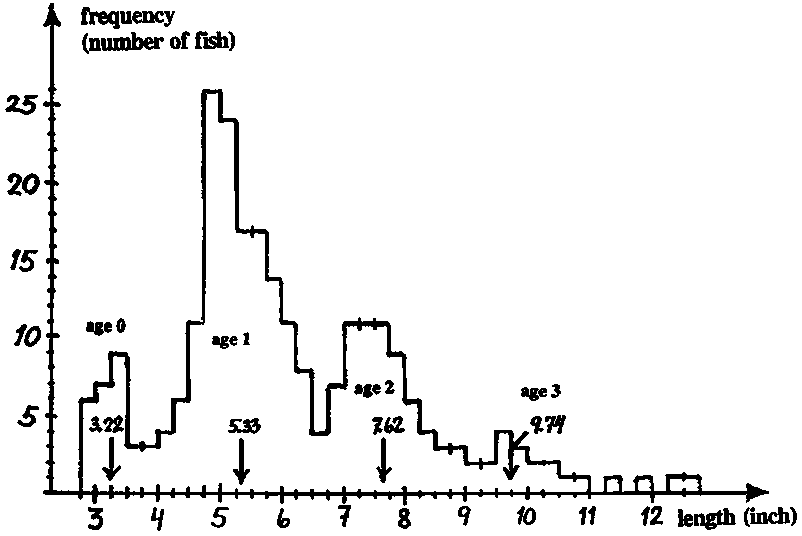{kind=link}
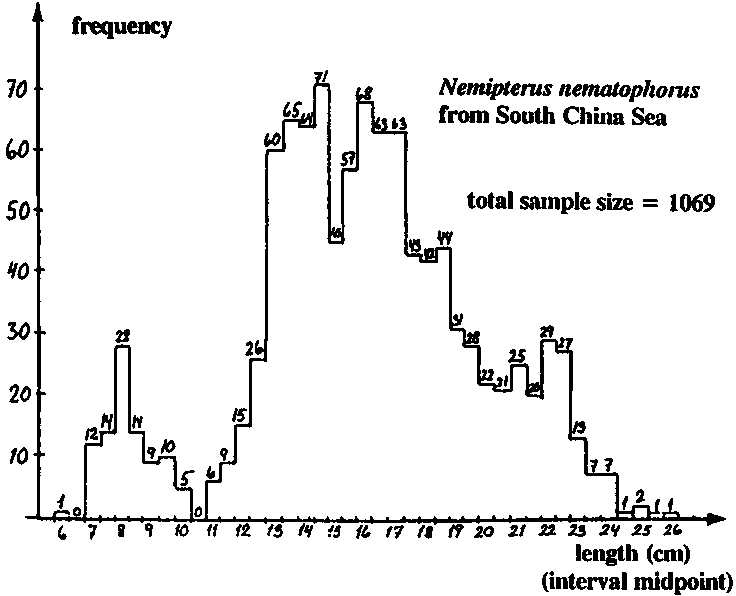{kind=link}
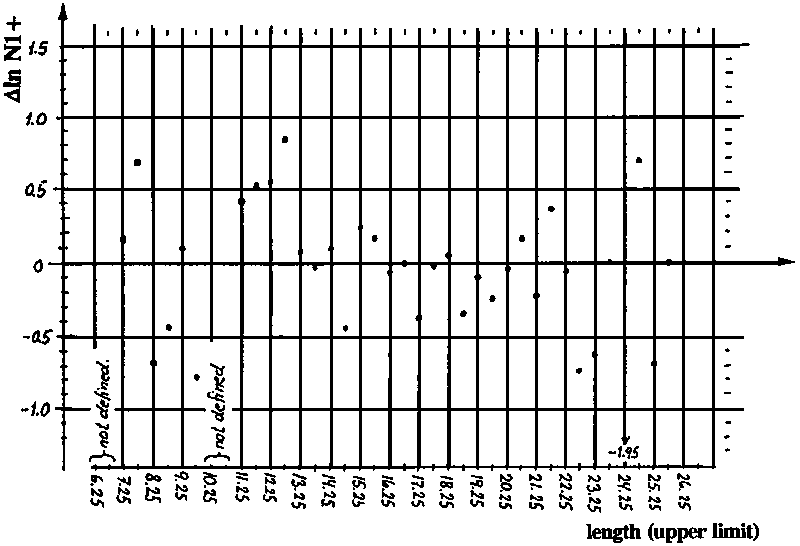