![]()
![]()
![]()
Individual differences
If we look at the length distribution of fish of a given year-class, all of approximately the same age, we will see that they are not all the same length. Typically the lengths will have something like a normal distribution about some mean length, with quite an appreciable standard deviation. Some of this spread will be because fish do not spawn at exactly the same time, and fish spawned at the beginning of the spawning season can be expected to be somewhat bigger than those spawned later. One element of the complete ELEFAN package uses this argument to obtain, essentially by extrapolating the observed distribution of length-at-age, an estimate of the distribution of the time of spawning through the year.
Differences in spawning time cannot be the whole explanation for differences in length-at-age, otherwise the spread of length would decrease as the fish grow older, and a few weeks difference in real age makes less difference to the length. Also information on growth increments, e.g., from tagging, show considerable differences. It is clear that there can be appreciable differences in the growth of individuals. A minor consequence of this is that the ELEFAN method of determining the time of spawning should be used with caution. The conclusions are likely to be sound if they are based on the seasonal pattern of abundance of the smallest fish (which requires that samples are taken in most months of the year), but risk being misleading if based on lengthy back-extrapolation from the larger fish.
More serious consequences have been pointed out by Sainsbury (1980) and others. If individual fish grow at different rates, which may be described by differences in the growth parameters K and Linf, then the results obtained from many analyses will not be the same as those that would be obtained if all fish grew at the same rate, described by the parameters K and Linf, where these are the means of the individual values of K and Linf. For example, if we are considering the growth of tagged fish, and applying the common method of plotting the increment in size between tagging and recapture, it will happen, if fairly big fish are being tagged, that the bigger fish will be those that have the larger values of Linf. These will grow more than expected, and the increments will decrease less than expected. The question of examining the individual variability in K and Linf is now receiving more attention (Burr, 1988). While it is clear that anyone using length-based methods must recognize this variability, present techniques for estimating it have not reached the level of being routinely applied.
The errors introduced by ignoring individual differences in growth are small in the traditional age-based methods, looking for example at the mean length-at-age, but can become large for some of the length-based approaches. The precise effects are discussed later in respect of particular methods; the point to be made here is that, when using length-based methods, consideration will often have to be given to the degree to which individual fish can have different growth rates.
Finding a time-scale
When we use length data to estimate growth we are trying to determine a time-scale from a set of data in which there is no explicit information about time. Our success in doing this depends on how much signal about time is available in an implicit form in the data. This essentially means what changes there are from one moment to another, as reflected by differences in samples taken at different times. The first step in any method of growth estimation is to look at samples taken at different times. The greater the difference, and the more the differences fall into a logical pattern, the more “signal” (to use a term common in information theory) there is, and the more chance we have of estimating growth, provided a suitable method is used. Conversely, if there are few changes from time to time, there is little signal and we may not be able to estimate growth, however cunning the methods used.
The change that is most often apparent is that a peak (or sometimes two or more peaks) can be detected among the smallest fish (corresponding to the youngest well-recruited age group), which moves up month by month until after a year a new peak becomes apparent, and then, or later the larger peak becomes indistinguishable among the larger fish (Fig 3.1). A simple method of estimating growth (and one of the oldest) is then to assume that each identifiable peak corresponds to the mean length of a year-class, and to fit a growth curve to these means. The mechanics of methods of this type can be considered in two stages - identifying the modes and fitting the curve.
The position of the modes does not tell us everything about a length-frequency, and by just using the modal lengths we are throwing away information about the shape of the distribution between the modes which might help us to estimate a growth-rate. A set of alternative methods have been developed that consider the frequency-distribution as a whole. By seeing how this changes from month to month and comparing these changes with those expected with different growth-curves, the curve that gives the best fit can be determined.
Finally, we must remember that any one method will seldom have to be used in isolation, and the estimates of growth can often be improved by looking at additional information, especially when this has a clear time-scale, e.g., the growth of tagged fish, or a few age-determinations insufficient by themselves to determine a growth curve.
The simplest way of identifying modes is simply to plot the length-frequency of a sample and see what modes are visible. This procedure dates back to the earliest application of length methods by Petersen (1891) and should always be the first step in analysis. If several modes can be distinguished, and this can be done for several months during the year, then it should be possible to read off the modal values by eye, and fit a growth curve to those values. Not only will this provide a quick estimate of growth, but the values obtained can be used as first estimates in the more objective methods, and thus often save computer time.
Most objective methods of identifying modes start with the observation that the length-frequency of fish of a single year-class is often approximately normal. This allows the development of more sophisticated graphical methods, usually using probability paper which, by having a cunning scale, allows a normal curve when plotted to appear as a straight line. Several authors have described methods of this type (Harding, 1949; Cassie, 1954; Tanaka, 1956). An alternative has been proposed by Batacharaya (1967).
He noted that the frequencies fi, fi+1 … in successive points on a normal curve are related by the linear relation
ln (fi/fi+1) = a - bli
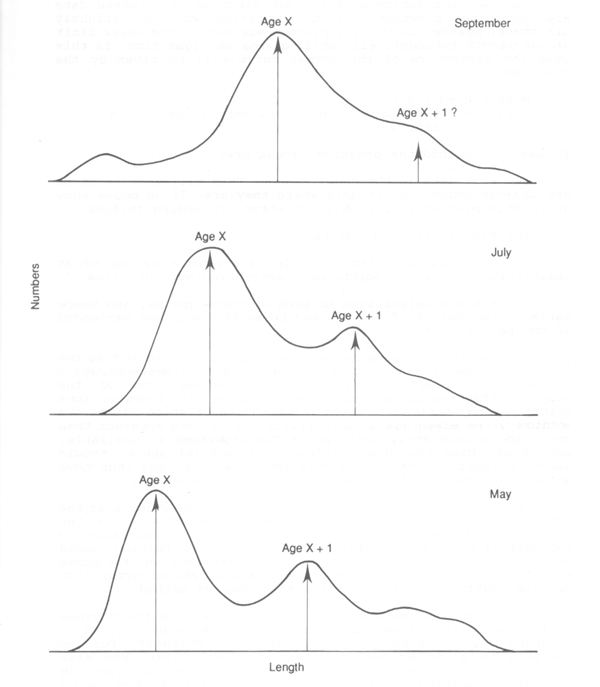
Figure 3.1 Typical moderately favourable length-composition, showing modes that are probably age-groups, and their progression from month to month
where b = s2, the variance of the distribution. If grouped data are used the constants of the relation will be slightly different, however ln (fi/fi+1) plotted against li, the lower limit of the length interval, will still give a straight line. In this case the parameters of the normal curve will be given by the equations
Mean = 0.5d + a/b and Variance = 1/b - d2/b2 where d = width of the length interval
To use this method the practical steps are:
Plot data in the usual manner. This will show if there are obvious modes, and roughly where they are. If no modes show up in this plot it is probably not worth proceeding further
Plot ln (fi/fi+1) against li
Identify where in this plot there is a series of at least three successive points on a decreasing straight line
Fit a straight line to each of these groups, and hence estimate the values of a and b and hence the mean and variances of the parent distributions.
This whole procedure can be done graphically, including the last point. Pauly and Caddy (1985) have adapted Bhatacharaya's method to a small calculator which removes some of the subjectivity from the method. However, since only three or four points may be involved, and one has a choice of which points are included, the advantage of objectivity may be more apparent than real. The method should be used if the programme is available, but in any case the graphs (stages (a) and (b) above) should always be carried out to see what the data show, and thus have a first impression of the reliability of the analyses.
The Pauly and Caddy program also produces an estimate of the numbers of fish in each modal group. With these, and the parameters of the component distributions, it is possible to reconstruct the original distribution. The reconstruction should be plotted and compared with the original distribution. For those with access to microcomputers the ELEFAN and LFSA programs also contain routines for applying the Bhatacharaya method.
Computer-based methods can be traced back to the maximum likelihood method of Hasselblad (1966), and have been given in programs like NORMSEP (Abramson 1971) and ENORMSEP. Further analysis is given by MacDonald and Pitcher (1979), who draw together the statistical and fisheries literature. The big statistical problem in identifying modes, whether by eye, or by more sophisticated methods, is that pointed out by MacDonald (1969) and others after him, which is that unless the differences in the means of the two distributions are sufficiently large, the joint distribution will not show distinct modes. The actual rule for two distributions to show distinct modes is that their means must differ by more than twice the standard deviation of the distribution with the larger spread. Since the gap between adjacent age-groups lessens, and the spread of length at age usually increases as the fish become older the chances of separation are much fewer among the older fish. Thus the figures for hamra (Lutjanus coccineus) in Kuwait waters are as follows:
| Age 0 - Age 1 Diff in mean 1 13.9 cm | min s.d 3.61 |
| Age 1 - Age 2 Diff in mean 1 10.7 cm | min s.d 5.64 |
| Age 2 - Age 3 Diff in mean 1 6.7 cm | min s.d 8.44 |
We should be able to distinguish age 1 from age 0, and possibly also age 2 from age 1, but not ages 2 and 3.
Another method of clarifying the position of the modes is to apply some form of smoothing. The best known method is that used by the ELEFAN I program (Pauly, 1987, and references therein). This program calculates a 5-point running average, and then compares the observed frequency with this average, values much above the average indicating a mode. The advantage of this procedure is that after various adjustments to correct for various sources of bias, etc., it gives a set of numbers, the peaks, expressed in a standard form that can be used in the following stages of the ELEFAN program - in fact the normal user does not have to worry about this stage in the program. It is sensitive to the size of the length-interval used - too wide compared with the width of the modes and detail may be lost, and too narrow and the smoothing destroys much of the features of the modes. If the variance of length-at-age increases with age, no length-interval may be ideal. The process also runs into problems with small numbers at the upper end of the length-distribution. Among the largest and oldest fish it is also highly probable that the separation in the mean lengths of adjacent year-classes (or other groups producing modes among the smaller fish) is no longer large enough to produce separable modes, and any modes that are detected are artefacts due to sampling variations. The approach is only recommended if it has to be used as part of the ELEFAN package.
