![]()
![]()
![]()
KLAUS STERN
KLAUS STERN is research leader at the Institut für Forstgenetik und Forstpflanzenzüchtung, Schmalenbeck, Federal Republic of Germany. Other members of the drafting team were A. de Philippis (Italy) a. Sirén (FAO), L. Strand (Norway), H. Johnsson (Sweden), and R. Toda (Japan).
Population genetics provides good opportunities for planning new breeding programs, or for improving existing programs. In this chapter an attempt is made to describe the main considerations and methods available to the tree breeder and some difficulties which still exist and must be overcome by population geneticists.
The first section describes a mathematical model for natural or indigenous tree populations. This model assumes that the tree population within a given region with relatively homogeneous site conditions may be divided into subpopulations, each of which may be considered as being derived from a random-mating population. This model must be adapted to each particular situation to be realistic. It is believed that the results obtained may be of real help.
Using this mathematical model, certain quantities or genetic parameters can be computed, and this is dealt with in the second section of this chapter. These parameters are:
1. heritability (h²), which is defined as the fraction of the total variation due to genetic causes;2. genetic correlation, which is a measure of the degree of genetic relationships between two or more characters in the same individuals;
3. the coefficient of inbreeding (F), which expresses the deviation of an actual mating system from the mating system of a random-mating population.
The third section of this chapter suggests some ideas on mating designs, field tests, the effects of competition on selection, and the effects of interactions between genotypes and environments on the estimation of heritability. It is shown that mating designs based on diallel crosses give maximum information (the basic type of a diallel cross being the set of all possible crosses among a group of trees to be tested).
In connection with field tests, it is shown that choice of design, plot size, and so on, should change with the kind of experiment if it is to be as efficient as possible. At present, however, information on many problems related to progeny tests is very scarce.
The ways to foster progress in breeding programs and to make maximum use of breeding material are dealt with in the last section of this chapter.
The main conclusion is that forest tree breeders should attempt at present to obtain practical results and estimates of genetic parameters from the same experiments. Because of lack of information it is still not possible to suggest the best breeding procedures. By the use of population genetics, methods may be devised that are relatively efficient.
Factors of evolution and their effects on populations of forest trees
There has been remarkable progress in population genetics and the genetics of quantitative characters during the last few decades, and the results and methods have been widely used in forest genetics. This chapter explains how these results and methods can be applied to the selective breeding of forest trees.
The problem dealt with can be stated in the following way. Consider an economically important tree species with a given range; it is known that there are genetic differences between the subpopulation means of that species, and among trees from the same subpopulation; the intention is to use selective breeding to exploit for practical forestry:
1. the genetic variability between the subpopulations;
2. the genetic variability among individual trees in the same subpopulation.
The first of these two problems will more fully explained in the third section of this chapter but, in discussing the second problem, variation between subpopulations must also be included because the trees the breeder works with are usually selected from different subpopulations.
Genetic differentiation between subpopulations ensues from evolutionary events which lead to the development of the species and continue to influence it. The interest here is in four groups of evolutionary factors:
(a) accidents of sampling;
(b) natural selection;
(c) migration;
(d) introgression.
Introgression will not be considered in detail although it must not be neglected in some cases. There are other factors of evolution which will not be dealt with here. (See especially S. Wright, 1955 and Stebbins, 1950 for a complete survey of evolutionary factors.)
Natural selection and accidents of sampling result in genetic diversification between subpopulations, but migration counteracts this. AU three factors are active at the same time, however, so that the forest geneticist is faced with a population structure which is one stage in a process set in space and time. Normally there is a condition of balance between all three factors, and this balance cannot be far from an equilibrium state which permits genetic differences between subpopulation means because of natural selection and accidents of sampling.
The forest geneticist, therefore, will rarely, if ever, have to deal with a random-mating population. On the contrary, the distribution of genes will show considerable deviations from the Hardy-Weinberg equilibrium. This holds true also for obligate cross-breeding species.
General model of population structure for most tree specks
The variation between subpopulations covering the whole species range, or a large part of it, can be divided into two portions:
1. a component for variation between geographic regions;2. another component resulting from genetic differences between subpopulations within the same region.
The first component will to a great extent reflect the effects of natural selection, while the second may be caused by natural selection or accidents of sampling, or both factors.
In most cases the "between regions" component can also be separated by means of regression techniques (clinal variation, as demonstrated by Langlet, 1936 and in later papers). The remaining variance can then be interpreted in the manner proposed for the "within-regions" component.
It is assumed here that accidents of sampling are the main source of within-regions variance. If natural selection is also a source of within-regions variance, we must assume a random distribution of environments to deal with this variation in a similar manner as the accidents of sampling.
By adopting these suppositions it is permissible to assume that: the subpopulations within a given region car be thought of as a random group of inbred lines derived from the same random mating or tease population.
