


Designing a survey entails several stages. These were dealt with in greater detail in the Introduction and in the previous Chapters, but are now taken up again and discussed in greater depth with regard to the collection, processing and analysis of field data and the drafting of the final report:
a) The first stage consists in defining the objectives of the survey, which need to be clear, concise, attainable and in line with the needs of all the groups concerned. The geographical and sectoral scope of the survey must also be defined. The objectives can be modified as the survey proceeds and, especially, as existing information is reviewed.
b) The next stage is to thoroughly review existing information. The information emerging during this stage will be useful for defining objectives, for deciding the depth needed (rapid or detailed survey) and for selecting the variables to be analysed and the methods of collecting and processing the data.
c) As determined by the objectives, the financial, human and time resources available, and the quality of existing information, a decision will be taken as to the level of depth of the survey: rapid or detailed.
d) In the light of the objectives, a selection of the variables to be analysed will be made. (Chapter 2)
e) If a detailed survey is decided, a sampling design will be needed, requiring an excellent information base as sampling frame. (Chapter 3)

In the case of rapid surveys, the most commonly used tools are the structured and unstructured interviews of qualified informants, the participatory rapid appraisal and the recording of secondary and primary data.
For detailed surveys the structured interview and record sheets of primary information data are used.
Unstructured interview. Here one has a general idea of the subjects of interest but no pre-established sequence is followed. This is applied where the respondent is in a position of authority or is reluctant to provide information. The unstructured interview is used to acquire a preliminary overview of the subject.
Structured interview. Here questionnaires are used to obtain data on demand, provision and, in some cases, indirect supply. The questionnaires can be quite simple a sort of guide to questions when a degree of informality is required, as in the case of woodfuel traders or industrial users. The more detailed questionnaires are used in surveys and censuses where there are more cases (over 30) or where there are more than three enumerators. Examples of questionnaires are given in Annex IV.
Some recommendations for questionnaire design:
The type and number of questions will depend on the variables to be analysed. Questions not having a direct bearing on the subject must not be included. Questions should be brief, use simple language and follow a sequence that makes sense to the interviewee.
As far as possible, questions should be closed as these are easier to process. Open questions are very useful in eliciting opinions, perceptions and preferences, where the ticked box reply is unsuitable.
Before finalizing the questionnaire, a preliminary one must be tried out on a small sample of the target population. This helps discover the range of possible replies or unanticipated situations.
When working with very large samples and complex questions, it is best if the questions are accompanied by precise instructions on how they should be formulated.
Data record sheets. These are useful in recording primary and secondary information: size of population, diameters, heights and species of trees on forest inventory plots, local units, specific weights of wood, heating value of fuels, etc. It is most important that they cover all the variables to be recorded, which can be checked by comparing variables covered with those of the survey. They should also be field tested before finalization. Annex IV illustrates some types of data record sheet.
Participatory rapid appraisals. These consist in obtaining qualitative information with the collective participation of the users, producers or traders. They are useful in providing a rapid overview of the subject under study. They should only be used when there are close ties with the participants and there is the possibility of meeting their expectations, as these very commonly emerge in this type of collective exercise. Procedures geared to these appraisals can be found in specialist publications (cf. McCraken, J. et al., 1988; CIDE-WRI et al., 1990; WRI-GEA, 1993).
Where feasible, field data collection should be concentrated in a short period of time, because in this way the work will be done more efficiently and the data will be of better quality. Useful in planning the data collection process are time-sheets drawn up in the light of the total work to be done, performance expected of the team and travel time.
If the survey includes analysis of demand, supply and provision, or the work area is very extensive, it is best to locate all the data collection areas on a map and to plan work routes where different sectors coincide. In this way a greater volume of data can be obtained on each trip.
Before leaving for the field, one needs to have available all relevant data collection material and equipment. Questionnaires must be numbered beforehand, with one consecutive series per sector, and with annotations on stratum, locality, district, etc.
This activity aims to ensure that all persons concerned clearly understand the objectives of the survey, the sample design, the variables requiring analysis, the data collection techniques and data processing. They will thus be able to deal with situations not provided for in the design that commonly arise in the field and in the processing stage. We refer to both data collection and data processing in the hope that the same persons will be involved, thus making for better quality data.
During training, the correct use of data collection techniques must be stressed, particularly the techniques to be applied in using the questionnaires and in taking direct measurements of such matters as fuel consumption, moisture content, tree size and weight of local units.