Similarly objections exist to the other methods of determining modes which do not appeal to information outside the length-frequency being analysed. Therefore, once it seems that it is worth advancing beyond a simple visual examination of a length-frequency (in effect once this approach has been used and shown to give interesting results) it is worth moving all the way to methods that take account of more information. MacDonald and Pitcher (1979) present a procedure for estimating the means and standard deviations, of a mixture of normal distributions from the entire length-frequency. The calculations are made easier and quicker if assumptions are made about the relation between the standard deviations (equal, or increasing with size) and if preliminary estimates of the means are available from other sources, e.g., from aging a few fish. This method probably is the best for extracting the maximum information from a single sample. However, there are limits as to what can be done with a single sample. In practice, if it is worth spending time on dealing with a single sample, it is even more worthwhile collecting more samples. Then the methods described in the following sections can be applied.
Another method of splitting up a length-frequency has been given by Schnute and Fournier (1980). They used a modified form of the von Bertalanffy equation to predict the position of the intermediate modes, given the smallest and the largest modes, and the number of modes (i.e., age-groups). They also assumed two or three patterns of change in the standard deviation with age, thus reducing the numbers of degrees of freedom. This method seems to have no particular advantage over other methods of dealing with a single distribution.
The logical extension of the splitting of a single length-frequency into its component normal distributions is to recognize that a set of distributions taken at different times from the same population, and specifically their means and variances and the relative proportions in different components, must fall into a pattern (Pope, 1987; Rosenberg and Beddington, 1987; Sparre, 1987; Rosenberg and Beddington, 1988). The proportions in successive components must decrease in accordance with the total mortality, the means should follow some growth-curve, while the variances should be similar, but perhaps increasing with age.
This greatly reduces the number of parameters that have to be estimated (two or three for growth depending on whether seasonal effects are included, one less than the number of year classes present for their relative proportions, one for the mortality rate, and one or perhaps two for the variances). If the analysis is applied to a set of length-frequencies this number may be substantially less than the number of degrees of freedom, and the chances of obtaining reasonable estimates of most of these parameters are good. In this way a single process can yield estimates of growth (and possible mortality), at the same time as giving estimates of the position of modes (see section 3.1.3 below).
Another approach to locating modes that is helpful when analysing large volumes of regularly collected data, which has been neglected during the recent emphasis on sophisticated analysis of relatively few samples, is what may be called the method of anomalies. If we have data from several years, then the average length-frequency for all years can be calculated. Then the length-frequecy for any one year can be expressed as the departure, or anomaly, from this overall average. The peaks will then correspond to unusually strong year-classes, with weak year-classes producing troughs. A typical example, for the cod stock around Bear Island, is shown in Figure 3.2. For this stock the growth rate is well known from otoliths (about 10 cm per year between 45 and 75 cm). The figure was prepared to illustrate the use of length-data for forecasting, but it shows very clearly the progression of the mode due to the very strong 1950 year-class, which defines the growth-curve quite well.
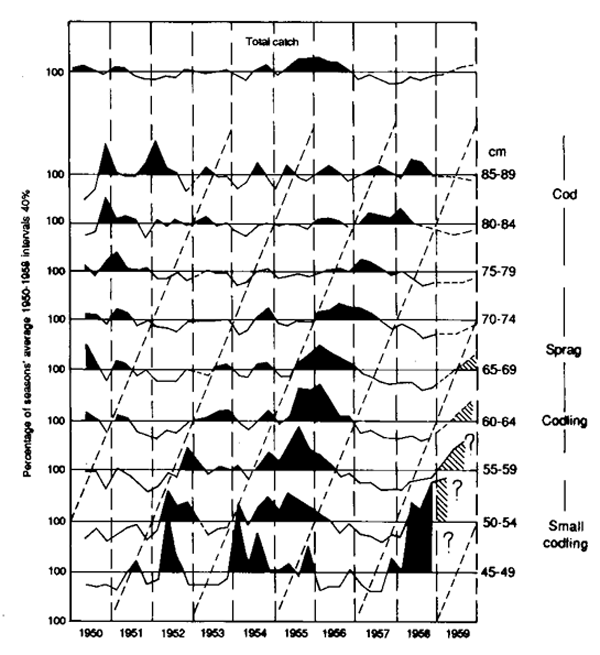
Figure 3.2 Length-composition of annual catches of cod by English trawlers fishing around Bear Island, 1950– 1959. These are expressed as percentages of the mean length-composition. Note progression of the mode due to the strong 1950 year-class
This approach has an advantage in relation to the earlier criterion for being able to distinguish modes in that the separation between modes may correspond to several years' growth (e.g., between the good 1982 and 1985 year-classes). This means that the condition for the separation to be greater than twice the smaller standard deviation may be satisfied for higher ages, and there is a better chance of the identification of modes to be carried through into larger fish. Another advantage is that if the deviations are expressed as percentages of the mean, the values will be largely independent of the effects of selectivity and mortality (assuming these to be constant from year to year) and this can simplify interpretation, especially in fisheries with a high degree of selection (e.g., gillnets). The method is likely to be particularly valuable in long-lived fish, especially if the year-class strength is highly variable.
Once modes have been identified with sufficient clarity to be reasonably confident that they correspond to a year-class or other self-contained group of fish that can be followed from month to month (or whatever the sampling interval is), then the position of the modes can be taken as estimates of the mean length of that group of fish and an appropriate growth-curve fitted to these estimates. The immediate difference compared with fitting growth curves to length-at-age data obtained from age determinations using scales or otoliths is that there is no absolute time-scale. In terms of the common von Bertalanffy equation
lt = Linf {1-exp[-K(t-to)]}
no estimate can be obtained of the parameter to. This is not a serious matter, since to has little biological significance - one cannot expect that a fish will grow in exactly the same way throughout its life. The problem can be dealt with by assigning an arbitrary date as time zero, perhaps 1 January preceding the appearance of a mode among the smallest fish. This is fine if we are following the progression of just one mode, (i.e., one batch of fish). In practice one sample may have several modes, and several years' data may reveal several distinct groups. If the sampling in different year is reasonably good it should be possible to relate the modes in different years to the same ages, e.g., in all samples taken in May there are modes around 10–12 cm which can be arbitrarily assigned age 1, and so on as these modes are followed through later samples.
If only a few samples are available other solutions have to be found. In the original study Petersen (1891) assigned age 1 to the smallest mode, 2 to the next and so on. Pauly (in his ELEFAN programs) and others have repeated samples in order to give a longer series from a single year's data. That is, given observations in 1987 they assume the size distribution in 1988 will be similar, and by repeating the 1987 data can follow the modes in the 1987 data into the assumed 1988 data (see Figure 3.3a). The assumptions involved may not be justified, and if several years' data are available, and separate estimates are needed, it is better to follow the same batch of fish through several years (see Figure 3.3b).
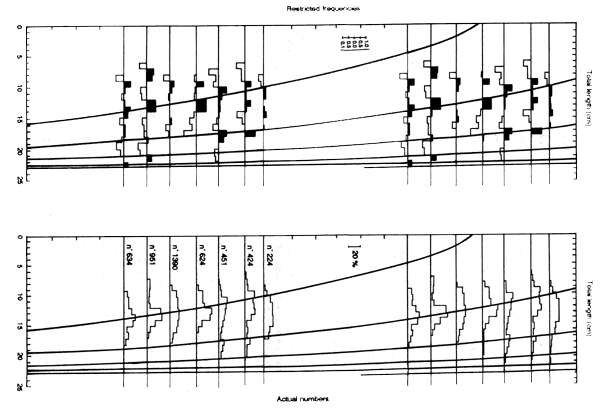
Figure 3.3a Typical use of ELEFAN program to extend one year of samples (actually only September to March above) to a second year, as applied to original data (right), and data restructured according to ELEFAN (left). Note how the fitted curve is largely determined by matching the large fish in October-November to the dominant modes in October-March (data from Pauly,1982)
Practical use of this approach will soon show its biggest problem - that while the picture among the small fish is clear and the rate of growth of these fish can be determined fairly accurately, among the bigger fish the modes are less well determined, and it may be unclear what age should be ascribed to a mode among the bigger fish, or in other words which mode among the larger fish should be matched to which smaller mode. Clearly, in fitting growth equations more weight should be given to the smaller modes, but the best statistical procedures for doing this have not been worked out.
One solution is offered by the ELEFAN program. The overall ELEFAN suite of programs, which cover more than just fitting a growth curve to length data, has been described by Pauly (1987). Detailed information on the application of programs, including computer discs with the programs are available from ICLARM in Manila. This information is, therefore, not repeated in this manual which will be confined to describing at appropriate points the different parts of the ELEFAN system. The ELEFAN 1 program, which was the original part, examines alternative sets of growth parameters for the von Bertanlanffy growth equation, in its form allowing for seasonal variations in growth, and scores them according to the number of peaks, identified by the earlier smoothing process, passed through by the curve described by a given set of parameters. The set that gives the best fit as judged by the ratio (explained sum of peaks): (available sum of peaks) can be taken as the best estimate. Alternatively, these scores for a variety of parameters can be displayed as a response surface (see Table 3.1), and an estimate chosen more subjectively, taking account of other sources of information. The advantage of looking at such a table is that it gives some idea of the range of values that produce more or less equally good fits.