Tree breeders will always work for certain regions (such as the Wuchsgebiet of Germany and plantagezonen of Sweden). This model for a natural population of a tree species within the boundaries of a region gives the breeder a chance to work with a defined population, which is necessary if he wants to use the methods of quantitative genetics. The boundaries of the "region" in the sense of the definition given above are chosen by considering climatic conditions and the results of biosystematic investigations (Callaham, 1963). If necessary it is possible to correct the boundaries from the results of provenance tests.
Following the definition, the population within the "region" does not have a random mating structure. It is subdivided in several subpopulations differing more or less from the general mean. By assuming that the subpopulations are randomly derived from a common base population and are equally inbred, we may be in a position to overcome this difficulty, as will be shown later in this chapter.
Exceptional population structures in forest, trees
The population model of the foregoing paragraph does not apply if:
1. the species under question propagate" mostly vegetatively, as is the case with willows and poplars;2. the species is self-fertilizing, as most probably happens with the species in tropical rain forests (Baker, 1959);
3. the natural structure of populations has been widely destroyed by artificial regeneration.
In all three cases it is necessary to determine by experiment the conditions with which one has to deal.
Concept of heritability
Consider now a quantitative character showing continuous variation. The expression of this character in a certain individual or in a family is determined by the "genotypic value" of the individual or the family mean, and by the "environmental deviation" by which the performance of the individual or the family differs from the average performance of the whole population, due to differences in environment. The phenotypic performance can be considered as a linear combination of genotypic value and environmental deviation:
P = G + E
If G and E are not correlated, the variance of the phenotypic values is also a linear combination of their variances:
VP = VG + VE
The ratio
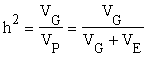
is called the "heritability" of the character in that particular population. Heritabilities can be interpreted as the regressions of genotypic on phenotypic values and this is the reason for the wide use of heritabilities in planning breeding programs.
There are several kinds of heritability. If (VG) stands for the total genetic variance in a population, calculation of the ratio gives the heritability "in the broad sense." If total genetic variance (VG,) is replaced by the variance resulting from additive gene effects (VA), the calculation of the ratio gives the heritability "in the narrow sense" (Lush, 1937 and later papers). In both cases the denominator is total phenotypic variance, which is the sum of total genetic variance (resulting from additive variance, dominance and epistasis of genes) and environmental variance.
Through mass selection and related breeding procedures only the additive genetic variance can be utilized and here narrow sense heritability must be used. Broad sense heritability can be employed if vegetative propagation of selected clones for immediate practical use is possible.
Heritability may be used for the solution of different problems:
1. the heritability that represents the genetic fraction of phenotypic variation between individuals within a population;2. the heritability that represents the genetic fraction of phenotypic variation between families; provenances etc., in a particular field experiment.
In the first case, h² is a parameter of a population; in the second case, it is a parameter of a particular experiment.
Hanson (1961) defines as heritabilities the mathematical expressions which measure the expected progress of selection. His main argument is that the breeder considers heritability for that reason only. Mergen (1960) uses heritability as a measure for "rigidity of genetic control" of quantitative characters. This is another application noting that heritability is always related to a specific population or experiment: h² then expresses the "relative importance" of the genetic sources of variation. Finally, h² can be used as a measure for the efficiency of an experiment (R. L. Anderson, 1960). A list of heritabilities published up to 1963 is given by Hattemer (1963) who also draws attention to several problems in connection with heritability estimation in forest trees.
Combining ability
The concept of combining ability has been defined by Sprague and Tatum (1942) for inbred lines of maize but it is possible to apply it to other material. Combining ability is not an attribute of an individual or a line, but an attribute of the individual or the line and the population of other individuals or lines being investigated. Sprague and Tatum defined combining ability using the model of a two-way analysis of variance which can be adapted to a set of diallel crosses. The yield Yij, of the progeny after crossing the i-th with the j-th individual or line is composed of the average effects (ai and aj) of both lines over all their combinations with the other individuals or lines of the experiment, and a specific deviation, denoted by sij; m being the total mean:
Yij = m + ai + ai + aj + sij
The variance resulting from the ai,s and aj,s is then the variance of "general combining ability"; the variance of sij being that of "specific combining ability."
If the parents are a sample drawn from a randommating population, the variances of general and specific combining ability are estimates of the additive genetic variance and the dominance variance respectively of that population (neglecting epistasis). When selecting several clones for a seed orchard the breeder is mainly interested in general combining ability because he can exploit only additive genetic variance by means of such seed orchard. In other oases, however, it might be possible to use specific combining ability in species such as Betula and Alnus which allow seed production on a large scale from only two clones.