On completion of training, data collection must be checked for homogeneity. This means comparing the results of a questionnaire and/or direct measurements with the same users (collective interviews) or sampling units. When the replies or measurements are more or less the same for all participants and the supervisor, the data recording quality can be considered adequate and reliable.
When field teams are formed, the responsibilities of each member must be made clear. Each team must have a supervisor, responsible for seeing that activities are carried out as planned, for ensuring that the necessary materials are at hand, for dealing with situations not foreseen in the design and for watching over the quality of the information collected each day. Each of the other members will be responsible for keeping their own field work materials and equipment, acquiring quality information and helping the supervisor check the recorded data.
It is essential that the daily work schedule include an information review session. For this purpose the entire team must meet in order to hand over the filled questionnaires and data sheets to the supervisor and help with the review, ensuring that all the boxes are filled and that inconsistent information is corrected. These end-of-day sessions are also useful for exchanging impressions on the work and for modifying subsequent activities. It is strongly discouraged that these reviews be made several days after the information has been obtained, as passing time clouds the memory.
To ensure that the information collected does not get lost, four recommendations are pertinent: (a) questionnaires and datasheets taken to the field must never be printed with an inkjet printer as the ink runs if it gets wet (photocopies and laser prints are acceptable); (b) only graphite pencils should be used to record data again because any ink will blot; (c) enumerators should keep their questionnaires and datasheets in sealed plastic bags; (d) as soon as possible, all filled in datasheets and questionnaires should be photocopied and taken to the processing office.
As regards the inventory of wood resources, the design and performance of this activity are more complex than surveys of demand and provision. Annex VI therefore provides a rapid guide to the basic tasks involved.
Data processing and analysis must be carried out as soon as the field collection work is complete.
Data entering and processing must begin immediately after collection in the field, while concentration is still high. It is recommended that the data collectors should also enter the data on computer. This is fundamental because any doubts arising over the meaning of replies can be cleared by the very persons who asked the questions or did the measuring.
The data are processed by computer. A personal computer with Microsoft Office is sufficient. It is inadvisable to attempt to develop a specific database or program: the advantage of the possibly greater analytical power of specially devised software is outweighed by the associated cost and time needed for its development, by subsequent dependence on the programmer and by the need to train users. A commercial program such as MS Excel is sufficiently powerful, available worldwide and understood by a large number of people, thus avoiding the above disadvantages.
If it is necessary to train in Excel use, this should focus on learning how to input formulas, use functions, process data, use filters and generate dynamic tables and graphs.
The database is built with Excel spreadsheets9.
Each Excel book will receive the data for one sector of users, traders or producers. The first sheet will contain all the primary data for the sector, including all the strata. This sheet is the Base. The other sheets in the book will be computations, dynamic tables and graphs.
In the case of forest inventories, each sheet can hold the data of a single stratum or even single plot, if there are many data. For other kinds of variables, such as local units, or specific weights, the databases will be formed according to users needs and convenience.
In the spreadsheet each column heading will refer to one variable or reply. With multiple-choice questions, as in the case of species used as fuelwood, how fuel is obtained, etc., a column must be used for each reply (see table).
When entering data, one must be sure that the consecutive number of the questionnaire is first entered, thus facilitating subsequent searches for original data. No codes should ever be used for entering replies because these might be incomprehensible to others using the base or be forgotten with the passage of time. Excel facilitates the entering of complete replies that are repeated, since the program has a memory that enters the possible reply after one or two keystrokes.
For subsequent analyses, it is very important that the syntax of the replies be uniform. For example, entering the same type of reply as Marabú, marabú and marabu will be considered three different replies by Excel.
After data input they must be checked to see if they have been correctly entered. With a limited number of data this can be done by eye, taking great care with the numerical variables. When a large amount of data is being handled, spot checks can be made to detect data out of line. With Excel it is possible to display anomalous data by using the sort function. Some useful procedures for checking, available in simple statistics packages, are frequency distribution, box graphs or stem-and-leaf diagrams. When anomalous outliers are detected, one must refer back to the original questionnaire or data record to identify the nature of the error and decide if it can be corrected.
Once one is sure that the data are correct, the Base spreadsheet is saved and protected against overwriting to prevent unintentional changes.
