![]()
![]()
![]()
4.1 The test document set
To evaluate this research, a set of training and test documents has been compiled from the agricultural resources of the FAO. Journals, proceedings, single articles and many other resources constitute an extremely heterogeneous test set, differing substantially in size and descriptive content of its documents. The metadata elements of the resources contain a subject element in addition to others such as title, URL, etc. Subject indexing is carried out using keywords from the AGROVOC thesaurus which provides over 16607 potential document descriptors to choose from. A maximum of 6 primary descriptors, describing the most important concepts of a resource, can be used to index a document. Additionally, an indefinite number of secondary descriptors can be chosen, as well as geographic descriptors (for example country information). Only the primary descriptor associations have been considered in this evaluation. Metadata information about FAO documents is stored in any of the three languages English, French and Spanish. The test sets have been compiled with the requirement of having at least 50 documents for each class. Table 1 shows an overview of the so compiled test sets in the 3 different languages.
Table 1: Compiled multi-label test document set in 3 languages
| |
English (en) |
French (fr) |
Spanish (es) |
|
|
Total |
# Documents |
1016 |
698 |
563 |
|
# Classes |
7 |
9 |
7 |
|
|
Class Level |
Max ( |
315 |
214 |
179 |
|
Min ( |
108 |
58 |
58 |
|
|
Avg ( |
145,14 |
77,56 |
80,43 |
|
|
Document level |
Max ( |
3 |
3 |
3 |
|
Min ( |
1 |
1 |
1 |
|
|
Avg ( |
1,25 |
1,40 |
1,42 |
|
4.2 Performance measures
The common notions of precision and recall from the
Information Retrieval (IR) community have been applied to measure performance of
the conducted tests [12]. The initial document set X (pre-classified by
human indexers) is split into a training document set XTr and
a test document set XTe, so
that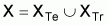 . The corpus of
documents is pre-classified, i.e. the values of the function
. The corpus of
documents is pre-classified, i.e. the values of the function
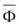 are known for every pair
(xi, ci). The model is built with the
training set and evaluated with the test set.
are known for every pair
(xi, ci). The model is built with the
training set and evaluated with the test set.
Precision and recall are measured for each class and calculated from four different numbers according to Table 2.
Table 2: Contingency table for class ci
|
Class ci |
Expert judgements |
||
|
YES |
NO |
||
|
Classifier |
YES |
TPi |
FPi |
|
NO |
FNi |
TNi |
|
TPi (true positives) is the number of documents correctly assigned to class ci. FPi (false positives), FNi (false negatives) and TNi (true negatives) are defined accordingly.
Overall performance is measured by summing up the values over all classes, and calculates precision and recall according to the micro-averaging approach [12] to:
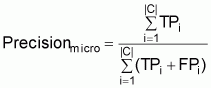
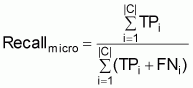
Precision is an indicator of how many of the predictions were actually correct. On the other hand, recall is an indicator of how many of the pre-classified documents have also been predicted, i.e. it provides an indication of how exhaustive the predictions were. Clearly, both figures must be measured to be able to draw a conclusion on performance.
4.3 Evaluation criteria and setup
Within this research work, three different test settings have been carried out:
Single-label vs. multi-label classification. The first evaluation focused on the comparison of single-label classification vs. multi-label classification. For this purpose, a second set of documents has been compiled from the document set shown in Table 1. This time, however, only the first primary descriptor assigned to the document was used, assuming that this is the most important descriptor for the respective document.
One binary support vector machine is trained for each unordered pair of classes on the training document set resulting in (m*(m-1))/2 support vector machines. Each document of the test set is then evaluated against each SVM. A binary SVM votes for the better class amongst the two it can choose from. A score is associated with each class calculated based on the number of votes for the respective class. The score is > 0 if more than 50% of a class’s SVMs have voted for this class. In the single-label case, the class with the best score is assigned to a document. In the multi-label case, we introduced a score-threshold. All classes with a score greater than the score threshold were assigned to a document. Obviously, the number of assigned labels varies with the chosen score threshold.
Because the English document sets provide the most extensive test sets., they have been chosen for this first evaluation, The number of training examples per class has been varied from 5 up to 100. The number of test examples has been held at a constant rate of 50 test documents per class. In case of the multi-label test set, the score threshold has been varied between 0 and 0.6.
Multilingual classification. The second evaluation has been motivated by the idea that support vector machines basically operate independently of languages and document representations. The simplest possible scenario is a classifier that, given an arbitrary document, decides for one of the 3 classes (English, French or Spanish). A very simple document set has been compiled out of the single-label document sets that have been compiled for the previous evaluation, each pre-classified to its corresponding language class (English, French, Spanish) respectively. Each class contains more than 500 documents. The classifier has been trained varying the number of training documents per class between 5 and 200, leaving the number of test documents at a constant rate of 100 test documents per class.
Integration of domain-specific background knowledge. The third and last evaluation tests the effect of integrating the domain specific background knowledge provided by the AGROVOC ontology. The integration of background knowledge is accomplished by extending the word vector of a document with related concepts, extracted from the domain ontology by using word-concept mappings and exploring concept relationships. The necessary steps to integrate the background knowledge are more formally outlined in Hotho et. al. [7]. In our evaluation, we varied two parameters: the concept integration depth, i.e. the maximum depth up to which super concepts and related concepts of a term are included; and the concept integration mode, for which 3 possible options exist:
- Add all concepts found in the ontology to the word vector (add)
- Replace all words in the word vector with corresponding concepts (replace)
- Consider only the concepts found in the ontology, i.e. for each document, create a word-vector only consisting of the domain specific concepts (only)
The idea behind this integration is to move the word vector of a document towards the specific domain and topic it represents, therefore making it more distinguishable from other word vectors. Domain specific background knowledge bares a certain potential to accomplish this task, in a way that it only contains the concepts, which are descriptive for the domain.
