![]()
![]()
![]()
Text categorization is the process of algorithmically analyzing a document to assign a set of categories (or index terms) that succinctly describe the content of the document [11]. Various methods from different communities have been applied in automatic text categorization approaches, such as classical IR based classifiers, statistical learning classifiers, decision trees, inductive rule learning, expert systems or support vector machines (SVM). More comprehensive surveys of algorithms used for automatic classification can be found in [11], [1], and [12]. One application of text categorization is document indexing, in which several keywords taken from a controlled vocabulary such as a thesaurus or an ontology are assigned to a document in order to describe its subject. Support vector machines have been shown to outperform other approaches [1]. In this research, we therefore use an SVM-based approach to be applied to the multi-label classification problem as described in the following sections in accordance with the definitions given in [12]:
2.1 The classification problem
Multi-Label Classification Problem. In a multi-label
classification problem, each document can be assigned an arbitrary number
m (multiple labels) of n (multiple) possible classes. We have a
set of training documents X and a set of classes C =
{c1,...., cn}. Each document
xi Î X is associated with
a subset Ci Í C
(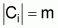 ) of relevant classes. The
task is to find the most coinciding approximation of the unknown target function
) of relevant classes. The
task is to find the most coinciding approximation of the unknown target function
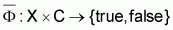 by using a
function
by using a
function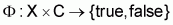 , typically called
a classifier or learned model.
, typically called
a classifier or learned model.
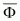 reflects the unknown but
"ideal" assignment of documents to classes.
reflects the unknown but
"ideal" assignment of documents to classes.
In the single-label case, only one class is assigned. The binary classification problem is a special case of the single-label problem and can be described as follows:
Binary Classification Problem. Each of the documents
xi Î X is assigned to
only one of two possible classes ci or its complement
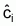 .
.
There are different alternatives towards multi-label document
indexing as carried out in the FAO. In this research we adopted the approach of
transforming a multi-label classification problem into
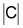 independent problems of
binary classification. This requires that categories be stochastically
independent, that is, for any ci, ck the
value of F (xi,
ci) does not depend on the value of F (xi, ck) and vice
versa. In the case of document indexing at the FAO, this is a reasonable
assumption.
independent problems of
binary classification. This requires that categories be stochastically
independent, that is, for any ci, ck the
value of F (xi,
ci) does not depend on the value of F (xi, ck) and vice
versa. In the case of document indexing at the FAO, this is a reasonable
assumption.
2.2 Binary Support Vector Machines.
Vapnik first introduced support vector machines (SVM) in 1995 [5]. They have been applied to the area of text classification first by Joachims in 1998 [8]. In support vector machines, documents are represented using the vector space model:
Vector Space Model. A document xi is
transformed into a d-dimensional feature
space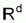 . Each dimension
corresponds to a term (word, also referred to as feature). The values are the
frequencies of the terms in the document. A document is represented by its
word-vector of term frequencies,
. Each dimension
corresponds to a term (word, also referred to as feature). The values are the
frequencies of the terms in the document. A document is represented by its
word-vector of term frequencies,
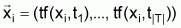 ,
,
where T is the set of terms that occur at least once in
at least one document in the whole set
(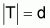 ) and the tf
(xi, t) represent the term frequency of term t Î T in document xi.
) and the tf
(xi, t) represent the term frequency of term t Î T in document xi.
There are a wide variety of weights and ways to choose a term/feature. A more detailed discussion can be found in [12]. In this case, terms (or later concepts from the ontology) are chosen as features and the standard tfidf (Term Frequency Inverse Document Frequency) measure is used as term weight calculated as
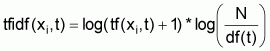 ,
,
where tf (xi, t) is the
frequency of term t in document xi and N is the
total number of documents (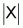 )
and df(t) (document frequency) is the number of documents, a term
t occurred in.
)
and df(t) (document frequency) is the number of documents, a term
t occurred in.
A binary SVM tries to separate all the word vectors of the training document examples into two classes by a hyper plane, maximizing the distance of the nearest training examples. Therefore, it is also referred to as the maximum margin hyper plane. A test document is then predicted by the SVM by determining, on which side of the hyper plane its word vector is. A very good and detailed introduction to SVM and document representations is provided in [14].
2.3 Related approaches
A different approach described in [10] uses a Bayesian classifier together with a document mixture model to predict multiple classes for each document. This approach takes into consideration all classes at the same time as opposed to splitting the whole problem into a number of binary classifiers.
A recently taken similar approach towards multi-label classification using binary classifiers is discussed in [6]. The difference to our approach is that these algorithms can be applied in online settings, where the examples are presented one at a time, as opposed to the batch setting used with support vector machines.
![]()
![]()
![]()