| Limiting length Linf | |||||||
|---|---|---|---|---|---|---|---|
| K | 86 | 88 | 90 | 95 | 100 | 105 | 110 |
| .14 | .38 | .30 | .32 | .52 | .34 | .10 | .25 |
| .16 | .22 | .61 | .67 | .68 | .58 | .43 | .58 |
| .18 | .32 | .68 | .52 | .58 | .69 | .64 | .52 |
| .20 | .62 | .58 | .15 | .65 | .64 | .67 | .12 |
| .25 | .67 | .69 | .50 | .42 | .15 | .42 | .08 |
| .30 | .06 | .02 | .10 | .02 | .10 | .31 | .14 |
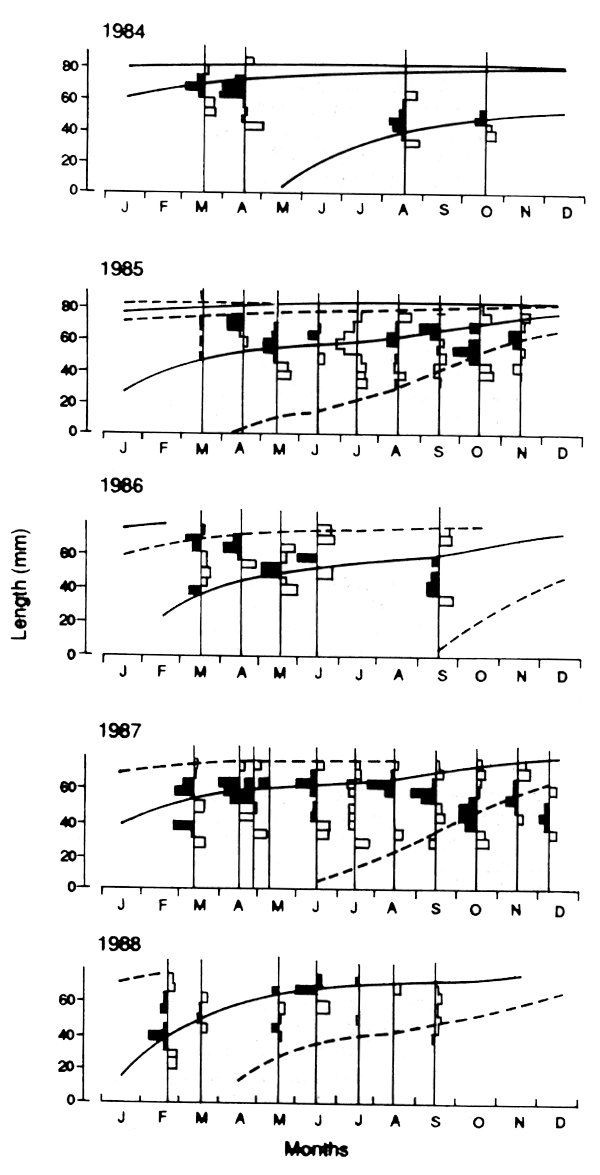
Figure 3.3b Acstual length-copositions in 5 successive years, as restructured by ELEFAN (data for Stolephorus heterolobus in the Solomon Islands, from Raqlinson 1989. Note that the distribution for a given month is not the same for each year, and the fitted curves do not always flow on from one year to the next
The ELEFAN smoothing process gives different scores to peaks according to how well defined they are, and how many fish are in the length-groups, but it is likely that this difference understates the reduced weight that should be given to the modes among the larger fish. Other theoretical and practical objections have been raised to ELEFAN by Rosenberg and Beddington (1987) and others. Some of these, such as the possible double-counting of the larger modes have been removed by later revisions to the program, but some remain. ELEFAN cannot be regarded as the last word in this approach to estimating growth. It has, however, one great advantage for the biologist in the field; it exists and programs are readily available (free from ICLARM in Manila) which enable the method to be applied without having to know how to do complex calculations or write computer programs. Further, it has been widely used without obviously disastrous results, and no one will blame you for using ELEFAN - though you can and should be blamed if you use ELEFAN and treat the estimates obtained without any consideration as to how accurate they might be, how well they fit in with other observations, and what other different estimates might fit the observations almost equally well (or indeed better, if different criteria of fit were used).
Growth-curves can also be fitted in ways that use more information than that contained just in the position of the modes. The best known of these is Shepherd's length-composition analysis (SLCA) (Shepherd, 1987). This method starts with the same idea as the ELEFAN method of scoring alternative sets of growth parameters by the degree to which modes predicted from the theoretical curve match observed modes. However, Shepherd noted that, as the data are presented from a typical set of samples, modes do not usually fall neatly into the middle of a length-interval, and that among the biggest fish two or more modes may fall in the same interval. This can be a big problem in some applications of ELEFAN, in which the scores generated among the higher modes can be near to being nonsense. Shepherd devised a test that measures the general match between prediction and observation over the whole length-distribution. His scores are based on the square root of the numbers observed in each length-group, rather than the hitting or missing of a peak used in ELEFAN, though it must be noted that in ELEFAN the peaks are scored in a way that relates inter alia to the numbers observed. The square-root transformation can be justified by the presumption that the numbers in a sample that fall in a particular length interval will be distributed as a Poisson distribution. This would give some statistical advantage to the method. However, taking the square-root is a common variance stabilizing transition and the distributional assumption is not essential.
Basically the Shepherd method seeks to maximize the total of the products T(l,i)N1/2 (l,i), summed across all length groups and all observed length distributions, where N(l,i) is the number of fish in the lth length group observed by the ith length distribution, and T(l,i) is the score function. This is defined by
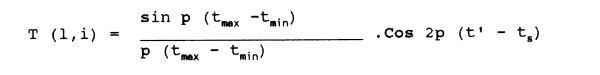
where p is the constant pi, where tmax and tmin are the ages, according to the growth-curve being tested at the upper and lower bounds of the lth length-group in question, t1 is the mean of tmax and tmin and ts is the date of the ith sample, measured as a proportion of the year.
A concise algorithm description of the procedure is (Shepherd, 1987)
Read data
Select range of parameters (K, Linf) to be used
For each value of Linf.....
For each value of K.....
For t0 = 0 and 0.25
Initialize score (to zero)
For each length group....
Calculate the ages corresponding to the length-group boundaries tmin and tmax, and their difference dt
Calculate the diffraction function ![]()
For each length-distribution.....
Calculate C = cos2 p (t1 - ts)
Calculate dS = D × C × N(l,i)1/2
Next length-distribution
Next value of length-group
Next value of t0
Set A = score for t0 = 0 Set B = score for t0 = 0.25
Calculate maximum score for current values of Linf and K, Smax = (A2 + B2)1/2
Calculate t0 to give maximum score for current values of Linf and K as t0 = arctan (B/A)/2p
Next K
Next Linf
Tabulate results
More detailed information on the program, with a listing in the Microsoft dialect of Fortran is given by Morgan and Pauly (1987). It will be noted that it is not necessary to try all values of t0. Because of the cyclical response of the score to change in t0 it is only necessary to calculate the scores for two values. Then the value of t0 which gives the maximum score, and the magnitude of that maximum, can be calculated directly. This, of course, greatly reduces the amount of computation needed.
The output from the application of the SLCA method is a table of scores for a set of alternative parameters (Table 3.2).
| Value of K (l/year) | |||||||
|---|---|---|---|---|---|---|---|
| Linf | .14 | .16 | .18 | .20 | .22 | .24 | .26 |
| 100 | 8.9 | 5.2 | 16.5 | 24.0 | 27.5 | 31.4 | 32.6 |
| 110 | 4.6 | 16.2 | 23.9 | 30.7 | 32.2 | 31.7 | 22.7 |
| 120 | 14.8 | 23.3 | 29.9 | 34.5 | 30.5 | 26.7 | 21.7 |
| 130 | 21.9 | 27.5 | 32.9 | 31.4 | 24.7 | 25.8 | 19.7 |
| 140 | 27.4 | 35.3 | 27.6 | 27.7 | 24.7 | 17.6 | 13.9 |
| 150 | 34.4 | 29.2 | 29.1 | 24.1 | 18.2 | 13.6 | 9.8 |
The results in Table 3.2 are typical in that they show a ridge of high and approximately equal scores running diagonally through the table. A number of combinations from (K=0.14, Linf=150) to (K=0.26, Linf=100) score about equally. As Shepherd points out, there is little to choose on statistical grounds between these solutions. Rather than look for the parameter set that happens to give, by a small amount, the highest score (35.3 at K=0.16, Linf=140) it is probably better to look at other information that might be available to choose the most likely set of parameters. It is worth noting, from Shepherd's Table 3, that the contribution to the score for any one set of parameters comes from the small fish (80% for fish less than 33 cm), confirming that because of the blurring between adjacent modes, the larger fish contribute little signal to the determination of growth.
As it stands, the SLCA method could be applied to a single sample, but it is much more likely to produce useful results if applied to a series of samples, especially if spread through the year. It also does not in its present form take account of possible seasonality of growth. However, as Rosenberg and Beddington (1988) point out, it requires only a small modification to the score function to include a seasonal growth function. With such a modification where it seems desirable, SLCA is probably the best method for extracting growth estimates from a set of length samples. Other methods of dealing with sequences of samples are available that can at the same time provide estimates of mortality (Sparre, 1987; Pope, 1987). These are discussed in section 3.2 below.
Another method for estimating growth from a series of samples, is the projection matrix method (Basson et al., 1988). Like ELEFAN and SLCA this method tests alternative sets of growth parameters to find the set that gives the best fit between predicted and observed length-frequencies. It differs from them (and more particularly ELEFAN) in that emphasis is put on the overall fit, rather than on the location of modes.
The principle is the same as that of a Leslie matrix, but using vectors of numbers in each length group rather than of numbers-at-age. Given a growth equation, such as the standard von Bertalanffy curve, and an expression for the standard deviation of length at age, the proportion of fish in length group j at time t + l, can be determined. This gives the projection matrix.
Using this matrix, and the observed length-distribution in the first sample, the expected distribution at the time of the second sample can be calculated. The exception is the smallest fish, which recruited since the time of the first sample; this can be dealt with by setting the expectation equal to the observed frequency for the smallest sizes.
The simulation presented by Basson et al. (1988) indicates that this method is robust in the face of moderate variation in length-at-age. When the variance is large there is a risk of bias, though the extent of this bias seems to be less than for other methods.
Another method for analysing a number of length frequencies is that of MULTIFAN (Fournier et al., (1990), for which a commercial software usable on PC's has been produced by Otter Software, Box 265, Nanaimo BC V9R 5K9 Canada. Like the other methods it depends on finding the set of parameters that give the best fit between observed and expected length-frequencies. This method has only recently been developed, and it is too early to say whether it has any particular advantages over the other methods.
Up to this point we have discussed fitting only the simple von Bertalanffy growth-curve. As pointed out by Pauly and Gaschutz (1979) fish do not always grow uniformly through the year, and there is often a slowing-down in growth during the winter. For long-lived fish not much may be lost by ignoring this seasonal growth, but for short-lived fish the effect may be considerable. Pauly and Gaschutz therefore proposed a modification of the growth equation in the form
lt/Linf = 1 - exp { -K(t - t0) + CK/2 sin2 p (t -ts)}
where p is the constant pi, C lies between 0 and 1, and is a measure of the intensity of the seasonal effect, and ts is the “winter point”, i.e., the time of year when growth is least.
Other forms of change of growth with season are possible. For example Rosenberg et al. (1986) have suggested a step-function for krill in the Antarctic, in which growth is the same throughout the summer and then drops to zero. This may be easier to handle as there is little information about the true variation in growth, and in practice either model is likely to be satisfactory.
