![]()
![]()
![]()
The Food and Agriculture Organization of the United Nations has approximately 200 systems supplying information for access on the World Wide Web, deployed using two different technologies: Microsoft ASP [5] and Java JSP/servlets [20]. These data sources need to share and exchange data between each other in an easy way. However, the use of the two technologies is already widespread in the organization and it is almost impossible to impose a single technology throughout the FAO. In addition, it is necessary to avoid rewriting of existing applications.
The existing information infrastructure is shown in Figure 1. It consists of information sources (database systems) containing different types of data including, but not limited to, different types of documents written in five official languages - English, French, Spanish, Chinese and Arabic (and some in Russian); electronic bibliography references; statistical data; maps and graphics; news and events from different countries; and web information.
Different people generate documents in different formats, which are inserted in the databases using web interfaces. The data is accessed from the databases in HTML format, through applications available on the Internet. Examples of these applications are WAICENT Information Finder (an online search tools), FAOBIB (an online catalogue of bibliography), FAO Virtual Library (a digital archive), and FAOSTAT (an online database about statistics of various areas). The FAO users are farmers, scientists, traders, government planners, and non-governmental people, both inside and outside the organization, that need to access and publish information.
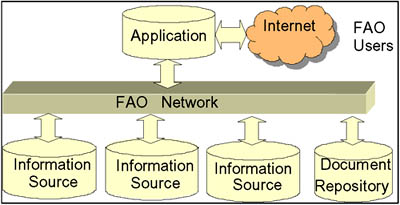
Figure 1: Existing information structure at FAO
Although the existing setting addresses some of the requirements of integrating disparate distributed systems, there are limitations involving budgetary or technical challenges, inflexibility, lack of standardization, and difficulty of scalability and extensibility. It is important to have a technology that is inexpensive, easy to implement, easy to maintain and based on open standards, to allow leverage of knowledge and existing resources without having to rewrite existing applications.
The technology needs to support interoperability of existing data sources and management of multilingual variants without changing the database structures. Currently, it is necessary to customize and add database structures for each different language. There is no standard way to manage language variants of documents or other data structures. This generates inconsistencies between applications in the way that they manage the different languages. In addition, the database models are not easily extensible when new data or language variants are added.
Other problems were related to the support of metadata representation and metadata exchange in a standard way, as well as use of standard ontology formats. In the FAO a document repository has been developed with the objective of storing and disseminating all publications electronically. It stores meeting notes, documents, metadata, and index data.
Different ASP interfaces have been created to allow searching the document repository by type, language, and subject. However, there is no standard way to manage language variants of documents or other data structures like specific country information and metadata. The multilingual Agricultural Thesaurus (AGROVOC) [2] from FAO has been applied to the web as a strategy to ensure some conformity in resource description/discovery. However, it falls short of being a complete tool for this purpose in view of a need for more specific subject terminology and richer ontological relations that are offered by traditional thesaurus.
![]()
![]()
![]()