![]()
![]()
![]()
This paper presents the components of the proposed information system and explains the most important elements related to them. This preparatory work, along with the conceptual design, will enable an appropriate system analysis to be undertaken to match the identified functions (in terms of Objectives and Requirements) with the actual products, techniques and data/information available. For a better understanding of the technical terminology used in this report a glossary of computer terms is given in Annex 1.
The primary objective of SIPAL is to provide the AQUILA project, and through it the countries adhering to the project, with an instrument and methodology for rapid and targeted access to data and information of different types and from different sectors and sources. This technology will allow all users to establish their own “made-to-measure” research procedures tailored each time to suit their requirements.
A by-product of this System will be the exchange of data and information between peripherals (Countries/End-user Workstations) and the Workstation (FAO/AQUILA II project) putting in motion a process of feedback. The System will be a strong boost to standardizing the terminology and content (units and measures) in the region.
In order to rationalize the development and implementation of the system, enhance the possibility of its success, increase its use by and interest of all parties concerned, the system will be made up of five Basic Modules (National, Regional, FAO, Extended, Analytical) plus two accessory modules (Data Processing and System Configuration). Hereafter an introductory description of all the above modules is given.
The data/information of each participating country will be accessed through a National Module, whose main function will be to organize the country data coming from various aquaculture information systems or other national source into a structured format. This format will allow easy access and safe transfer and incorporation into the regional aggregated level managed by the Regional Module. Countries which, at the time of development of SIPAL, do not own appropriate databases for aquaculture purposes can utilize, totally of even partially, this SIPAL module which contains the same software developed for the Regional Module with all the typical Data Entry functions.
To permit each country access to the regional data, the project will design and implement a Regional Module and put at the disposal of the countries available information in a readily accessible manner. This module will be fed with non-confidential data and information of regional interest which each country has put at the disposal of the project.
Alongside the regional sub system, the project will develop an FAO-HQ Module containing and managing some of the FAO officially distributed databases. As long as SIPAL is managed under an FAO Project it will be its responsibility to provide/acquire such products.
As complementary data, an Extended SIPAL Module containing information from other data sources external to AQUILA and FAO will be developed. In this Module data from commercial and non-commercial remote networks may also be considered if found necessary and useful for the completeness of SIPAL.
For development of the prototype and as a first test, the Project will contact and make agreement with GLOBEFISH (FAO, Via delle Terme di Caracalla 00100 Rome, Italy) to access its remote database, capture data/information related to aquaculture, and recompile and redistribute them throughout the SIPAL network accordingly.
An Analytical/Modeling Module will be added as a complementary module where several ad hoc software tools especially developed for SIPAL will be collected to assist investment planning, project formulation, project analyses, etc…
The Data Processing Module consists of a collection of tools to enable the user to process and critically analyze the information retrieved through SIPAL. In fact, one of the characteristics of the System is that it will not depend upon pre-determined models. This module will contain the most widely-used basic commercial software which the user might need for carrying out analytical studies and reporting as well as standard routines to perform analysis of particular events, automatic production of bulletins, press releases, and notes. It will include word processing, spreadsheet, DBMS, graphics, and statistical packages, etc…, configured and customized as appropriate.
The System Configuration Module will allow the users to establish their own “madeto-measure” research procedures, to configure the system according to the various hardware/software platforms in which it is installed and to which it is linked and to maintain the system.
The overall SIPAL system will work using data and information in a structured and standardized mode to allow exchange and aggregation for textual, analytical and graphical manipulation.