For most methods of growth estimation discussed above, a seasonal effect of one kind or another can be taken into account without any change in the principles involved. For example, in ELEFAN using the Pauly and Gaschutz curve, one just has to find the set of values of L, Linf, C and ts that give the greatest ESP/ASP ratio, and similarly for Shepherd's method. This does however, increase the computational work - though this problem is removed if one uses an existing software package. Possibly more serious is the fact that by doubling the number of parameters to be estimated, the chances of introducing spurious results is increased. Probably the best approach is to use the simple growth-equation first, see how the predicted curve fits the observations, and only if there seems to be some systematic departure (e.g., the predicted peaks tend to be at higher lengths than those observed in the spring, and at smaller lengths in the autumn), should one proceed to using a seasonal growth-curve.
If a seasonal effect on growth is found this is not the end of the story. If one biological characteristic of the stock varies seasonally, it is highly probable that others vary too. If growth is fast, then generally biological activity is likely to be high, and predation rates may be higher at seasons of high growth. Similarly the availability of the fish to the fishing gears, especially the types that depend on the activity of the fish (e.g., traps and lines) are also likely to vary seasonally. Most of these effects do take place in temperate waters, but fortunately most of the fish are relatively long-lived, and no great errors are likely to be introduced by looking at annual average values.
This is not the case with short-lived fish, where the majority of a cohort may survive far less than six months after recruiting, and it makes a big difference whether it recruits at the beginning of the season of fast or slow growth. Sparre (in press) has pointed out that seasonal variations can give rise to serious bias in many of the observations. For example, if there is a strong recruitment in one season, then the length-frequency of the total catches from that cohort will not fit a standard catch-curve (see section 3.2.3), but the lengths corresponding to the times when the cohort is growing slowly will be over-represented. Similarly, especially if there is more than one cohort per year, age-length keys, or other methods of converting from length to age, can give inconclusive results.
Sparre (in press) is somewhat pessimistic about applying length-based methods to short-lived species when there is strong seasonal growth. This is probably correct in respect of those techniques that are applied to integrated data for a year as a whole, e.g., the simple catch-curve method. However, if the data are divided into shorter periods, say, three months, many of the difficulties can be resolved. For example, if the length-composition of the catches in each three-month period is converted into cohorts according to any of the methods of converting from length to age, this will give something like an “age-composition” for four successive periods which can be treated (apart from a difference in scale) in much the same ways as age-composition from four successive years for a long-lived fish in temperate waters.
In brief the existence of seasonal variations in growth does complicate the application of most length-based methods.
Techniques that depend on the analysis of annual figures, and some of the more complex packages of analysis should be treated with caution. In contrast step-by-step methods, applied to short periods during which there is little ambiguity about the relation between length and age, should work satisfactorily.
Incorporating other information
Up to this point it has been implied that growth will be estimated solely by examining a set of length-compositions. A fishery scientist will rarely be so confined, and he or she will be able to call on other information to help him or her. The most useful information is direct observation of the age of individual fish. While some of the claims for the importance of length methods are based on the difficulties of aging, this is often not completely impossible, and some age-determinations can be done. The technique of counting daily rings (Brothers, 1981; Campana and Nielsen, 1985) has proved feasible for many fish species for which traditional age-determination methods have not worked. This seems particularly valuable for short-lived fish, but even for these the prospect of counting several hundred rings for each fish makes the method unattractive for large-scale sampling. Data from tagging experiments can also be useful.
Not all additional information is of equal value. Assuming modes can be followed among the smaller fish the various length methods will provide good estimates of crude growth rate (cm/mo) among these fish. In terms of the usual parameters, a reasonable estimate of KLinf can be obtained, but not of K and Linf separately (see the ridge running across the response surfaces in tables 3.1 and 3.2). That is, merely by observing the rate at which small fish increase in length does not enable us to distinguish between fish that are approaching a large size slowly (high Linf and low K) and fish approaching a smaller size quickly.
The most valuable information is, therefore, that which comes from the larger fish. For example, the growth increment of tagged fish will not help much if it concerns the growth of small fish in the size range where the progression of modes can be followed easily (its chief value in practice will be to give some insight into whether tagging affects growth). Growth of large tagged fish, on the other hand, above the range of identifiable modes is most useful. Similarly, except for the purposes of fixing the absolute age (in effect setting the value of to), age-determinations of small fish are not of great value, while to know whether the larger fish are, say, 5- or 10-years-old, can be very helpful.
Combination of two or more sets of data of different kinds in any objective way raises difficult problems. Since the error structure of, for example the ESP/ASP ratio is unknown, and in any case likely to be very different from that of the distribution of the length of the individual fish about the mean growth curve, a statistically rigorous procedure is not easy to determine. Morgan (1987) gives a semi-objective procedure for combining the results of an ELEFAN analysis, and a limited number of age-determinations, by minimizing the sum a ESP/ASP + bp, where p is the proportion of the observed pairs of lengths-at-age through which the growth curve passes (i.e., falls in the same length group). This is subjective to the extent that a choice has to be made of the ratio a/b, but a more serious weakness is that it does not take account of how far the predicted curve departs from the observations, or the degree to which there is any pattern in the departures.
An alternative procedure, as applied to ELEFAN or any other comparable procedure that produces a response surface that has a flat ridge, could be as follows:
plot the length at age curve for three or four points (i.e., pairs of values of K and Linf) along the ridge, selected to include the point with the best fit (the point of highest ESP/ASP ratio or similar) and as wide a range of K and Linf as possible without going too far down the ridge (for example selected from those points with an ESP/ASP ratio not less than 15% below the maximum)
plot the observed lengths at age from the age-determinations
adjust the precise location of (i) or (ii) on the time scale (i.e., adjusting to) in order to make them coincide as closely as possible over the smaller fish
determine which of the curves in (i) best fits the points of (ii).
If all goes well, including the additional data enables one to reject most of the alternative sets of values, and to determine one set of values as providing a good fit to both sources of information. More precisely, since no method can, given the uncertainties of all fishery data, provide a result showing that only one value is right, the additional data may enable us to reduce the combination of possible values from the long ridge arising from the ELEFAN program (see Table 3.1), to a small area in one part of that ridge.
The principle of the method is shown in Figure 3.4, as applied to the data on hamra in Morgan (1987). The points and vertical lines show the mean length-at-age and one standard deviation about that mean, as determined from reading otoliths (from Morgan's Table 1). The two curves show the growth-curves corresponding to the two extremes of the ridge of high ESP/ASP values from the ELEFAN analysis (Morgan's Table 3), i.e., K=0.25 and Linf=86 and K=0.17 and Linf=105.
In this case neither ELEFAN curve fits the otolith data. All values of Linf from ELEFAN are higher than the value of around 70 cm apparent from the otolith data. Either otolith readings are seriously in error, or the ELEFAN program is giving the wrong answer. The first possibility cannot be rejected, but there are reasons why, if the otoliths are right, ELEFAN could go wrong. Two factors could be involved. First, the fish are long-lived, but with relatively high K, and there is also considerable variation in length-at-age. Thus there is an appreciable number of fish lengths close to their individual Linf1s, and many of these may be bigger than the mean Linf of the population. Second, all length groups above 50 cm (out of range from 15 to 80 cm) consist of several age-groups. There may be modes among these larger fish but they will not be the modes corresponding to a single age-group. The result is that although ELEFAN estimates the growth rate among the younger fish (as indicated by the slope of the curves up to about age 5) reasonably well, Linf is seriously overestimated.
The point to be made here is not to emphasize the weakness of one particular method in one particular situation, but to point out the value of using as many approaches as possible, and to stress the importance when doing this of examining results in such a way that the consistency or otherwise, of the different approaches is easily seen. A graphical presentation like Figure 3.4 is likely to be the most convenient for this.
If mortality is high, large fish will be scarce; if mortality is low, they will be more abundant. Clearly, the length-composition of a population will tell us something about the mortality rate in that population. A little more thought will show that the signal about mortality will be to a large extent confounded, in a statistical sense, with information about the growth parameters. Obviously, if Linf is larger there will be more big fish than if Linf is small. Further, if K is large and if the total mortality Z is small, many fish will live long enough to complete much of their growth, and the length-distribution will show many fish close to Linf. Conversely if Z is large and K is small, and also fish enter the fishery when they are still small compared with Linf, many fish will die before reaching more than a small fraction of Linf. The length-frequency will be displaced more towards the length at first capture lc. Thus we can expect that the mean length l will be affected more by the ratio Z/K than by Z or K separately. This should be borne in mind when interpreting results, especially bearing in mind that K is often not well known. Partly, for this reason several of the methods below express their results in terms of the ratio Z/K.
There are several methods that depend essentially on looking at the shape of the length-composition, e.g., using mean length or length-corrected catch-curves. All share an important feature with similar age-based methods that look at the general shape of the age-composition, e.g., the original catch-curves of Ricker (1975). Both assume a steady state, with mortalities and recruitment having been constant for a period prior to the time of observation, and the estimates obtained refer to this period, rather than to the instant when the samples were taken. With age-data, it is possible to estimate mortality over a relatively short period, e.g., between 1986 and 1987, by comparing the abundance (perhaps as measured by cpue) of say 6-year-old fish in 1986 with that of 7-year-old fish in 1987. With length-data, it is seldom possible to identify the same group of fish over a period to estimate mortality in this way.