Genetic correlations
Genetic correlation between two or more characters involves two consequences for the tree breeder: he can make use of this correlation by means of the so-called Frühtest or "early test" if the young trees show one of the correlated characters and the other one can only be scored on mature trees. On the other hand, genetic correlation may lead to changes in characters not selected for.
Correlation of phenotypic values does not prove the presence of genetic correlations. Because:
P = G + E
such a correlation may result from a correlation of environmental deviations. Hence, genetic correlation can only be estimated in experiments where G and E are given separately.
Genetic correlations can result from additive, dominant, and epistatic gene effects. Here concerned is only with correlations of "breeding values" which originate additive effects. This type results from pleiotropic gene action in which identical genes affect both characters. (There may also be other genes which affect only one of the two characters.)
Genetic correlation found in a first generation experiment with forest trees can be explained often in other ways. It might result from linkage or from selecting the material from a subdivided population. It is suspected that at least some of the reported cases of genetic correlations in forest trees belong to those two categories. It is difficult to determine the type of genetic correlation on the basis of a one-generation experiment.
In an experiment with two Japanese birch species, Betula japonica and B. maximowicziana, genetic correlation due to subdivision of populations could be excluded. This experiment consisted of a number of single-tree progenies from each of 12 and 16 subpopulations respectively, sampled from the overlapping species ranges. Two characters, time of flushing and cessation of annual growth, were assessed by scoring in a randomized block experiment with four replicates.
Highly significant correlations were found within subpopulations and of subpopulation means in B. maximowicziana, but none in B. japonica. Also in B. maximowicziana a significant mean square of subpopulation means is left after elimination of the covariance. This gives the impression of a linkage correlation. That impression is strengthened by the fact that there are parallel clines for both characters in B. maximowicziana, but in B. japonica a cline exists only for growth cessation (Stern, 1903). Reference should also be made to Kimura (1960) for genetic systems leading to linkage.
Other genetic correlations in forest trees have been reported recently by H. van Buijtenen (1963) and Sakai and Hatakeyama (1963).
Coefficient of inbreeding
A change of the mating system of a randomly mating population leads to inbreeding, which can be measured in a simple way by the "inbreeding coefficient" F of S. Wright (1921) and Malécot (1948).
Inbreeding plays a role also in natural populations of forest trees. This has been frequently investigated since J. W. Wright's (1952) first statement (Langner, 1962, Wang et al., 1060, and others). In a population having the structure described earlier in this chapter, the variation between subpopulations offers a means of estimating the degree of inbreeding. According to S. Wright (1921), in such populations
2 FVA
is the expectation of genetic variance between subpopulations (VA being the genetic variance due to additive gene effects) and
(1 - F)VA
is the expectation of genetic variance within subpopulations, assuming that VA is the preponderant part of VG.
Very little is known about the numerical values F can attain. The data in Table 1 are taken from the two nursery experiments with the Japanese birch species mentioned above. Betula japonica is an "opportunistic" species according to MacArthur (1960) and is expected, therefore, to show a higher degree of inbreeding than the "equilibrium" species, B. maximowicziana.
TABLE 1. - INBREEDING COEFFICIENTS IN SPECIES OF BETULA
|
Characteristics |
Year |
Inbreeding coefficients F as estimated by the two equations given above |
||
|
B. japonica
|
B. maximowicziana
|
|||
| Cessation of growth | 1960 | 0.1215 | 0.0506 | |
|
|
1961 | 0.1248 | 0.0100 | |
| Leafing out | 1961 | 0.0844 | 0.0150 | |
|
|
1982 | 0.1202 | 0.0268 | |
| Height growth until | 1961/1962 | 0.1542 | 0.0497 | |
|
|
1963 | 0.1424 | 0.0346 | |
| Leaf rust, | ||||
|
|
scored in summer | 1960 | 0.1024 | - |
|
|
scored in autumn | 1960 | 0.1030 | - |
|
|
scored in autumn | 1961 | 0.1745 | - |
It is possible to avoid the bias from inbreeding in the estimates of h² if the magnitude of F is approximately known. This bias varies with the procedure used to determine VA and this should be taken into account when choosing the mating design (see below) if the value of F for the population concerned is unknown.
The degree of subdivision of populations within a region is not at present known for any tree species. Only lately tests have been prepared or laid out which will give some information on it and those that are recorded are listed here.
Libby (1962) and Bannister (1963), Pinus radiata;
Zobel and McElwee (1960), Pinus taeda;
J. W. Wright (1961), Pinus silvestris and Pinus nigra;
Langlet (1959) and Kuratorium für Forstpflanzenzüchtung (1962), Picea abies;
Morgenstern (pers. comm.), Picea mariana;
Stern (1961), Betula japonica and B. maximowicziana.