In our test case, the AGROVOC thesaurus has been pruned to reflect the domain of the compiled document sets. Pruning in this case means the extraction of only the relevant concepts for a specific domain, thus resulting in an ontology/thesaurus significantly smaller in size. The algorithm used here has been applied in other domains [13] and adapted within the project at the FAO [9].
We evaluated the integration of the pruned AGROVOC on the English document set for the single-label case. Apart from variation of the number of training and test examples per class and all possible concept integration modes, the concept integration depth has been varied from 1 to 2, 1 meaning that only matching concepts have been considered.
4.4 Results
Single-label vs. multi-label classification. For each parameter variation, 15 independent test runs have been conducted. In each run the document set has been split into an independent training and test set. Performance measures have been averaged over all 15 runs respectively.
In the single-label case, precision and recall are always the same and the calculation of both values is not needed. The precision values ranged from 47% (5 training examples per class) to 67% (100 training examples per class). In case of multi-label classification, both precision and recall have been calculated, since here they differ from each other substantially. Keeping the score threshold low implies that many labels - assumingly too many - get assigned to each test document. This results in low precision, because many of the classifications are wrong. However, in that case recall is high because most of the test documents get assigned the labels of the classes they are pre-classified to. Table 3 shows the development of precision and recall depending on the score threshold exemplary for the English set with 50 training examples per class. By raising the score threshold, fewer labels get assigned to each document. In our test cases, precision could go up to as much as 45% and recall plummeted to as low as 76%. In order to make these contradictory effects comparable with the single-label classification, the so-called breakeven value has been computed as the average mean of precision and recall, assuming that both measures are rated equally important.
Table 3: Results of multi-label classification with the English language test set. Development of precision and recall depending on the score threshold.
|
Score Threshold |
Measure |
50 Training Ex. |
|
0.0 |
Precision |
0.2727 |
|
Recall |
0.9329 |
|
|
Breakeven |
0.6028 |
|
|
0.1 |
Precision |
0.2754 |
|
Recall |
0.9350 |
|
|
Breakeven |
0.6052 |
|
|
0.3 |
Precision |
0.3412 |
|
Recall |
0.8721 |
|
|
Breakeven |
0.6066 |
|
|
0.5 |
Precision |
0.4492 |
|
Recall |
0.7618 |
|
|
Breakeven |
0.6055 |
|
|
0.6 |
Precision |
0.4539 |
|
Recall |
0.7702 |
|
|
Breakeven |
0.6121 |
Figure 2 shows all the results in one chart. The Spanish and French multi-label test sets have been additionally evaluated regarding language behaviour of the classifier. The breakeven values are shown depending on the training examples used for building the SVMs. Multi-label classification has shown overall worse performance than the single-label case. However, taking into account the higher complexity of the multi-label problem, the difference comparing the overall results between the two approaches is reasonable. Regarding performance of different languages, we can already infer from the multi-label results that languages different from English seem to perform equally well.
The breakeven values displayed here have been achieved with the overall superior configuration of a score threshold of 0.1. Raising the threshold further always resulted in similar breakeven values. No clear statement can be made on the use of varying the score threshold beyond that value. It depends on the intended goal of applying the classifier. If the classifier is used to help a human indexer by suggesting a large set of possible index terms from which the indexer can choose, then it is clearly advantageous to have a high recall, suggesting most of the ‘good’ terms amongst others. If, however, the automatic classifier is used without human support, it becomes more necessary to limit the risk of assigning wrong labels and aim for high precision. In the latter case, a higher score threshold should be chosen.
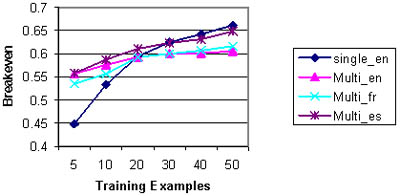
Figure 2: Results single-label vs. multi-label classification
Multilingual classification. The application of the scenario described in section 4.3 resulted in almost 100% precision in all test runs. This clearly shows that support vector machines are able to distinguish almost perfectly between languages.
Integration of domain-specific background knowledge. The integration of the pruned AGROVOC ontology was only able to show a slight increase in precision in the case of adding concepts to the word-vector and replacing words with their respective concepts. However, the performance gains did not show any significance. Figure 3 shows the results for the evaluation runs with 10 and 50 training examples per class. The leftmost values (ontology integration depth 0) display the results without ontology integration as reference. The remainder of the values belongs to each variation in integration mode (add, replace, only) and depth (1 meaning that only the concepts which matched the label have been considered, whereas 2 means that also the direct super- sub- and related concepts have been considered).
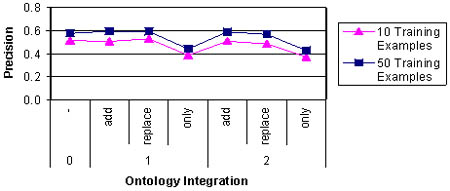
Figure 3: Results of ontology integration with the English single-label test document set.
In the case of totally replacing the word-vector of a document (concept integration mode only), the overall results even slightly decreased. This effect leads to the assumption that the used ontology misses domain specific vocabulary needed to unambiguously define the content of the domain documents. Considering our description of subject indexing made above, a document’s content should be described by leaving out all non-domain-specific concepts.
![]()
![]()
![]()
 )
) )
) )
) )
) )
) )
)