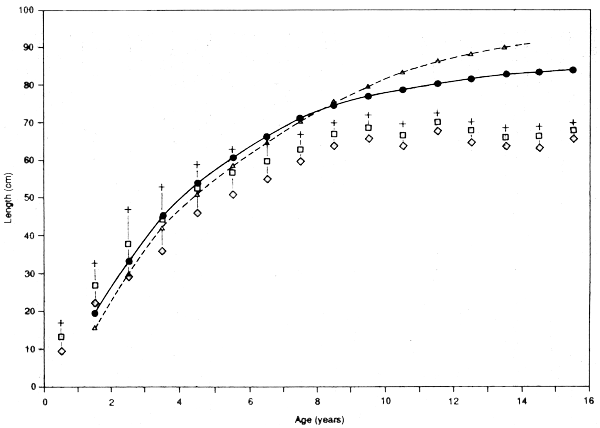
Figure 3.4 Matching length-based curves to age-data. The figure is based on the data for hamra presented by Morgan (1987) and shows (a) the predicted growth-curves based on the extremes (K = 0.28, Linf = 86, and K = 0.35, Linf = 102) of the plateau in the ELEFAN ESP/ASP presentation, (b) the observed mean length-at-age, and one standard direction each side based on otolith readings (vertical lines)
An important exception occurs with short-lived but fast-growing species with a short breeding period, e.g., some penaeid shrimps. Length-frequencies may enable the recruiting year-class to be separated from the older animals for several months after recruitment, until, with the slowing-down of growth, the larger recruits begin to overlap significantly with the older animals. Looking at the decline in abundance of this separate group will give an estimate of mortality. In principle, this can be done by looking at the decline in catch per unit effort (cpue). However it is quite possible that catchability varies seasonally. In that case a decline in cpue at the end of the season due to reduced catchability can easily be taken as due to mortality.
A particularly favourable example is given in Figure 3.5. This shows the length distribution of female Penaeus semisulcatus caught each month during the 1985/6 Kuwait shrimp season. It can be seen that the catches are overwhelmingly of a single cohort of shrimps. In July there are a few very big shrimps that might be survivors from the previous year, but unless their mortality rate is very different from that of the main cohort there is no harm in including them in the analysis. The important conclusion is that after July there does not appear to be any significant recruitment, and that, therefore, we are dealing with a self-contained group of animals, and the decline of their relative numbers, as estimated by cpue in numbers, should provide a direct estimate of mortality. This may seem an obvious point, but it is easy to overlook occasions where favourable conditions allow very simple approaches to give reliable answers.
A simple method of using mean length is that of Ebert (1973, 1987). This starts with the observation that immediately after a year-class recruits to a fishery the mean length drops, it then steadily increases through the year thereafter as the fish grow, until it drops again when the next year-class enters the fishery. The extent of the drop will depend on the growth pattern, and how large a proportion the new recruits are of the total stock, i.e., on the mortality. Modifications to the method have been proposed by Damm (1987), and if the biological assumptions hold, then this approach will give estimates of both growth and mortality. However, it is unusual for recruitment to occur so abruptly as the method requires - being more often spread through several months - and if it does it will usually be difficult to ensure that sampling takes recruits and older fish in an unbiased manner. In fact, Damm noted that “It is disappointing that real-life data to which this method could be applied could not be found”. This method is likely to be useful only exceptionally.
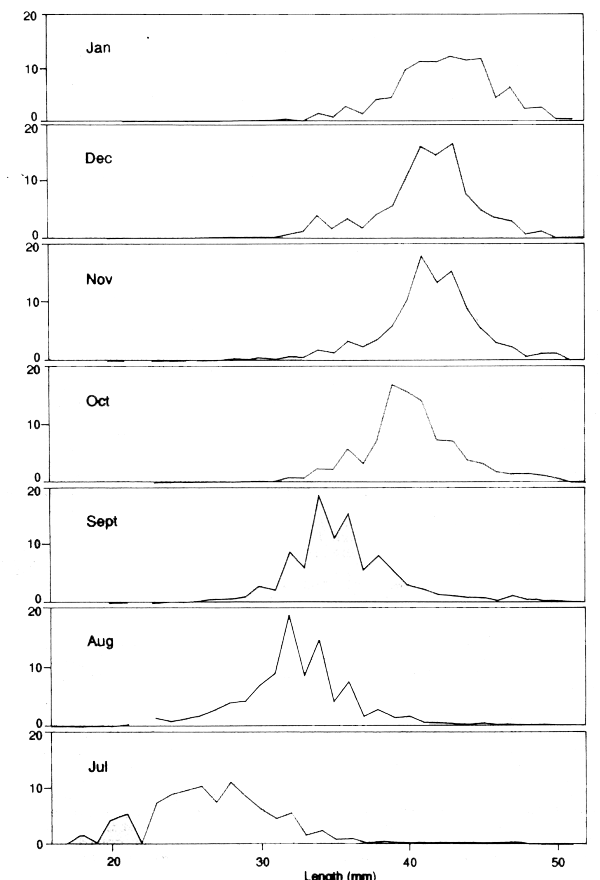
Figure 3.5 Monthly length-composition of catches of female P. semisulcatus at Kuwait. Note that only one group of shrimp is involved, with no addition of small recruits after July
Ebert's method does draw attention to the fact that if recruitment is seasonal, then the mean length, and other characteristics of the length-frequency, will vary seasonally. Thus applying any of the methods described below to a single sample, with the implicit assumption that it is representative of the population over the year as a whole, can be dangerous. Hoenig (1987) has shown that the bias involved in using the simple Beverton and Holt expression for mean length for samples taken just after a short recruitment season can be very considerable (50% or more for high mortality rates). He offers an alternative formula, but a better solution is to spread samples through the year.
Most uses of mean length to estimate mortality start with the Beverton and Holt (1956) expression
| Z/K = (Linf - l1)/(l1 - lc), | (3.1) |
where l1 = mean length and lc = length at first capture. This may be compared with the similar expression for mean age Z = l/(t- tc). The behaviour of this estimator, and similar estimates, has been examined by a number of authors. An important study is that of Laurec and Mesnil (1987), who use a powerful mathematical technique (Taylor's expansion) to reach several important conclusions. One of these is that when length-frequencies are grouped into wide groups, then the mean length of the fish in the length-interval will not in general be the midpoint of the interval. They point out that the use of even moderately wide groups (5 cm in the case of a fish growing up to 70 cm) can introduce appreciable bias (20% or more for moderately high values of Z) in the estimate of mean length and of Z (or Z/K) obtained from the Beverton and Holt formula using grouped data. Even with 1-cm groups some bias occurs, but is unlikely to be so large as to present a practical problem.
This result suggests that length-data should be collected, recorded and tabulated in finer detail that has been usual. If the use of finer detail is no problem (which may be the case with good data processing facilities) the length-data should be recorded in fine detail. However, as Laurec and Mesnil point out for this, and most other analyses, the fine structure is not important, and the question of bias can be dealt with in other ways, including reclassifying the data into smoothed but small-scale groups (e.g., regrouping data presented in 5-cm groups into 1-cm groups by graphical interpolation).
Laurec and Mesnil also put onto a sound quantitative basis another common concern, that of how close analyses should be taken to the limiting length Linf. They conclude that, while the Beverton and Holt estimate is generally robust to possible variation in the growth parameters, when the calculations include length groups close to Linf, problems can arise. As a rule-of-thumb it is probably desirable not to carry analysis beyond the point of 70% of Linf, e.g., to use as the lower limit of the largest length group in length-corrected catch-curves, a convenient value close to 70%. It may be noted here that this is a somewhat lower limit to that used in many existing analyses, which suggests that the results of some of these analyses, as they concern the upper part of the length-distribution, should be treated with caution.
A slightly different form of Beverton and Holt's formula has been proposed by Ssentongo and Larkin (1973), who showed that, under certain assumptions, a minimum variance unbiased estimator for Z/K was (N - 1)/sum (xi) where N is the sample size and xi = ln (Linf-lc)/(Linf-li), where li is the length of the ith fish measured. This method has been refined by Crittendon and Gallucci (1988), but is not as useful as other methods for large samples, and when lc is poorly defined.
The problems of the practical application of Beverton and Holt's equation (eqn. 3.1) have been examined mostly by Wetherall et al. (1987). They noted that this approach suffers from problems of not knowing the values of Linf and lc. They offered a number of alternative methods of analysing the length composition, several of which can, in principle, provide a direct estimate of Linf. Though the size of the smallest fish caught is easy to observe, this is not the value of lc that should be used in this formula. The exposure of fish to capture, i.e., the value of F at a particular length increases from nearly zero for the smallest size caught to the full value F, and what is required is the mean age (or length) at first capture, which is approximately equal to the age (or length) at which F is half the full value. Some of these methods, and some of the statistically rigorous analyses presented in the paper, are particularly appropriate when analysing small samples, such as a single sample collected as part of a short-term research project. The need to be worried by, for example, a possible bias of the order of l/n, where n is the size of the sample, is much less when it is a matter of analysing the results of a continuing programme of monitoring a commercial fishery.
Following Powell (1979) they note that, in the general case in which fish grow at different rates with different values of Linf, then assuming that this individual variation can be described by a normal distribution of Linf about the population mean with variance s2, the mean and variance of the length distribution will be given (with some change in notation) by:
| mean = Linf - [(Z/K)/(Z/K + 1)] [Linf - lc] | ( 3.2 ) |
| variance = [1/(Z/K +2)]{(Z/K) (Linf-lc)2/(Z/K +1)2 + S2} | (3.3) |
Sometimes an estimate of the variance of Linf may be available, e.g., from some direct age-determinations. More often it will not, but if, as is likely, the spread of lengths in the sample is much greater than the likely spread in Linf, the second term in the expression for the variance can be ignored. If we put the observed mean and variance equal to these predicted values we obtain two equations for the unknown quantities Z/K and Linf. This gives solutions
| Z/K = 2 S2/{(l' - lc)} - S2 | (3.4) |
| Linf = l' + Z/K(l' - lc) | (3.5) |
where l' is the mean length of fish greater than lc, and S2 is the sample variance.
This still leaves the problem that lc is poorly defined and there will be a range of sizes just above the smallest fish in the sample, whose extent will depend on the selectivity of the sampling gear (commercial or research), for which the sample is not representative of the population and in which the value of F, and hence probably also Z, will be less than for the fully recruited fish. Wetherall et al. (1987) dealt with this problem by noting that the expression for mean length of fish greater than lc is valid for any value of lc. They also noted that the expression for the mean is linear in lc, i.e., is in the form
l' = a + blc
where a = Linf{l + (Z/K)} and b = (Z/K)/(l + Z/K). If, therefore, values of l'(= l'x) are calculated by using just that part of the length-composition greater than lx, and are then plotted against lx, the result should be a straight line, slope b and intercept on the x-axis, a. From these estimates of a and b estimates of Linf and Z/K can be obtained. In practice, especially if Z/K is large, it may be convenient to plot lx' - lx against lx (see Figure 3.6). This has two advantages. First it makes it easier to detect by visual inspection the degree to which the plot departs from perfect linearity. Second, the intercept on the x-axis is a direct estimate of Linf, and the reciprocal of the slope is l + Z/K, which makes interpretation of the results quicker.