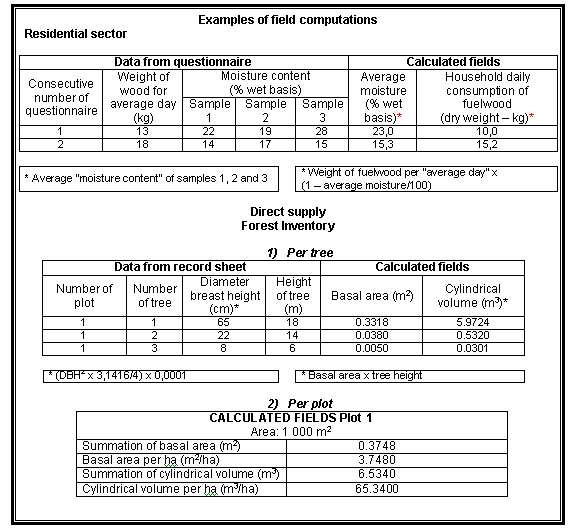
Data processing entails a series of calculations from the data obtained from secondary or primary sources and is expected to produce summary reports of results presented on different scales (sampling unit, stratum and universe). The processing stages are computation and generation of reports of primary and secondary results.
Computation produces a result by processing the numerical data of each sampling unit.
With the data for demand, provision and indirect supply obtained by questionnaire, the computation will be done for each sampling unit (household, establishment, producer). For direct supply (forest inventories) the calculations will be done first for each element within the sampling units (trees in the plots) and then for each plot.
Computations must be done on a different sheet of the same book, copied from the original Base datasheet, with no variable omitted. Having a complete spreadsheet with original and calculated data will enable results to be shown using different variables. To facilitate data management, it is recommended that the calculated data be placed to the right of the last column of variables, and not in the middle. Since the computations of forest inventory entail two stages, the plot-level computations should be presented in a new summary sheet.
The most common computations are shown in Annex VII.
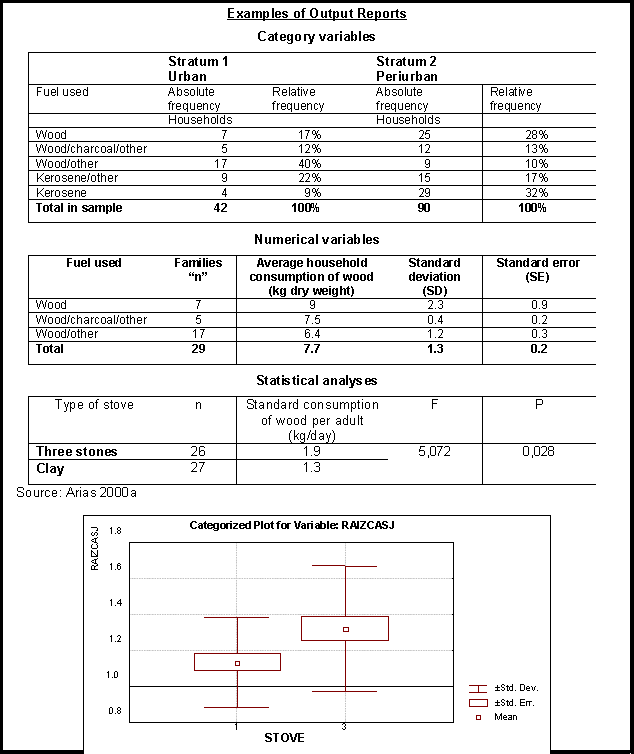
Output reports are summaries of data and computations concerning the sampling units. A most useful tool for generating these reports is Excels dynamic tables. Reports must at all times be kept as print-outs, in addition to digital form, for ease of handling in subsequent analysis.
Output reports from questionnaires on demand, provision and indirect supply should be presented in disaggregated form on different scales: substratum, stratum and universe. They must include:
for categorical variables with ticked box reply: absolute and relative frequency tables;
for categorical variables with open reply: a list of raw replies together with grouping by type of reply;
for all numerical variables and calculated fields: mean, standard deviation, number of cases, and standard error. One can estimate these same statistics for certain categories or groups. For example, average daily household fuelwood consumption by user type (exclusively fuelwood or multiple fuels); diameter of wood according to species, etc;
statistical analyses of comparison of variables that in the first output reports reveal differences according to user group, form of procurement, etc. An example is a comparison of average specific fuelwood consumption as determined by type of stove, which can be done with an analysis of variance or Students t test;
for better visual interpretation, the principal tables of results can be presented as graphs on a separate sheet.
Output reports for direct supply sources, e.g. those generated from inventories of woodfuel resources, are calculated for each land-use or forest type stratum from the final results of sample plots measured in each stratum. It must be remembered that each plot is a sampling unit and that the aggregate of plots constitutes the stratum sample.
