![]()
![]()
![]()
This paper assumes that the unique identifier in a metadata record is the title, since even standard numbers e.g. ISBN, ISSN, are not in every record. With scientific literature, titles are normally unique and provide adequate information for locating a resource.
The method proposed was to take the exact title of a resource, as found in the record, and search it in a general search engine, such as Google. Far from implying that a title search is all that is needed to find a resource, the results in this paper underscore the need for high-quality metadata. The hypothesis is that once a metadata record is found, the title will have sufficient information to find the resource anywhere on the Web. There are many caveats here which are discussed below.
2.1. Google
Google is a popular search tool providing a user-friendly online service to millions of users [5]. It is a large-scale search engine which makes extensive use of hypertext and is claimed to crawl and index the web efficiently providing users with highly pertinent results. During the study, it was observed that Google has a number of limitations, such as, a search limit of 10 words, after which the search terms are ignored [6]. It limits the depth it indexes into a directory structure and therefore some resources that may be available online are not found in Google [7]. The placement of cookies on individual machines for page ranking also affects search results [8].
2.2. Metacrawler
Metacrawler is one of the most popular and widely used "meta" search engines [9]. Unlike Google, it does not maintain its own database of information about sites on the Internet. As an alternative, it searches other search engines, such as, About, Ask Jeeves, FAST, FindWhat, Google, Inktomi, Overture, Teoma; and presents a normalized and uniform set of results, providing searchers with the capability to search multiple search engines simultaneously.
Some of the search engines that are being searched by Metacrawler do not implement exact searches, and therefore, even if a search were done with quotes, the results did not always contain the exact phrase. It is also not able to provide the advance search feature of Google, such as, find results with all the words and find results with exact phrase.
2.3. Cataloguing Rules and their Impact on Information Retrieval
For our test, the specifics of cataloguing rules - normally a highly esoteric affair - take on critical importance. These rules were developed for the AGRIS network and are not based on other standards, such as International Standard Bibliographic Description (ISBD) [10]. Therefore, the structure and information within an AGRIS record can be different from other bibliographic records. Still, there are areas for Titles, Authors, Publication information, and so on.
AGRIS cataloguing rules, also used in FAOBIB, allow for a great deal of latitude. For example, the practice of some libraries in the AGRIS network is to treat the title of the proceedings of a conference simply as Proceedings.[1] This is obviously insufficient information to find a resource. Such titles were excluded from this study.[2]
Another cataloguing rule that could have an impact on information retrieval is that any typographical errors in the title are automatically corrected.[3] There is also the practice of title enrichment. This occurs when cataloguers supplement the title, which "correct the deficiencies and will reflect the content of the document."[4] Either of these practices could lead to difficulties finding a resource using the exact title.
|
English title: |
Development of a research programme in irrigation and drainage in Pakistan |
|
Mon.sec.title: |
Proceedings of a roundtable meeting, Lahore, Pakistan, 10-11 November 2000 |
|
Serial: |
IPTRID Programme Formulation Report (FAO/UNDP/Word Bank/ICID/IWMI). 1020-8348, no. 9 |
|
Corp.authors: |
FAO, Rome (Italy). Land and Water Development Div. |
|
Division: |
AGL |
|
Publ.place: |
Rome (Italy) |
|
Publisher: |
FAO |
|
Publ.date: |
Apr 2002 |
|
Collation: |
164 p. |
|
Languages: |
English |
|
Notes: |
Summary (En) |
|
IC/IY(2): |
XF02 |
|
Categories: |
F06-Irrigation P11-Drainage |
|
AGROVOC main descr.: |
IRRIGATION; DRAINAGE; RURAL AREAS; WATER MANAGEMENT; WATER RESOURCES; WATERLOGGING; SALINITY |
|
AGROVOC geogr. descr.: |
PAKISTAN |
|
Publ.type: |
D |
|
Job No: |
Y3690 |
|
Call No: |
S238 179 |
|
Holding library: |
LIB |
|
Full text: |
English |
|
Acc.No: |
408269 |
|
Database: |
FAOBIB |
Figure 1. Sample Record from FAOBIB
The sample record (Figure 1) provides an example of cataloguing from FAOBIB. In this record, there are three titles: English Title, Title of the Monograph, and a Serial Title. The most unique title here is the English title and therefore was chosen for the study.