All these experiments recognize that the forest tree breeder needs a more complete picture of the populations to which he wishes to apply the methods of quantitative genetics. The different experimental designs cannot be discussed here although they would reveal the different viewpoints from which such experiments can be started.
Because of the phenomenon known as "inbreeding depression," inbreeding is also important in a breeding program. Only a limited number of individuals can be admitted in each generation and the individuals of later generations thereby become more and more closely related. There are two ways in which the breeder can counteract this development. He can either keep the population fairly large or he can control the pedigrees of the parents in each generation. A large amount of literature exists on inbreeding in forest trees, beginning with Sylvén's (1910) paper, and there is little doubt about its importance. Minimum numbers of clones have been calculated by Stern (1959) while Langner (1961) showed that inbreeding depression in Larix is a linear function of F, as was theoretically expected.
Mating designs
The quantitative genetic parameters of a population can be estimated only from field experiments. Unfortunately it is rarely possible to establish particular experiments for this purpose and it is therefore advisable, at the present time, to lay out field tests to serve several purposes. These are:
1. to obtain information on the general and specific combining ability of parent trees for use in seed orchards;2. to get reliable estimates of genetic parameters;
3. to establish material for further breeding work.
In addition, the test areas must be sufficiently small to keep the costs within tolerable limits.
The first step in planning progeny tests is the choice of a suitable mating design. Mostly the design chosen will be a variant of the diallel table (Andersson, et al., 1961; Zobel and McElwee, 1960 and others). Indeed, a field test with progenies from a diallel cross gives all the necessary information and remains small enough if it is well planned.
The diallel can be complete or incomplete (Hinkelmann 1960). It can take the form of a test-series, containing a few tester clones and a high number of clones to be tested, say b testers B and c clones to be tested C. In such an experiment, planted in randomized blocks, the analysis of variance of plot means will be as shown in Table 2.
TABLE 2. - FORM OF ANALYSIS OF VARIANCE OF PLOT MEANS
|
Source of variation |
Degrees of freedom |
Expectation mean square |
|
Blocks |
r - 1 |
VE + bcVR |
|
General combining ability B |
b - 1 |
VE + rVBC + rcVB |
|
General combining ability C |
c - 1 |
VE + rVBC + rbVc |
|
Specific combining ability |
(b - 1) (c - 1) |
VE + rVBC |
|
Error |
(r - 1) (bc - 1) |
VE |
|
TOTAL |
rbc - 1 |
|
Assuming that the parents in both sets of clones are taken at random from a random-mating population, VC provides an estimate of ¼ of the additive genetic variance VA, and VBC an estimate of ¼ VD of that random-mating population (VD being that part of the genetic variance due to the dominance effects of genes). If the origin of the material cannot be defined in a correct manner, VC may be called the variance of general combining ability of clones of set C.
Accepting the population model given earlier in this chapter, and the selection of clones over a whole region, it can be said that at
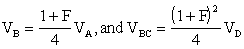
Other situations will not be considered here.
Mating designs other than the diallel gross have been suggested. Gustafsson (1949) recommends a pollen mix as the tester parent. Assuming a random-mating population, the variance of family means then gives an estimate of ¼ VA. Schröck in a personal communication uses a single tester as pollen source or female parent. The variance of family means is then ¼ VA + ¼ VD, provided that the population has a random mating structure.
Single tree progenies derived from open pollination should give the same between-families variance as Gustafsson's polycross. But here the assumption of random pollination seems to be rather precarious (Squillace et al., 1961).
The tree breeder should choose mating designs carefully. Already at this early stage he is deciding on the kind of information he will get in the future, on the size of the field test, and on the possibilities of further work with progenies from the experiment.
Another method of obtaining estimates of VA is given by the fact that the regression of the expression of a character in parents and offspring is completely due to VA. Finally, Shrikhande (1957), Sakai and Hatakeyama (1963) and Freeman (1963) all present a new method enabling the tree breeder, under certain circumstances, to estimate genetic variances and genetic correlations in even-aged stands without raising progeny.
Field experiments
The choice of field design, plot size, and number of replicates all determine the efficiency of an experiment, that is, the amount of information that will be obtained. Thus far there are not many data on the efficiency of field tests with forest trees but the studies of J. W. Wright and Freeland (1960), Evans et al. (1961), and Strand (1955) all confirmed that the basic assumptions of Andersson et al. (1951) were correct.
For different characters different error variances are to be expected from the same test. The heritabilities given in Table 3 were obtained from a test with 100 provenances of Picea abies. The design was a simple lattice with 4 replications; plot size 5 by 5 plants; spacing 1.1 x 1.1 meters (3 feet 6 inches x 3 feet 6 inches).
