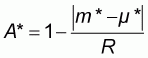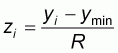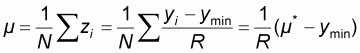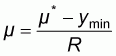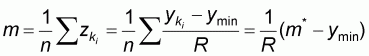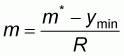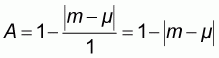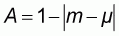![]()
![]()
![]()
Let us assume a finite population of N elements
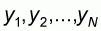 with a minimum value
ymin, a maximum value ymax and a mean value
m* We also consider a random sample
of n elements
with a minimum value
ymin, a maximum value ymax and a mean value
m* We also consider a random sample
of n elements 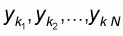 with
sample mean m*. If A* denotes the relative index
of proximity of the sample mean m* to the population mean m* (briefly referred to as accuracy in
the paper), then A* is defined by the following formula:
with
sample mean m*. If A* denotes the relative index
of proximity of the sample mean m* to the population mean m* (briefly referred to as accuracy in
the paper), then A* is defined by the following formula:
|
|
(2.1) |
where R denotes the population range
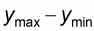 .
.
Generally the range R of a population is not known but this will not affect the study of accuracy since we can always consider the original population mapped onto the standard interval [0, 1] through the transformation formula:
|
|
(2.2) |
In this manner the resulting normalized population
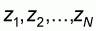 will take values between
and including 0 and 1 and its mean m will
be:
will take values between
and including 0 and 1 and its mean m will
be:
|
|
or, |
|
|
(2.3) |
Any random sample of n elements
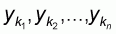 will be mapped into a
normalized sub-set
will be mapped into a
normalized sub-set 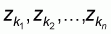 with
mean m given by:
with
mean m given by:
|
|
or, |
|
|
(2.4) |
According to (2.1) and since the range of the normalized population is always 1, the normalized accuracy A will be:
|
|
(2.5) |
which, because of (2.4), (2.3) and (2.1) will be expressed as:
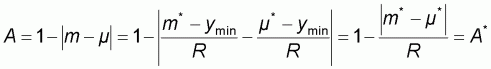
that is the normalized accuracy
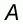 is equivalent to the
original accuracy
is equivalent to the
original accuracy
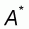 .
.
It can thus be concluded that the accuracy of a sample, when defined as in (2.1), is equal to the accuracy of its mapped equivalent taken from the associated normalized population with values within the interval [0,1].
Having said that and from this point on, all statements and approaches involving population elements, population means, sample means and accuracy indicators will be strictly related to normalized populations. This means that throughout the paper the accuracy of a sample will be expressed in its normalized form:
|
|
(2.6) |
It can be easily shown that the accuracy A, as defined above, has a theoretical lower limit equal to zero and its maximum value is 1, that is:
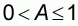
In fact, if we consider the extreme case of a normalized population with the first N-1 elements equal to zero and the N th element equal to one, then its mean will be:
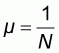
and the worst, or most unlucky sample, will be that with size n=1 and element z=1. The sample mean will thus be m=1. According to (2.6) the corresponding accuracy will be:
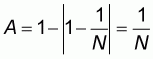
that is, the accuracy A will always be greater than zero with zero as its limit value when N increases indefinitely. The same conclusion is derived if we assume that the first N-1 elements are equal to 1 and the N th element is equal to zero.
On the other hand A can be equal to one when the sample mean coincides with the population mean, as is the case of a sample from a symmetrical population containing an even number of elements that happen to be symmetrical around the population mean.
The concept of sampling accuracy and its definition through expressions (2.1) and (2.6), is of central importance to the subsequent discussions and approaches; it was thus thought that a practical example would assist readers in understanding better its formulation and interpretation.
The first row of the table below illustrates a finite population with size N=8. The second row contains the normalized population elements resulting by applying the transformation formula (2.2).
Table 2.2a
|
N=8 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
y min |
y max |
Range R |
|
y elements |
10 |
45 |
5 |
19 |
8 |
67 |
34 |
11 |
5 |
67 |
62 |
|
z elements |
0.081 |
0.645 |
0 |
0.226 |
0.048 |
1 |
0.468 |
0.097 |
0 |
1 |
1 |
The population mean of the original population is:
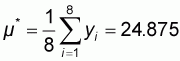
The population mean of the normalized population is:
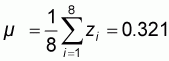
According to (2.3) he normalized population mean could also be computed as:
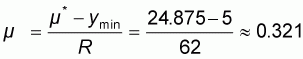 .
.
A random sample of size n=3 and including the elements y2 = 45, y5 = 8, y7 = 34 was taken with the purpose of estimating the population mean. The table below illustrates the resulting sampling accuracy, first computed with the sample of the original population and then with its normalized equivalent given by the second row. The difference between the two accuracy values are due to rounding errors.
Table 2.2b
|
n=3 |
2 |
5 |
7 |
Sample means |
ACCURACY VALUES |
|
|
y elements |
45 |
8 |
34 |
29 |
A* using (2.1): |
0.933 |
|
z elements |
0.645 |
0.048 |
0.468 |
0.387 |
A* using (2.6): |
0.934 |
The sampling accuracy A defined in (2.6) has no units and takes values within the semi-open interval (0, 1]; it can thus be used as a measure of sampling efficiency irrespective of the physical characteristics and distribution of a population.
Furthermore, and as it will be shown in the coming sections, its feasible domain can be determined on an a priori basis; that is in evaluating alternative sample sizes in terms of efficiency, no prior information obtained from experimental sampling is required.
The question now arises as to the practical meaning of A defined in (2.6). A simple way of interpreting A is to assume for an instance that the mean of the normalized population is 0.5. From (2.6) it is evident that a sample at an accuracy level of A= 0.90 will correspond to a sample mean of either 0.4 or 0.6. It is then up to the researcher to assess whether that level of proximity is satisfactory or not. In general, any statement of accuracy desired is equivalent to expressing the amount of error that the user is willing to tolerate in the sample estimates and it is determined in the light of the uses to which the sample results are to be put.
The author recognizes that if compared to other conventional relative indices of accuracy or precision (such as the coefficient of variation), the sampling accuracy as defined in (2.1) and (2.6) tends to provide a rather "optimistic" measure of sampling efficiency, since the sampling error is divided by a much larger value (i.e. the population range). On the other hand the sampling accuracy as defined here would be less ambiguous an indicator than the coefficient of variation which, for two perfectly equivalent samples in terms of sampling efficiency, would tend to compromise the one that underestimates the population mean in favour of the other that overestimates it.
There are other indicators associated with accuracy (such as critical sample size), that can provide some further guidance related to risks due to insufficient sample size or, conversely, excessive data collection effort without visible benefits in terms of accuracy.
![]()
![]()
![]()