A somewhat similar approach has been suggested by Gulland (in preparation). As in Wetherall et al. regression method the mean length lx' of all fish greater than lx is calculated but this is then used to give an estimate of Z/K, - (Z/K)x, directly from the Beverton and Holt equation. This estimate can then be plotted against lx. If the assumptions of the model are satisfied then this plot should be a horizontal line equal to the true value of Z/K. In practice it will not be, and the departures from this expectation give some information on how the assumptions break down. One breakdown is almost universal. The small fish will be under-represented so that for values of lc at the lower end of the length-distribution (below the size of full recruitment) the mean length in the sample will be greater than that in the population, and Z/K will be underestimated. The first part of the plot will therefore be a rising curve, until the size of full recruitment is reached.
The assumptions will probably also break down among the biggest fish. If they grow at different rates (i.e., with different LinfS), then as lx approaches Linf the fish used in the computation will be, to an increasing extent, those with Linf's that exceed the population mean. That is, using the population Linf will give too low a Linf for the fish in the sample, and an underestimate of Z/K. Using a value of Linf that is different from the population value will have a similar effect - underestimates of Linf will lead to an underestimate of Z/K. This effect will increase as lx increases, so the plot will slope downwards. Conversely the use of too high a Linf will give a plot curving upwards among the larger sizes. This provides a method, albeit subjective, for estimating Linf. Alternative values are tried until a value is found that gives an approximately flat plot over the main part of the length composition. The value of Z/K can then be read off the plot, (see, for example, Figure 3.7 for the data for newaiby from Kuwait).
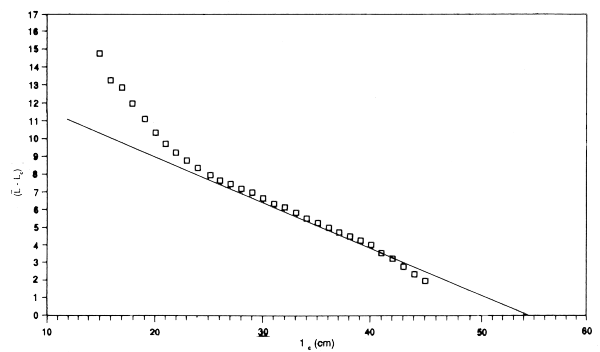
Figure 3.6 Plot of l-lc against lc for newaiby at Kuwait where l = mean length of fish greater than lc. Note approximate linear relation over middle range, and intercept at lc = 54, an estimate of Linf (data use by permission of Kuwait Institute for Scientific Research)
If no value of Linf can be found that gives a flat plot, then the assumptions of the model are not being satisfied and the method cannot be used - and probably none of the other similar methods can be used. It may be that the growth does not follow von Bertalanffy, but the most likely reason is that mortality is not constant, or the catches do not reflect the population, due for example to a highly selective gear (Figure 3.8 shows the results of trying to apply the method to the catches of zobaidy (Pampus argenteus) at Kuwait; these catches were taken by gillnet, which can be expected to be highly selective).
This method has become one of the standard methods of estimating mortality. It is based on the standard age-based catch-curve of Ricker (1958), in which the natural logarithm of the numbers in each age-group is plotted against age. The result should be a descending right-hand limb which is linear, with slope Z. If a similar plot of log numbers in a length-group against length is examined, the right-hand limb will again be almost linear. One cause of departure is that growth is not constant, and it takes a fish longer to grow through the larger groups, which thus contain contributions from fish of more ages. If the numbers are divided by the time to grow through the length-group, this effect will be eliminated, and the numbers will be presented as if they were the numbers in a year-class centred on the length group. The necessary calculations, based on the data in Jones' (1981) Table 5 are set out below. (Note that for ease in later use in a cohort analysis, the table here, as in Jones' paper, is arranged with the largest length-groups at the top.)
What is virtually the same result can be obtained by splitting the length-composition at the points corresponding to the expected length at uniform intervals of age (see section 3.4.2 below). Because the animals are short-lived it is convenient to use in this example intervals of a half-year, splitting at lengths corresponding to age 0.5, 1, 1.5, etc. Using the same procedure as for correcting the length these numbers should be doubled to give the equivalent numbers for a whole year's production of recruits.
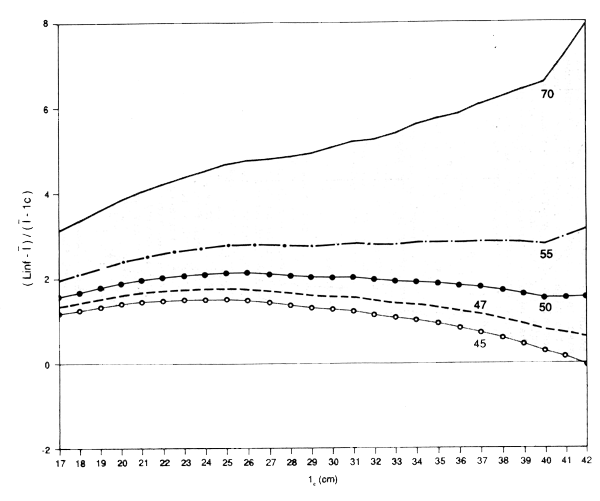
Figure 3.7 The value of Z/K as estimated by (Linf-l)/(l-lc) plotted against the cut-off values for values of Linf from 45 cm to 70 cm. Data for hamra landed at Kuwait in 1983 (data used by permission of the Kuwait Institute for Scientific Research). Note relatively flat middle section of the curve for Linf = 55 cm
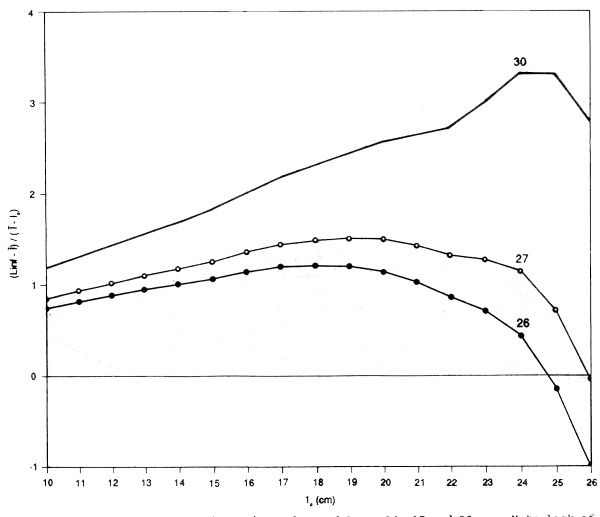
Figure 3.8 As figure 3.7, for zobaidy using values of Linf = 26, 27 and 30 cm. Note lack of very long series of points in a horizontal line for any value of Linf
| Lenght l | Init.age t | Duration dt | Numbers N | Corr.Nos. N/dt | Log Nos. In (N/dt) |
|---|---|---|---|---|---|
| 65+ | 5.278 | ..... | 3 | ..... | ..... |
| 60- | 3.892 | 1.386 | 10 | 12 | 2.52 |
| 55- | 3.081 | 0.811 | 94 | 163 | 5.09 |
| 50- | 2.505 | 0.576 | 312 | 700 | 6.85 |
| 45- | 2.059 | 0.446 | 827 | 2272 | 7.72 |
| 40- | 1.695 | 0.364 | 1650 | 5340 | 8.58 |
| 35- | 1.386 | 0.309 | 3040 | 11386 | 9.34 |
| 30- | 1.119 | 0.276 | 4730 | 20042 | 9.91 |
| 25- | 0.883 | 0.236 | 4120 | 19619 | 9.88 |
| 20- | 0.673 | 0.210 | 1390 | 7277 | 8.59 |
| 15- | 0.482 | 0.191 | 163 | 853 | 6.74 |
| Age | Lower splitting point | Numbers | Adjusted Nos. | Log Nos. |
|---|---|---|---|---|
| 0.5- | 15.5 | 3570 | 7140 | 9.49 |
| 1.0- | 27.5 | 8000 | 16000 | 9.68 |
| 1.5- | 36.9 | 3240 | 6480 | 8.77 |
| 2.0- | 44.3 | 1020 | 2040 | 7.62 |
| 2.5- | 49.9 | 270 | 540 | 6.28 |
| 3.0- | 54.4 | 85 | 170 | 5.89 |
| 3.5+ | 57.8 | 58 | (116+) | 4.75+ |
Table 3.4 shows the results. In this case the split was done graphically by estimating the area under the length-frequency curve, but essentially the same result would be obtained by splitting algebraically. Figure 3.9 shows the plots of the two catch-curves. As can be seen the two sets of points fit virtually the same line and give the same estimate. This is not surprising, since the basic assumptions are the same. Since the methods are so similar the choice between them is somewhat arbitrary, but there are reasons for preferring the second. The data are presented in a form that is suitable for later application of cohort analysis. This form also makes clearer the implications of the assumption of uniform growth of all fish. The age-length key (i.e., the percentage age-composition within a length-group) implied by the splitting process becomes increasingly unreliable as the spread of age-at-length increases.
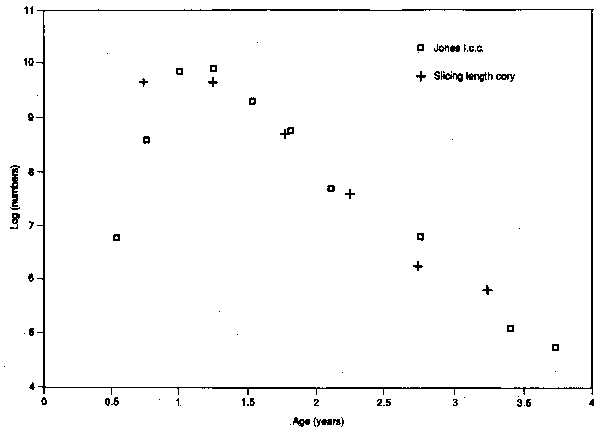
Figure 3.9 Numbers of cod (logarithmic scale) in half-yearly groups derieved either from Jones length-corrected catch curve (squared) or the method of slicing (crosses)
Length-corrected catch-curves should be used with great care when dealing with short-lived fish, or any stock in which there are appreciable changes in length-composition from month to month. The assumption made in applying the method is that the length frequency being analysed represents the steady-state situation for the population as a whole. For short-lived fish no single sample will give this, and the mean population length-frequency has to be obtained by combining data from each month. Since we are interested in the total numbers in each length-group, this combination should be done by weighting each monthly length-frequency by the numbers in the sea during that month. These are usually not known, and if they were known it would probably be easy to estimate mortality directly. Nor, in many cases, are estimates available even of relative numbers, e.g., from cpue. Even when reasonable effort statistics are available, seasonal changes in fish behaviour or distribution may introduce changes in cpue from month to month that have nothing to do with changes in abundance.