TABLE 3. - HERITABILITIES DERIVED FROM A PROVENANCE - TEST OF PICEA ABIES
|
Character |
Number of replications |
|||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
Leafing out in 1962 |
87 |
93 |
95 |
96 |
97 |
98 |
98 |
98 |
|
Damage by spring frost 1961 |
93 |
97 |
98 |
98 |
99 |
99 |
98 |
99 |
|
Height growth 1962 |
39 |
67 |
66 |
72 |
77 |
79 |
82 |
84 |
|
Prolepsis formation 1962 |
39 |
56 |
66 |
72 |
70 |
79 |
82 |
84 |
One single replication would give 87 and 93 percent of available information in the case of leafing out and frost damage, respectively; but height growth and prolepsis formation show much lower heritabilities. Only with 8 replications would 84 percent heritability be achieved. These figures were obtained without consideration of the incomplete blocks. Eliminating the variance among them, the efficiency would reach 156 percent against that of randomized blocks.
It is desirable that, following the proposals of Evans et al. (1961), all available results of field tests should be collected and assessed for information on the optimum size of plots, number of replications and so on. Furthermore, there should be more uniformity trials similar to those of J. W. Wright and Freeland (1960) or Strand (1966) at different locations and with other tree species. It should then be possible in a few years to accumulate sufficient material for planning field tests.
Interactions of genotype and environment
The tree breeder works in a region or selects trees in regions which are to some degree heterogenous in soil and climate. Furthermore, the weather changes from year to year, and in years with extreme conditions the results of many previous years can be reduced in value. The breeder has to take into account the fact that different genotypes may react differently in different environments. He will have to repeat his tests on several sites and, if possible, over several years. Such a test series, an A x B diallel over 1 location with r replications, each in a randomized block design, has the expectations shown in Table 4.
TABLE 4. - FORM OF ANALYSIS OF INTERACTIONS OF GENOTYPE AND ENVIRONMENT
|
Source of variation |
Expectation mean square |
|
A |
VE + rVABL + rlVAB + rbVAL + rblVA |
|
B |
VE + rVABL + rlVAB + raVBL + ralVB |
|
A x B |
VE + rVABL + rlVAB |
|
L |
VE + rVABL + rbVAL + raVBL + rabVL |
|
A x L |
VE + rVABL + rlVAB + rbVAL + rbVA |
|
B x L |
VE + rVABL + raVBL |
|
A x B x L |
VE + rVABL |
|
R within L |
VE + abVR |
|
E |
VE |
The heritability must then be taken over all locations. For example, if the sample A consists of the clones to be tested:
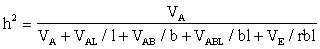
The test sites should not be chosen at random as frequently happens. The most important site types should be preferred.
Unfortunately, there are few data about genotype x environment interactions in field experiments with material derived from selective breeding in forest trees, and these data are not very reliable.
Competition
Competition is the mutual influence of trees within stands and it has the following consequences for tree breeders.
1. The selection of plus trees becomes unreliable for characters affected by competition.2. Estimates of combining ability and genetic variances are biased to some degree because of competition within and between plots.
The phenomenon of competition has not been sufficiently understood until now, in spite of some fundamental papers referring to it (Sakai, 1955; Symp. Soc. Exp. Biol. Cambr. 1961).
Partly because of competition the heritabilities of growth obtained from parent-offspring regressions are considerably smaller than those from half-sib or full-sib analysis. It can be assumed that the latter heritabilities are more reliable.
Competition in progeny tests is difficult to assess. If the families are planted in plots it is mostly half-sibs or full-sibs that compete with each other. On the other hand, the progeny of a seed orchard for which selection has been made consists of practically unrelated individuals and the competition is of a different kind. For this reason most tree breeders dispense with the isolation strips and large plots usual in other branches of forest research.
The results of Snaydon (1961) show that it is necessary to consider the competitive ability of different genotypes. He found no differences between ecotypes from different soils if grown in plots. But an ecotype on its own soil was always superior when grown in competition with the others. Older experiments by Sukatschew (1927) point in the same direction. Sub division of populations within a region, therefore, may be caused partly by competition.
Recently, Toda (1963) has presented a new and promising method for the estimation of heritabilities in the presence of competition. There should be more basic research on this problem, which is of vital importance not only for forest tree breeding but also for other aspects of forest research and practice.
Meaning of genetic gain
A new population comes into existence by selection. The average genetic value of this population deviates from that of the original population. This difference is the "genetic gain" specific for the method and intensity of selection used in a particular breeding program. It is, of course, the intention of every breeder to make this difference as large as possible.
Three factors determine the gain obtained or expected:
1. the genetic variance which is the basis of any selection;2. the accuracy of estimates of breeding values either in selection of superior individuals in a stand or of families in an experiment, as expressed by the heritability;
3. the intensity of selection, that is the difference between the population mean and the average of the selected individuals.
