![]()
![]()
![]()
We evaluated the pruning technique within the UN FAO AOS project. The target domain of the output ontology has been biosecurity. This domain involves aspects like food safety, animal health and plant health. We have reused a general thesaurus on agricultural terms as input ontology.
4.1 Pruner Input
Domain Corpus
Three sets of documents have been compiled for evaluation purposes by subject specialists, which capture the above mentioned sub aspects of biosecurity. The domain corpus contains 90 documents and is 9.73 MB large.
Generic Corpus
Two different generic document sets have been compiled:
Generic Corpus 1 (Gen): The first set of generic documents has been chosen randomly from generic news sites and the reuters 21578 test collection [7]. It contains 32 documents accounting a total of 9.55 MB of data.
Generic Corpus 2 (AG): A second generic document set has been chosen to test the behaviour of our approach when comparing the domain corpus with a corpus from a similar domain. This second generic corpus has been compiled out of randomly chosen html news articles from the US Department of Agriculture, documents from different FAO research areas, hence covering a broad range of agricultural topics. This adds up to a collection of 215 documents at a size of about 4 MB.
Input Ontology
We used the UN FAO AGROVOC thesaurus as input for the evaluation (cf. Table 1 for statistics). AGROVOC is a thesaurus and contains 3 relation types, which are frequently instantiated: "related terms" expresses arbitrary relationships between concepts, "used for" expresses that one concepts is used as a descriptor of the hyponym relationship which constitutes a taxonomy. The taxnomy of AGROVOC is a rather.at structure with respect to the high number of concepts, since the maximum depth is 8.
|
Concepts |
Relation Types |
Relations Hierarchical |
Relations Non-Hierarchical |
Relations Related Terms |
Relations Used For |
Maximum Tax. Depth |
|
17506 |
3 |
17168 |
15285 |
13486 |
1799 |
8 |
Table 1: AGROVOC Thesaurus Statistics
4.2 Evaluation Settings
We carried out two evaluations. First, both Vector and Trie-based concept identifications have both been evaluated using corpus Gen with varying frequency weights and granularities. The ratio has been varied using the discrete values (1.0, 2.0, 4.0, 6.0, 10.0, 20.0, 40.0).
The pruned ontology with the highest number of concepts has been chosen for empirical assessment and evaluation by subject specialists. Subject specialists deleted all concepts in the pruned ontology that were not relevant for the domain. This evaluated ontology has been used as the gold-standard ontology. All other pruned ontologies have been compared with it testing the effects of different parameter settings on the filtering of relevant and more specific concepts.
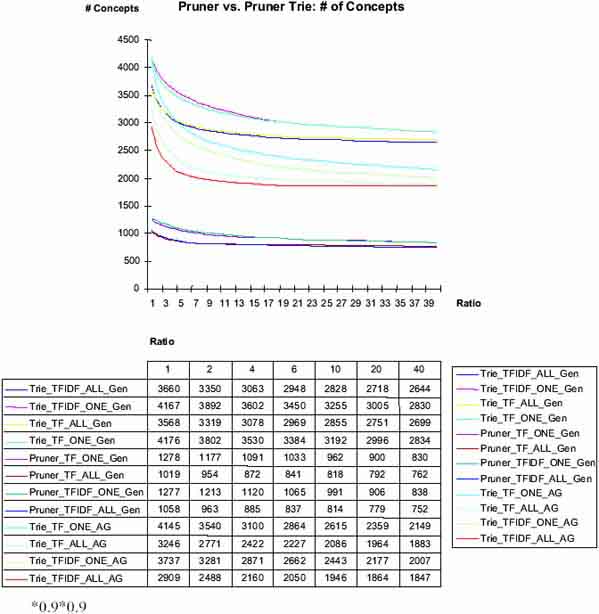
Figure 3: Vector-based vs. Trie-based concept identification
4.3 Statistical Results
Trie vs. Vector-based concept identification
The peformance of both identification techniques is shown in Figure 3. Obviously, 3 clusters or groups of curves can be identified. The upper 4 curves represent the results of the Trie-based concept identification and generic corpus (Gen). The curves in the middle belong to usage of generic corpus (AG), whereas the lower 4 curves show the results of vector-based concept identification.
Subset tests show, that all ontologies obtained via vector-based concept identifications are a total subset of the Trie-based identification. Obviously more concepts can be recognized when compound words can be used.
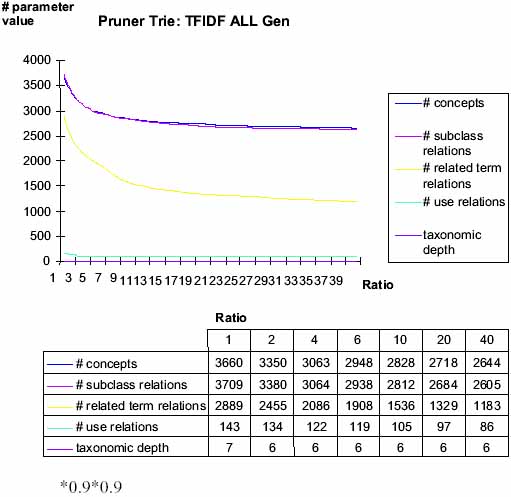
Figure 4: Effects of varying multiplicity ratio
Influence of user parameters
Within all three groups of curves, two sub groups can be identified. Granularity ONE always identi.es more concepts than granularity ALL. The usage of TFIDF vs. TF as frequency measures makes no signi.cant difference in our evaluation. This can be accounted to the fact that both weights are relativized through the comparsion of domain and generic frequencies.
The multiplicity ratio monotonically decreases the number of identified concepts. The minimal set of concepts is constituted by those concepts that can only be identified in the domain corpus and do not occur in the generic corpus at all.
Closer study of the effects of varying the multiplicity ratio (cf. Figure 4) shows that the development of the hierarchical relationships and the 'related terms' relationships almost directly correlates with the number of concepts, whereas the 'use' relationship and the taxonomic depth do not vary significantly, in fact show very little decrease only.
Influence of generic corpora
The use of (AG) corpus leads to smaller ontologies containing an average of 2565 concepts versus an average of 3234 concepts using the Gen corpus. Subset tests show that none of the pruned ontologies resulting from the AG set is a complete subset of its Gen counterpart. On average the AG outputs contain 213 concepts (with a standard deviation of 53) which are not found in the Gen output. On the other hand, an average of 883 (with a standard deviation of 235) concepts have been pruned using AG instead of Gen. This number is quite constantly distributed amongst all outputs. On the other hand an average of 2351 concepts could be identified using both corpora.
![]()
![]()
![]()