It is unusual, therefore, to compute an annual length-frequency by combining samples in some simple way, as the mean of the monthly length-frequencies, or by adding all samples together. These in effect give all months equal weighting, or weights proportional to the numbers sampled which clearly may introduce bias. Though it is not easy to measure this bias, or in the absence of estimates of the abundance in each month to propose methods of obtaining unbiased estimates, the existence of bias must always be recognized. Its likely extent should be tested by using different systems of weighting. If possible, three or four weights should be used, including equal weights (i.e., the mean of the monthly frequencies) and two or three sets of weights based on reasonable estimates of relative abundance. The greater the differences in the estimates of mortality obtained the greater the care to be used in applying the results.
Virtual Population Analysis (VPA) and the very similar cohort analysis provide, under favourable circumstances, a powerful method of estimating the population numbers at each age at the beginning of each year and hence the fishing mortality on each age. Since the initial formulation (Fry, 1949) and latter application to deal with the fishery on the Arcto-Norwegian stock, in which the fishing mortality varies greatly with age (Gulland, 1965), VPA, or cohort analysis, has become one of the standard methods of routine analysis of extended series of age-composition data, especially in the trawl fisheries of the North Atlantic. During that time there have been developments in the details of the procedure, especially in the methods of “tuning” which allow the results to be matched to the available information of abundance and fishing effort in the most recent years (Pope, 1972; Pope and Shepherd, in press).
The principle of the methods is simple. If we know how many fish of a given cohort were alive at the end of one year, and how many were caught during that year, then, if allowance is made for the deaths during the year, the numbers at the beginning of the year can be estimated. The same process can be repeated for the previous year, and so on back to the time when the cohort first entered the fishery. The original formulation of VPA used an exact expression for the numbers at the beginning of the year, which required iteration in the calculations, and it is now usual to use the simpler approximation of cohort analysis
| Nt = Nt+1eM + Cte0.5M | (3.6) |
where Nt is the number at the beginning of year t, and Ct is the catch. This approximation will be very close unless mortality during the year is high. The extent of any error will depend on the distribution of the catches during the year, and the formula will be exact if all catches were taken halfway through the year.
The attraction of the method lies in the fact that it makes no assumptions about the way in which fishing mortality varies with age, and that it offers a simple method of dealing with the array of catches at age that is available for many multi-national fisheries. In the context of the North Atlantic it was also attractive in that the output was in a form that was very convenient for calculating catches by age in succeeding years, and hence in calculating Total Allowable Catches (TACs).
The attractions must not allow one to ignore the shortcomings of VPA (or cohort analysis). The first and probably the more important, though the one that has received less attention, is that a value of M has to be assumed. Unless M is a small proportion of the total mortality (which it may be in the heavily fished stocks of the North Atlantic, but not necessarily elsewhere) differences in the input value of M will make a big difference to the results. The second weakness is that some external information has to be used to start the process for the oldest age of each cohort. If the output is considered as a table of population numbers (or fishing mortality) at each age in each year, the entries along two borders (for the most recent year, and for the oldest age-group) are, so far as the simple VPA is concerned, only guesses. The values for the oldest age-group for early cohorts can be estimated by assuming that the fishing mortality in any year is the same on that age-group as on the younger age-groups, but a problem remains for the most recent year.
This problem of setting a value of the fishing mortality in the most recent year (the “terminal F”) is central to the usefulness of VPAs. It can be shown that, if M is known, or is relatively small, then the estimates of F and N for the younger ages converge, so the choice of terminal F is only critical for the two or three most recent years, and the two or three oldest age-groups. However, the most recent years are normally the most interesting, and there are many fisheries on short lived-fish in which the two or three oldest age-groups make up much of the catch - though in that case consideration might be given to using VPAs over shorter time-intervals. In brief, VPAs are excellent for looking at the history of long-lived fish, but are less useful for examining the present, or for short-lived fish.
A similar approach can be used to analyse length data, with the important difference that individual cohorts cannot be identified accurately. Thus length-based methods usually assume a steady state, and concern average conditions over a period. Following Jones (1981, 1984), an equation similar to equation (3.6) can be derived to describe the numbers that annually reach the size equal to the lower limit of a size-group in terms of the numbers reaching the upper limit (i.e., the lower limit of the next higher length-group), the numbers caught annually in the size group, and the natural mortality. The difference is that the correction for the fish that die from natural causes has to deal with deaths during the time it takes a fish to grow through the length interval, rather than a year. Equation (3.6) is therefore rewritten in the form
| Nx = Nx+1eMdt + Cxe0.5Mdt | (3.8) |
where Nx is the numbers of which annually reach the lower limit, lx, of the xth length group, and dt is the time taken to grow from lx to lx+1. This can also be written in a form that focuses on the lengths, as
| Nx = (Nx+1 Xx + Cx) Xx | (3.8) |
where
| Xx = e0.5M dt = { (Linf - lx)/(Linf - lx+1) }M/2K | (3.9) |
The method is illustrated in Table 3.5, using the data in Jones' paper. The table is a direct output from a spreadsheet (in Supercalc) used to do the calculations. The first steps are to calculate the values of dt and X, for which a useful intermediate step is to calculate the value of (Linf - lx)/(Linf-lx+1) given in column B. From that dt can be determined from the relation dt = 1/K.ln(Linf-lx)/(Linf-lx+1), and X from equation (3.9), as given in columns C and D. (For purposes of calculation a value of K=0.5 was used.) The observed catch share is then set out in column E. From this the numbers entering each length interval are entered in column F, using equation (3.8). The ratio F/Z can then be calculated as the ratio of the catches and the numbers dying (i.e., the differences between successive entries in column F).
An interesting feature of this form of cohort analysis, as set out by Jones, is that the values of X and of the numbers entering each length-group, as well as of the ratio F/Z, do not require a knowledge of the absolute values of M or K, but only require a value of M/K. Since there are indications that this ratio is much the same for different populations of related species, it may be more reliable to use estimates of this ratio by comparisons with other species than to estimate M in this way (see also section 4.2 below). A computer program to carry out a length cohort analysis has been prepared (Lai and Gallucci, 1987), and is available on 51/4 inch disc on request from Dr V.F. Gallucci, Centre for Quantitative Science HR - 20 University of Washington, Seattle, WA 98195, USA.
| A | B | C | D | E | F | G | H | |
|---|---|---|---|---|---|---|---|---|
| 1 | Length ratio | dt | XX | CC | N | F/Z | F | |
| 2 | 65 | 3 | 4 | .75 | .6 | |||
| 3 | 60 | 2 | 1.386 | 1.149 | 10 | 16.77 | .7834 | .7233 |
| 4 | 55 | 1.5 | .8109 | 1.084 | 94 | 121.7 | .8962 | 1.726 |
| 5 | 50 | 1.333 | .5754 | 1.059 | 312 | 467.0 | .9035 | 1.873 |
| 6 | 45 | 1.25 | .4463 | 1.046 | 827 | 1375. | .9105 | 2.033 |
| 7 | 40 | 1.2 | .3646 | 1.037 | 1650 | 3191. | .9089 | 1.996 |
| 8 | 35 | 1.167 | .3083 | 1.031 | 3040 | 6529. | .9107 | 2.040 |
| 9 | 30 | 1.143 | .2671 | 1.027 | 4730 | 11745 | .9068 | 1.946 |
| 10 | 25 | 1.125 | .2356 | 1.024 | 4120 | 16530 | .8611 | .1.239 |
| 11 | 20 | 1.111 | .2107 | 1.021 | 1390 | 18661 | .6522 | .3751 |
| 12 | 15 | 1.1 | .1906 | 1.019 | 163 | 19552 | .1829 | .0448 |
| 13 | 10 | 1.091 | .1740 | 1.018 | 1 | 20246 | .0014 | .0003 |
Another approach to making a VPA or cohort analysis based on length-data is possible using the method of splitting the length-frequency into age groups. If annual length-compositions are split into ages using the method described in section 3.4.2, then seemingly it annual age-compositions will be obtained that can be used in the standard VPAs or cohort analyses. In particular it appears possible to follow the same cohort of fish from year to year, so that the analysis is not, in principle, confined to steady-state conditions. Potentially this is a great advantage over the earlier approach to length-based VPAs. How far it is a real advance, and how far appearances are correct, will depend on how closely the age-distribution obtained from slicing matches the real age-distribution, which in turn is largely determined by the degree of variation in growth rate between individual fish.
The calculations involved in this approach are set out in Table 3.6, based on the semi-annual age-data set out in Table 3.4, assuming that the same observations were obtained in seven successive half-years. They follow the standard formula, using a value of M for a half-years of 0.1. Also shown in the table, for ease of comparison with the results in Table 3.5, are the lengths of fish at the beginning of each age-interval.
| Age | Init.Length | Catches | Numbers | F/Z |
|---|---|---|---|---|
| 3.5+ | 57.8 | 58 | 77.3 | .75(a) |
| 3.0 | 54.4 | 85 | 174.8 | .87 |
| 2.5 | 49.9 | 270 | 477.0 | .89 |
| 2.0 | 44.3 | 1 020 | 1 599.5 | .91 |
| 1.5 | 36.9 | 3 240 | 5 173.8 | .91 |
| 1.0 | 27.5 | 8 000 | 14 128.1 | .89 |
| 0.5 | 15.5 | 3 570 | 19 367.0 | .68 |
As might be expected the results of this analysis are very close to those in Jones' initial analysis, as in Table 3.5. This can be seen most easily in Figure 3.10, in which the numbers at different moments (ages or length) are plotted on a common scale for the two methods. On this basis there is nothing to choose between the two methods. In practice the second is probably better. First, it allows a series of data from successive years to be analysed in the same way, and with some of the same advantages, as age-based VPAs. Second, the assumptions being made are somewhat clearer, especially if there are some limited age-determinations that allow the spread of length-at-age to be judged. The slicing method is clearly sensitive to where the slices are made, though the same sensitivity applies (if less clearly) to Jones' method.