It can be shown that under certain conditions the genetic gain R is given by the following equation:
R = h2 S
where S is the difference between the means of the original and selected populations. This is the basic formula for all estimates of expected genetic gains.
Selection indexes
The economic value of a cultivar is determined by several characters. Hence, it is necessary to look for a selection procedure that takes account of the complexity of the situation and gives the best possible results, not for a single character but for the whole complex of characters making up economic value. The most promising procedure seems to be the selection index and the most complete survey of the problem has been given by Le Roy (1960).
In constructing selection indexes it is necessary to combine the economic values of the separate characters, their heritabilities and their correlations with other characters of economical importance. It is understood that genetic correlations are only available after comprehensive progeny tests. Assume a selection program in which the breeder selects for characters x1, . . ., xn. It is further assumed that the heritabilities, the genetic correlations, and the economic weights of all characters are known. It is possible to combine all this information in a single "index" which takes the form of a multiple regression but is calculated in a different manner (see Le Roy 1960, for details):
I = b1x1 + b2x2 +... bnxn
The b1 ... bn are the weights of the single characters and a character of high economic importance has a high weight. But this can be counterbalanced by a low heritability or by negative genetic correlation with other characters of economic importance. The bi . . . bn, therefore, are calculated using both economic and genetic information.
The equation for determining genetic gain applies also for index selection, that is selection for high values of I. Nevertheless the problem of determining the optimal selection procedure for a given set of economic weights and population parameters is difficult to solve in some instances. There have been successful attempts in animal breeding to approach it by using high speed computers and model populations. A similar approach might also be promising in solving certain problems of forest tree breeding.
The economic value of a character is certainly problematic; it alters with changing market conditions. But it should be possible to give an economic weighting to the several characters combined by the index. Fast growth, straight stems, good natural pruning and so on, are characters which are expected to maintain their values for a long time.
The demand to include as many characters as possible in the index is countermanded by the fact that the intensity of selection for the others is lowered by every new character considered. Therefore the breeder has to restrict the number of characters he is selecting for and this stresses the necessity of a deliberate weighting to choose the most important characters.
Thus far only one "real" selection index has been constructed for use in forest tree breeding by J. P. van Buijtenen and van Horn (1960). But the scoring systems used by most tree breeders are also selection indexes. The construction of the indexes, and their continuous adjustment to market conditions, is one of the most important problems of tree breeders. A solution of that problem can only be obtained by close co-operation with forest economists.
Since the heritability of a character can be low in stands but high in a well-planned field experiment, the weight of this character will be different in a selection index calculated to maximize gain by plus tree selection when compared with a second index referring to the same character and to the same population but to selection on the basis of progeny tests. A good example of this is given by Nixon and Moffet (1963).
Factors determining genetic gain
It is the aim of every breeder to make the widest possible use of available facilities. Usually this is identical with the aim of achieving the largest generic gain (in the index values) per unit of time. With annual plants and also with many animals the unit of time is taken as one generation, but with forest trees the generation is a variable period. Its length is determined by:
(a) the time from pollination to seed collection, which may be two or even more years;(b) the time from collecting seed to the end of the field tests, which will vary considerably;
(c) the time needed to apply the results of selection in forest practice.
The breeder tries, of course, to shorten each period as much as possible. He might be able to combine several measures during the different periods. Assuming that each step in selective breeding is followed by others, it becomes necessary to estimate also the possible progress of further steps. Therefore a multitude of facts besides the selection index must be taken into account since they also influence the success of a selection program. It seems that we are at the beginning as far as this kind of consideration is concerned.
Early testing
Characters with high heritability in the narrow sense can be selected for by selection of plus trees. In such a case high selection differential guarantees fast progress through mass selection without progeny testing.
The situation is different when selection for several characters is reliable only when based on progeny tests. Because of the high costs of such tests, it is desirable to restrict them to practicable sizes, although the chance for high selection differential is probably lost in smaller tests. Attempts have therefore been made to use genetic correlations between characters of young plants and those scored in the later stages of tree development, for indirect selection. (See Schmidt 1957 for a summary of this work.)
The success of such indirect selection as compared to that of direct selection can be estimated as follows (Falconer, 1060):
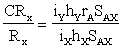
In this equation CRX stands for the correlated response to selection for y in x, RX for the response to direct selection for x, iK and iX for selection intensities for y and x respectively, hX and hY for the square roots of the heritabilities, rA for the correlation of breeding values in x and y, and SAX for the genetic standard deviation of breeding values of x.
The statements about genetic correlations made earlier in this chapter also hold for "early tests." In particular, it must be remembered that correlations arising from linkage change from generation to generation, and that correlations arising from the subdivision of populations are of no use for indirect selection within subpopulations.
