![]()
![]()
![]()
2.1 Pruning in a nutshell
Pruning presents a completely automatic bootstrapping approach for ontology development. Input to pruning is an already existing vocabulary (light-weight ontology, thesaurus or taxnomy), which constitutes a light-weight conceptualization.
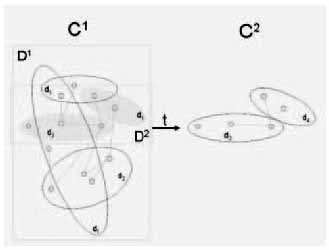
Figure 1: The high-level idea of pruning
The aim of pruning is to automatically extract the subset of the conceptualization which is relevant to the target domain (cf. Figure 1). Naturally, this assumes and requires that the input conceptualization generalizes the target domain.
The decision on whether or not concepts are relevant to the domain is based on a heuristic analysis of document collections. These heuristics operate on a frequency analysis of words that can be extracted from the documents. However, the extraction of relevant terms is based on two sets of documents, one of which contains domain specific documents and the other generic documents. This ensures that we may consider the relative importance of domain terms (wrt. to generic terms) in the pruning process.
Clearly, the identification of a representative set of documents, that represents the domain of interest and that contains concepts relevant to the domain, is central to our approach. Hence, this domain-specific corpus has to be carefully chosen by subject specialists in the area.
The choice of a generic document corpus is deliberate. Generic reference corpora used in the information retrieval community such as CELEX or public news archives have shown to be well-suited in our experiments. As mentioned before, the generic corpus serves as a reference for comparsion with the domain corpus.
2.2 Pruning heuristics
Computing important concepts
The pruning heuristics are based on a frequency analysis of concepts. Concepts are identified in the text via those words, which are used as their lexicalizations. The computation of frequencies for concepts can build on measurements like simply counting the occurrence of words in documents. The latter measure is known as Term Frequency (TF) in the information retrieval community. In our work we also used a more elaborate measurement known as TF/IDF[1] [4], which punishes concepts that occur often in many documents. This is achieved by normalizing the the term frequency number attaching with a term-weighting factor (IDF). For our purpose, we used a weighting factor introduced in [8] which relates the document frequency (DF) of a concept with the size of the document set:
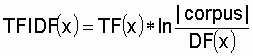
Comparing frequencies
In our approach different comparison strategies can be chosen by the user. First, the user may consider different granularities. The granularity "ALL" compares the frequencies regarding all documents in the respective sets. On the opposite end the granularity "ONE" would consider a domain concept relevant if it occurs more often in some domain document than in any generic document. Other granularities, e.g. comparing the average frequencies, are of course possible but are not yet evaluated.
Second, users may specify a minimum multiplicity factor r, that specifies how much more frequent a domain concept should be compared to a generic concept. Hence, a concept will be considered domain relevant only, if its weighted term frequency is at least r times higher than its counterpart in the generic corpus.
2.3 Concept Acquisition
The ontology pruner has to identify concepts in a document in order to compute concept frequencies. Concepts are linked with (possibly multiple) lexicalizations. Whenever we can identify such a lexicalization in a document the respective frequency of the concept is incremented. This allows to consider synoyms for concepts which are usually available in thesauri. For example, the English word "bank" has at least 10 different senses connoting financial institutions, certain flight maneuvers of aircrafts, etc.
All frequencies obtained for individual concepts are aggregated upwards through the taxonomy to ensure that top-level concepts are properly reflected. Via this aggregation we can ensure that top-level concepts that are usually not frequently used in the texts are not considered as being irrelevant for the target domain.
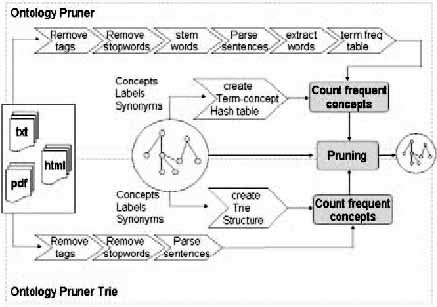
Figure 2: Identification of concepts in text
We evaluated two alternatives for the identification of lexicalizations (cf. Figure 2), one treats documents as a vector of words[2] the other tries to match lexicalizations with document content using a TRIE-based structure [3]. The latter can cope with compound terms such as "food safety" since whitespace can occur within a TRIE path.
In order to cope with different document formats, e.g. HTML or PDF, the first step in the pruning process removes document specific markup leading to a plain text representation. Then a stop-word list is applied to filter out language specific.ll words (such as 'and', 'in', etc.). The remaining steps are specific to each method of concept acquisition.
The vector-based pruner uses shallow natural-language processing techniques to stem words and builds up a concept frequency vector. The word vectors of all documents are assembled into one term-frequency table which is used as a basis for further computations. The identification of concepts is accomplished using a term-concept hash table, which allows to look-up concepts via their lexicalizations.
The TRIE-based pruner incrementally processes each pre-processed document by means of a TRIE data structure. It counts the frequency of respective concepts, whenever a leaf of the TRIE is reached (i.e. a label or synonym has been found in the text). In the current implementation, each occurrence of a lexicalization increases the frequency count of a concept by 1, no matter where the lexicalization appears in the text.
|
[1] Term Frequency/Inverted
Document Frequency [2] each word is separated from others by whitespace or punctuation |
![]()
![]()
![]()