2.4. Experiment conditions
We limited the records to items available online in English, French and Spanish, and from these we generated 100 random accession numbers and searched those records. The title of each record was searched in Google and Metacrawler, both as exact phrase and as free-text. The exact phrase search was carried out with initial and final quotes (" ") around the search string while the free-text search involved a search query without the quotes. Therefore, four different types of searches made were: Google Exact, Google Free, Metacrawler Exact, and Metacrawler Free.
Search results were only recorded when they appeared within the top 10 results or when there was a link directly to the resource leading from the first search result. According to this methodology, we could expect that every resource should be found in Google and/or Metacrawler, while the exact phrase search should allow the resource to come up higher in the rankings.
2.5. Analysis of results from FAOBIB
The following graph shows the percentage of resources found for each type of search.
Figure 2. Search results by type of search
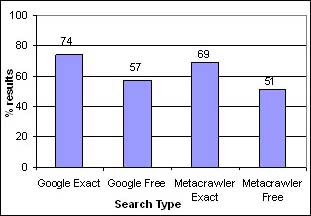
Although 100% of these resources are digitally available, we only found 74% with exact search on Google. The lower success rate for free searches, both on Google and Metacrawler, can be explained by the results not appearing in the top 10 limit. Metacrawler did substantially worse than Google.
The following graph shows the percentage of results yielding the exact resource for each of the three languages (English, Spanish, and French) and for each of the four different searches performed.
Figure 3. Search results by language of the resource
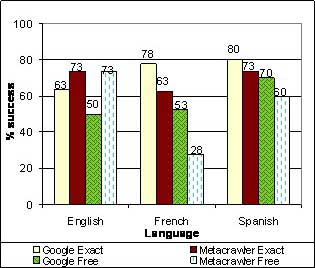
Figure 3 shows the distribution of resources found by language. Again, Google performs better than Metacrawler. It was interesting that on Google, French and Spanish resources were retrieved at a significantly higher rate than English resources.
There were two cases where the results were beyond our limit of 10. We refined the search adding the name of the first author. This resulted in two hits, and in one case, the total number of results retrieved changed from 797 to 22, with the first result being the actual resource.
2.6. Conclusions from the control experiment
Why was our success rate 74%? There could be several reasons for this. Many of the resources searched had deep directory structures and some of these resources may not have been indexed because Google has a limit to the depth it harvests in directory structures. Also, diacritics and corrections to the title may play a part. Some resources could be too new to yet be in Google. The final conclusion was that our method always found the resource when it was in Google, but Google itself is incomplete. The conclusions from the preliminary test can be seen to justify the chosen method.
In the process, we discovered an excellent possibility of finding citations, which is a primary research tool. A full 80% of the exact phrases searched in Google resulted in finding at least one citation. Metacrawler exact, on the other hand, provided 93% related resources but we discovered that the exact phrase search was not adequately reliable to be considered a citation [See section 2.2 on Metacrawler].
Taking into account the results presented in Graph 2, we saw no added benefits of searching in Metacrawler, especially since most of the search results from Metacrawler came from Google. Additionally, there was a major discrepancy between exact phrase searching and free-text searching in Google (74% vs. 57%, respectively). Furthermore, the possibility of searching for citations finally led us to choose only Google exact in the case study of AGRIS database.
|
[1] This is also the practice
in other cataloguing rules. [2] A more complex method may be developed later to search conference names in conjunction with a title. [3] From AGRIS Guidelines (1998), Field 200 Rule 7. In other rules, the practice is to transcribe exactly what is printed, and add an additional title for the corrected title. [4] From AGRIS Guidelines (1998), Field 200 Rule 8. |
![]()
![]()
![]()