Seed orchards
During the last few years there have been discussions about the most appropriate type of seed orchard. In particular, J. W. Wright (1959) and Goddard and Brown (1961) have drawn attention to seedling seed orchards, established by discarding all but the best trees in the best progenies of progeny tests. This concept of a seed orchard is quite different from that of the clonal seed orchards developed particularly in Sweden.
The object of this chapter has been to show that a large amount of information is required for the deduction of the most profitable selection procedure. It would be surprising if sufficient data were available now for any selection program in a forest tree species, and in particular:
(a) heritabilities for stands and certain types of progeny tests;
(b) genetic correlations of the most important characters;
(c) effects of inbreeding;
(d) genotype x environment interactions;
(e) economic weights of important characters;
(f) time needed for each step of the program.
At present it is necessary to guess or estimate these data subjectively and this seems a doubtful procedure. An experimental procedure which leads to the selection of superior material and provides estimates of genetic parameters seems to be the most promising.
In addition it is hardly possible to assume a standard type of clonal seed orchard for all species and breeding programs and the Swedish concept is a very flexible one. Much can be achieved by choosing a suitable timetable and the methods of quantitative genetics may help in doing this. At present the value of quantitative genetics lies in providing a base for planning experiments efficiently in the first stages of selection programs.
ANDERSON, R. L. 1960. Uses of variance component analysis in the interpretation of biological experiments. Bull. Int. Stat. Inst. 37. 22 P.
ANDERSSON, E., GUSTAFSSON, A. & JOHNSSON, H. 1951. Avkomme-prövning i skogsbrukets tjänst [Use of progeny trials in forestry]. Norrlands Skogsv. Förb. Tidskr., 4: 37-409.
BAKER, H. G. 1959. Reproductive methods as factors in speciation in flowering plants. Cold Spring Harbor Symp., 24: 177-191.
BANNISTER, M. H. 1963. Planning a genetical survey of Pinus radiata populations. FAO/FORGEN, 63-5/1.
BUIJTENEN, H. VAN. 1963. Heritability of wood properties and their relation to growth rate in Pinus taeda. FAO/ FORGEN, 63-7/2.
BUIJTENEN, J. P. VAN & HORN, W. M. VAN. 1960. A selection index for aspen based on genetic principles. Prog. Rep. No. 6, Lake States Aspen Gen. and Tree Impr. Group, Appleton, Wisconsin.
CALLAHAM, R. Z. 1963. Provenance research. FAO/FORGEN, 63-3/0. (Chapter 4)
EVANS, T. C., BARBER, J. C. & SQUILLACE, A. E. 1961. Some statistical aspects of progeny testing. Proc. 6th Southern For. Tree Impr. Cont., p. 73-79.
FALCONER, D. S. 1960. Introduction to quantitative genetics. New York, Ronald Press; Edinburgh, Oliver & Boyd.
FREEMAN, G. H. 1963. The combined effect of environmental and plant variation. Biometrics, 19: 273-277.
GODDARD, R. E. & BROWN, C. L. 1961. An examination of seed orchard concepts. J. For., 59: 252-256.
GUSTAFSSON, A. 1949. Conifer seed plantations. Their structure and genetical principles. In Proc. 3rd World For. Congr., Helsinki, p. 117-119.
HANSON, W. 1961. Heritability. Symp. on Statistical Gen. and Plant Breeding, Raleigh, N. C.
HATTEMER, H. E. 1963. Estimates of heritability published in forest tree breeding research. FAO/FORGEN, 63-2a/3.
HINKELMANN, K. 1960. Krenzungspläne zur Selektionezüchtung bei Waldbäumen. Silvae Genet., 9: 121-148.
KIMURA, M. A. 1960. Model of a genetic system which leads to closer linkage by natural selection. Evolution, 14: 278-287.
Kuratorium für Forstpflanzenzüchtung. 1962. Vorschlag für einen Fichten Herkunts-Versuch. Mimeogr.
LANGLET, O. 1936. Studien über die physiologische Variabilität der Kiefer und deren Zusammenhang mit dem Klima. Beiträge zur Kenntnis de Ökotypen von Pinus sylvestris L. Medd. Statens skogsforskn. Inst. Stockh., 29: 219-470.
LANGLET, O. 1959. Skogsforskningens nya granproveniensförsök [New experiments in spruce provenance research]. Skogen (18): 370-371.
LANGNER, W. 1952-53. Die diagnostische Bedeutung eines aurea Faktors bei Picea abies für die genetisch wirksame Pollenverteilung. Z. Forstgenet., 2, 21-22.
LANGNER, W. 1961. Einige Versuchsergebnisse zum Inzuchtproblem bei der forstlichen Saatguterzeugung. Proc. 6th IUFRO Congr., Vienna.
LE ROY, H. L. 1960. Statistische Methoden de Populationsgenetik. Basel und Stuttgart, Birkhäuser.