These output reports must include: mean, standard deviation, number of cases and standard error, for totals and by diametric class, of the following variables.
number of trees;
basal area (m2/ha);
cylindrical volume (m3/ha);
real volume (m3/ha);
woody biomass in dry weight (t/ha);
woody biomass in local units.
Once the reports of primary results for each stratum or type of resource are ready, they must then be consolidated into a further report, which is the Table of Woodfuel Resources. This is the principal report, which will give an overall view of all wood resources in both absolute and relative terms. The table should include the following columns:
1. type or class of resource;
2. area (ha);
3. mean basal area (m2/ha);
4. mean real volume (m3/ha);
5. wood biomass in dry weight (t/ha);
6. wood biomass in local units (UL/ha);
7. gross stocks expressed in real volume, woody biomass and local units (fields calculated from 1, 3, 4, 5, 6);
8. annual growth rate (coefficient or percent);
9. gross productivity (m3/ha/year, t/ha/year, local unit/ha/year);
10. coefficient of availability (Av);
11. coefficient of accessibility (Ac);
12. net stocks (m3, t, local units/year) = (gross stocks x Av x Ac)
13. net productivity (m3/yr;t/yr;local units/yr) (gross productivity x Av x Ac)
Annex IX shows a specimen of this kind of table. Here the table is static as it shows the situation for a given year. It is also possible to organize it as a trend table, if to the right of the area for each type of use is added a column with the respective rates of change (assessed or assumed). One can then introduce additional columns for each of the future years or other periods, and use simple formulas (linear for short periods, exponential for larger periods) to calculate future stocks and availability. When the data have been processed and subjected to preliminary examination one can proceed to a more thorough examination, i.e. the analysis. This one can be partial or integral. Chapter 5 deals with these procedures in detail and explains how to formulate analyses.
![]()
Essential elements to be included in the final survey report are:
a) Executive summary. The report must begin with a summary of the content to give the reader a general idea of what it is about. It will touch upon the objectives, results, conclusions and recommendations.
b) Introduction. This describes the implementation framework of the survey (participating institutions), the relevance of the survey and related background information.
c) Objectives. These must be stated clearly and concisely, differentiating between general and specific objectives.
d) Methodology. This section should contain a description of the universe of the survey and the criteria for its selection, the complete and detailed sampling design, the tools and instruments used for data collection, field data collection techniques, data processing methods, including the equipment and programs used, and time and cost (in work and money) of conducting the survey in each of its stages.
e) Results. The start of this chapter should specify the thematic areas covered (e.g. saturation, fuel procurement, consumption, means of fuel-burning, environmental impact, etc.). The results should be shown in tables and graphs. Significant results too specific to be included in the tables should be mentioned in the text. The presentation of the results must not be a description of the graphs and tables but, rather, an exercise in analysis, where other relevant elements are included, calling for strong reliance on comparisons with other relevant information. This chapter will have a section on integral analyses (Chapter 5).
f) Conclusions. Conclusions will refer to the objectives of the survey and the most significant results, and never to matters not covered in the study. Conclusions must be presented clearly and succinctly, as the in-depth analysis occurred in the previous chapter, and are best grouped according to general lines of analysis: importance of woodfuel use; economic impact; environmental impact; pattern of provision and consumption; efficiency of stoves; efficiency of fuel use systems, etc.
g) Recommendations. These are meant to guide the decisions of those who will be using the information: energy sector planners, forest public sector and related institutions, fuel users, producers, suppliers and research workers. For this reason the recommendations should tie in with the results and conclusions in addition to being feasible.
h) Bibliography. This is the list of sources of information used for the survey and mentioned in the document, not only books but all sources consulted, including reviews, newspapers, other documents, recordings, personal communications, etc. They should be cited completely and correctly. A selection of publications should be consulted to learn the many ways of doing this.
i) Abbreviations and acronyms. These help comprehension of the text and should all be explained in an introductory section of the report.
j) Units and equivalents. This is an important section for comparing the survey results with other works. It should include both local units and their IS equivalent, and currency units with their rate of exchange in US dollars.
k) Glossary. When a document makes use of specialist technical terms, which is common in this type of study, it is most important to include a glossary. Recommended here is the Unified Wood Energy Terminology (UWET) (FAO, in press).
l) Annexes. This section should include all the texts, tables, graphs, maps, etc. needed to analyse the information in the text but not directly related to the survey results, or materials too bulky to be included in the main text.
9 Excel files are called Workbooks, each composed of one or more worksheets, also called spreadsheets or sheets.