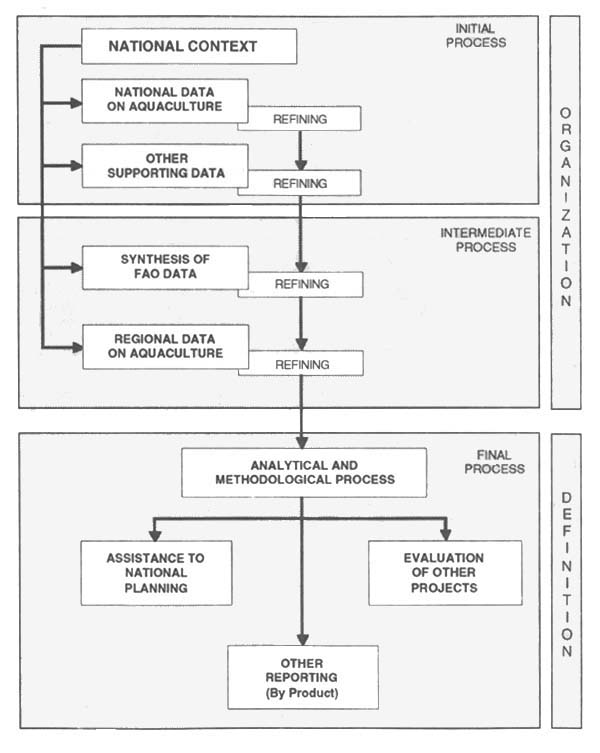
Figure 1 presents the SIPAL System Overview, whereas Figure 2 is an outline of a typical retrieval process around which the system will be designed.
However, all Aquila II country users, regardless of whether they are data donors or information recipients, will be provided with the same information system.
The first qualifying characteristic of the proposed system is the basic role of the end user in its design and implementation. It is emphasized that the system will be mainly designed by the users themselves, based on their concrete needs, and will not follow the normal logic of data dissemination per se.
The second peculiarity is that each country will continue to be free to install and manage its own data bases or information systems. The project may eventually be asked to assist interested countries in developing data entry procedures, or automatic data capture interfaces, in downloading/ uploading national data (manually or automatically) into the regional subsystem.
A third characteristic variable is that countries will not be burdened with requests for additional data collection operations to feed this System. However, it is clear that if a country/institution has no ongoing data collection system covering items of information within a certain application, the Regional Module (aggregation of national information) will not contain its data.
From the information system point of view, SIPAL will be developed into two final versions, with different configurations aiming at covering the two main functions:
One devoted to the National Coordination Workstations, “National Configuration”, in which, among other options, it will be possible to access national information systems through the “National Module” and,
One devoted to the SIPAL Regional Workstation, “Regional Configuration”. The Regional Workstation in this document is temporarily identified as the AQUILA II Project Headquarters, bearing in mind that once the Project is finished, SIPAL should be given a final location. Some of the functions of the Regional Workstation will be the promotion of the System, providing assistance to the participating countries and coordinating its further implementation in addition to the control and recompilation of the data sent from the participating countries, merged with additional information from other sources, all aggregated at regional level and redespatched to the National Workstations and forming the databases.
Figure 1 - SIPAL System Overview
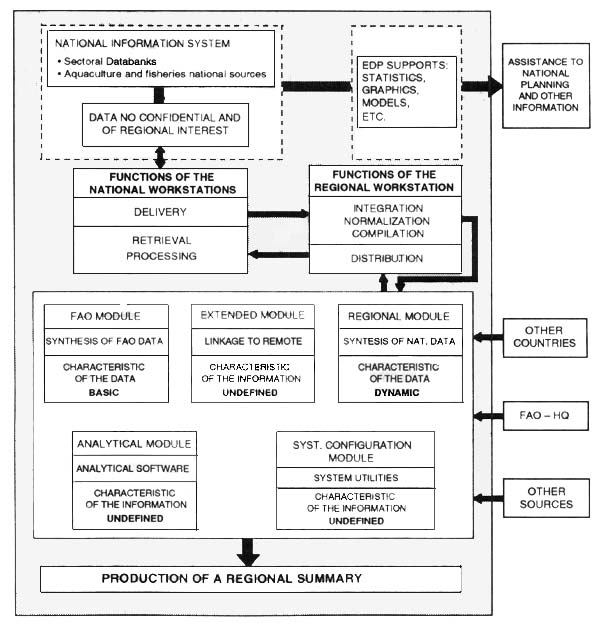
Figure 2 - SIPAL Decision-Making Process
![]()
![]()
![]()