{kind=link}
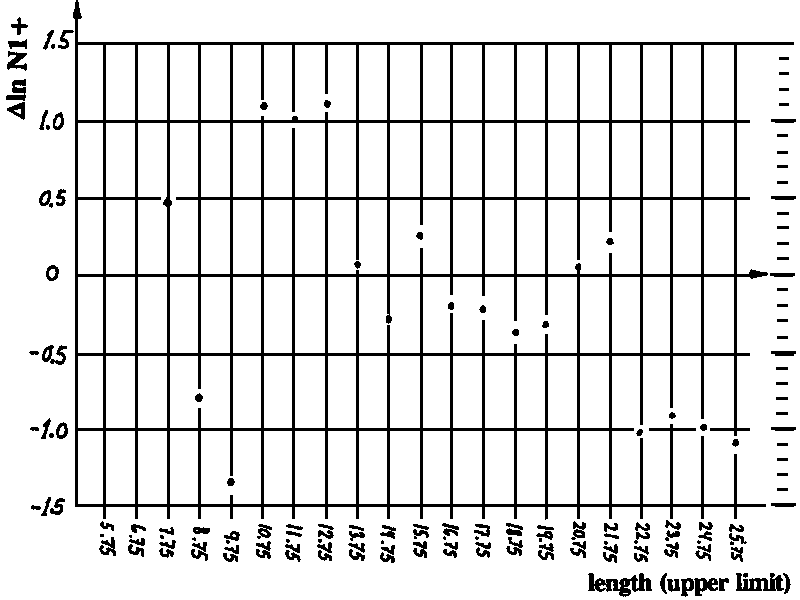{kind=link}
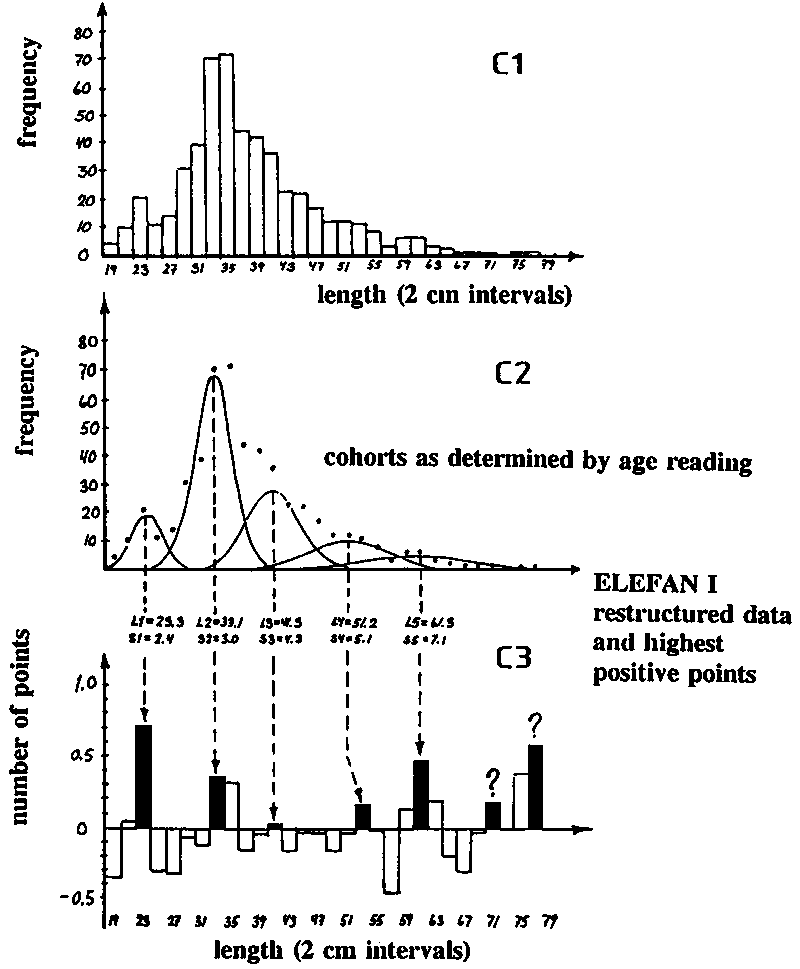{kind=link}