LIBBY, W. J. 1962. Research proposal. Mimeogr.
LUSH, J. L. 1937. Animal breeding plans. First ed. Ames, Iowa State Coll. Press.
MACARTHUR, R. 1960. On the relative abundance of species. Amer. Nut., 94: 25-34.
MALÉCOT, G. 1948. Les mathématiques de l'hérédité. Paris, Masson.
MERGEN, F. 1960. Variation and heritability of physiological and morphological traits in Norway spruce. Proc. 5th World For. Congr., Seattle, US.A.
NIXON, K. M. & MOFFETT, A. A. 1963. One part progeny testing in black wattle (Acacia mearnsii, de Wild). FAO/FORGEN, 63-2a/5.
SAKAI, K. I. 1955. Competition in plants and its relation to selection. Cold Spring Harbor Symp., 20: 137-157.
SAKAI, K. I. & HATEKEYAMA, S. 1963. Estimation of genetic parameters in forest trees without raising progenies. FAO/FORGEN, 63-2a/4.
SCHMIDT, W. 1957. Die Sicherung von Frühdiagnosen bei langlebigen Gewächsen. Züchter, 4, suppl.: 39-69.
SHRIKANDE, V. J. 1957. Some considerations in designing experiments on coconut trees. J. Indian Soc. Agr. Stat., 1: 82-88.
SNAYDON, W. R. 1961. Competitive ability of natural populations of Trifolium repens and its relation to differential response to soil factors. Heredity, 16: 522.
SOCIETY OF EXPERIMENTAL BIOLOGY, CAMBRIDGE. 1961. Competition and co-operation. S.E.B. Symp. 15.
SPRAGUE, G. F. & TATUM, L. A. 1942. General versus specific combining ability in single crosses of corn. J. Amer. Soc. Agr., 37: 923-932.
SQUILLACE, A. E. & BENGTSON, G. W. 1961. Inheritance of gum yield and other characteristics of slash pine. Proc. 6th Southern Tree Impr. Conf., p. 85-96.
SQUILLACE, A. E. & DORMAN, K. W. 1961. Selective breeding of Slash pine for high oleoresin yield and other characters. Abstract in Proc. 9th Int. Bot. Congr., Montreal, Vol. 2 (375).
STEBBINS, G. L. 1950. Variation and evolution in plants. New York, Columbia University Press.
STERN, K. 1959. Der Inzuchtgrad in den Nachkommenschaften von Samenplantagen. Silvae Genet., 8: 37-42.
STERN, K 1961. Preliminary estimates of the genetic structure of two sympatric populations of birches as determined by random effects and natural selection. Proc. 9th Northeastern Tree Impr. Conf., Syracuse, N. Y., U.S.A., p. 25-34.
STERN, K. 1963. Über einen Altitudinalklin in zwei japanischen Birkenarten. Festschrift der Darre, Laufen/Obb. (In press)
STRAND, L. 1955. Plot sizes in field trials. Z. Forstgenet., 4: 156-162.
SUKATSCHEW, W. N. 1927. Einige experimentelle Untersuchun gen über den Kampf ums Dasein zwischen Biotypen derselben Art. Z. Ind. Abst. Verb. Lehre, 47: 54 p.
SYLVÉN, N. 1910. Om pollineringsförsök med tall och gran [Experiments in self-pollination with pine and spruce]. Medd. Statens skogsförsöknsanstalt, 7: 219-228.
TODA, R. 1963. Mass selection and heritability studies in forest tree breeding. FAO/FORGEN, 63-2a/2.
WANG, C. W., PERRY, T. O. & JOHNSSON, A. G. 1960. Pollen dispersion of Slash pine (Pinus elliottii) with special reference to seed orchard management. Silvae Genet., 9: 78-86.
WRIGHT, J. W. 1952. Pollen dispersion of some forest trees. Northeastern For. Exp. Sta. Paper No. 46.
WRIGHT, J. W. 1959. Seed orchards or test plantings ? In Recent advances in botany. Univ. of Toronto Press.
WRIGHT, J. W. 1961. Geographic variation patterns in forest trees. 2nd Central States For. Tree Impr. Conf., Franklin Park, III: 15-20.
WRIGHT, J. W. & FREELAND, F. D. 1960. Plot size and experimental efficiency in forest genetic research. Mich. State Univ. Agr. Exp. Sta., Tech. Bull. 280. 28 p.
WRIGHT, S. 1921. Systems of mating. Genetics, 6: 111-178.
WRIGHT, S. 1955. Factors of evolution. In Cold Spring Harbor Symp., 20: 16-24.
ZOBEL, B. & MCELWEE, R. 1960. Plans for progeny testing seed orchards. Mimeogr.
![]()
![]()
![]()