As in the case of age-based cohort analysis the results are very sensitive to the value of M used, and to a lesser extent to the value of terminal F. They are also sensitive to the values of growth parameters K and Linf (Lai and Gallucci, 1988). The magnitudes of these effects can easily be seen by using different values of the parameters (which can be clearly evidenced by using a suitable spreadsheet or other computer program). In the absence of a full sensitivity analysis, the analysis should at least be repeated with one or two alternative values of M.
A more complex form of VPA is described by Pope and Yang (1987). This deals with a length-based form of the multi-species VPA, in which account is taken of predation, and the value of natural mortality (treated as a constant in the simple VPA) is taken as the sum of predation (dealt with in the same way as the commercial catches) and a constant rate due to other causes (disease, predation other than that by the main predator species). It is a method of analysis that is likely to be used only in situations in which research is well advanced, and thus beyond the immediate needs of most users of this manual. However, it is worth mentioning here because it is an approach for which it may be that length-based methods are better than the corresponding age-based methods since predation is likely to be determined by the sizes of the predator and prey.
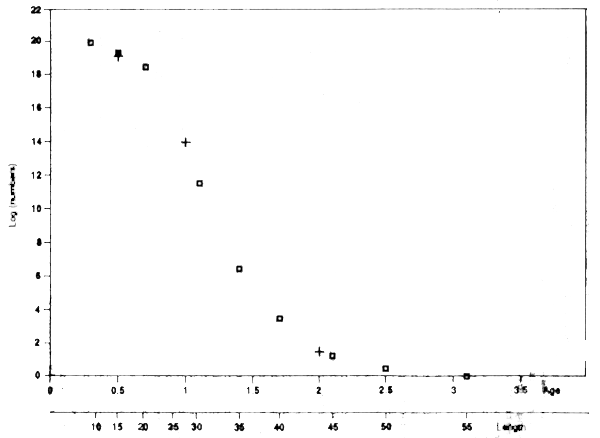
Figure 3.10 Numbers kof cod (logarithmic scale) at various instants, as determined from Jones length cohort analysis (squares), or age-based cohort analysis applied to sliced length-data (crosses)
It has been pointed out earlier (section 3.1.1) that the identification of modes for the purposes of estimating growth from a series of length samples is made easier and more reliable if assumptions are made about the likely location of the mode (by assuming a growth curve), the spread of the mode (the variance of length-at-age, due to differences of individual growth-curves or of spawning time within a season), and the numbers of fish within each mode (which is a function of year-class strength at the time of recruitment and mortality since recruitment). The simultaneous estimation of the moderately large number of unknown parameters requires a good deal of computation, and a detailed description of possible methods is beyond the scope of this manual. Sparre (1987) gives a description of a possible approach, which is restrictive only to the extent that it demands some estimate of cpue (or relative abundance) at the time each sample is taken.
The estimation procedure is broadly similar to other length-based methods, in that sets of alternative input parameters are used to produce predicted length-frequencies, which are then compared with the observations. One estimate is then the parameter set that minimizes the chi-squared criterion of goodness of fit (CHI12 in Sparre's notation). However, as he points out this may not be the best solution between competing solutions, unless it is known how many cohorts are present. The more there are assumed to be present, the greater the degrees of freedom and hence the easier it should be to obtain a good fit.
This approach is therefore likely to be most useful when the number of cohorts present is known, or can be estimated closely. This in practice means those situations where most of the length-frequency is made up of clearly identifiable modes, plus a group of larger fish which may be presumed to be the aggregation of perhaps two or three additional modes. It is thus more powerful than the methods (e.g., ELEFAN) that extract reliable information from that part of a length-distribution with separable modes, but is unlikely to extract much useful information from situations in which the larger fish consist of the aggregation of many cohorts.
The practical value of this approach is restricted by the demands on data imposed by the high number of degrees of freedom in the estimation procedure. Unless the data are very good and contain a great deal of information, it may be difficult to obtain reliable estimates.
The processes of recruitment (the biological processes within the stock that make the young fish accessible to the fishery) and selection (the technical aspects of the gear and the way it is operated) are both largely determined by size, and are therefore likely to be best studied by length-based methods. The standard methods for studying the mesh selection by trawls and gillnets are well established (Gulland, 1983) and do not need further exposition here. They depend on comparing the length-composition of two or more sets of catches, taken with gears that differ in their presumed selective characteristics (e.g., mesh size or hook size) fished as far as possible on the same group of fish. The selectivity of trawls and similar bag-type nets may be observed directly by placing a small-meshed cover over the net and observing the fish that pass through the main net. These methods remain the best method of studying selection, and the necessary experiments should be carried out whenever selection is likely to be an important matter.
The physical selection by the gear is not the only factor influencing the way that fishing mortality increases among the young fish. The ways in which the fishermen use the gear, especially the times and places fished, can have a considerable influence, and it is interesting to know more about these processes, as well as about the more strictly biological aspects of recruitment, e.g., the migrations into the fishing grounds or changes in behaviour that may make the fish accessible to the gear. A fair idea of the combined effects of recruitment and selection can be obtained just by looking at the length-composition of the catches. The rising left-hand limb of the length-frequency provides a good first estimate of the pattern of entry into the fishery.
Pauly (1987) has suggested that this general impression can be put into quantitative terms by using the catch-curve and extrapolating backwards (see Figure 3.11, taken from Pauly's Figure 9). If Z were constant over the range of size being considered, then the linear extrapolation represents the numbers that would have been caught if there were no selection (using the term in the wide sense to include the effects of all factors, and not just gear selection), i.e., if the length-composition of the catches was identical with that of the population. The ratio between the observed frequency and the back-extrapolation gives an estimate of the selection, i.e., the fraction that the fishing mortality is of the fishing mortality on the fully exploited sizes. In practice it is unlikely that Z will be constant. If F is non-negligible and M is constant, then Z will decrease at the smaller sizes, and the extrapolation should bend down, as indicated in Figure 3.11. If M is known, corrections can be made for this effect as suggested by Munro (1984). On the other hand it is quite possible that M will be higher among the smaller fish. In view of these doubts it is wise to follow normal practice, and not to extrapolate far beyond the range of the good observations. In practice this will probably mean not more than three or four size-groups smaller than the peak in the length frequency, or the left-hand point in the linear part of the catch-curve. This will generally be sufficient to define most of the selection curve and give a fair estimate of the 50% selection length (i.e., the length at which the fishing mortality is half that of the fully recruited sizes).
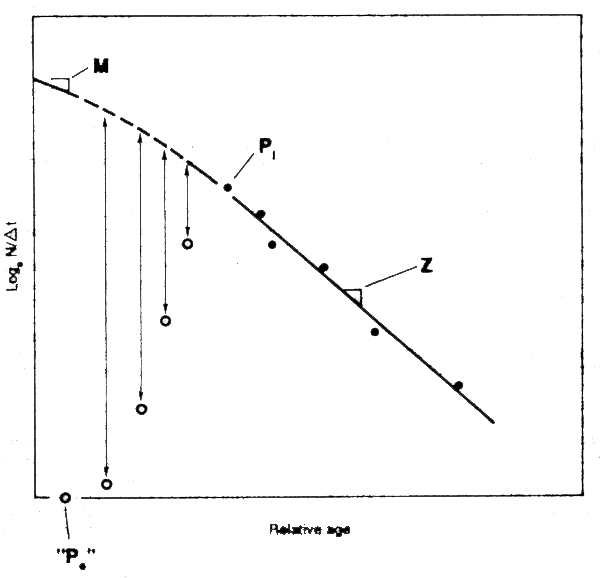
Figure 3.11 Method of estimating proportional recruitment. The approximately straight part of the observed catch-curve is extrapolated back to sizes smaller than the first fully recruited size. The ratio of the observed value (circle) and predicted value (on the line) gives an estimate of the proportion recruited (From Pauly, 1988)
It has been suggested (e.g., by Pauly, 1986) that the selection proportions obtained in this way can be applied to the observed length-frequencies to produce corrected frequencies, free from the effect of selection, and that these corrected frequencies can be used in further analysis, for example to obtain better estimates of growth among the smaller fish. Such methods should be used with extreme caution; the argument is largely circular (the selection ratio used to obtain better numbers-at-length have themselves been estimated by determining what those numbers are likely to be. If the circularity is removed, e.g., by estimating selection from one data set and applying it to correct an independent data set, there are still doubts about the validity of long back-extrapolation. As a rule-of-thumb it is probably true that, if the selection analysis indicates that the fishing mortality on a size-group is only 10% or less of that on the large fish, that group is being so poorly sampled that the catches cannot be used to give quantitative estimates of its abundance).
This caution should not imply that nothing needs to be done once a selection curve has been estimated. It is important to check the implications of selection for the growth estimates. If this was done by following modes, then it is important to note that any modal group that extends into the selection range will be distorted. Its smaller members will be under-represented, so that the value of the mean (or modal) length of the group will be over-estimated. This will probably result in the rate of growth among the sizes straddling the selection range being underestimated. If there are modes in this range that contribute appreciably different from the original values, the new figures are likely to be closer to the true modal lengths of the age-groups concerned, but the existence of a large correction should be a warning about the possible errors. In this case a wise thing to do would be to look at different sampling gear, capable of catching the small fish in a less selective manner, and thus giving more reliable estimates of modal lengths among the small fish.
Another thing that should be done is to compare the observed effective selection curve with the likely selectivity of the gear (or gears) being used. This will tell you whether the entry into the fishery is controlled by the gear, or by other factors, and thus whether mesh regulations or other control on the gear are likely to be effective. The comparison might be done after formal mesh experiments, but a useful answer can be obtained by a few minutes at a landing place and seeing whether a fish at around the 50% selection length can just pass through a typical mesh. If it clearly cannot, and other factors are important, a few moments should be spent considering what these are, i.e., why are the smaller fish not appearing in the samples if the gear used could retain them? Is it because they are being caught but discarded, or are they in unfished nursery areas? These questions may suggest useful lines of research.
While it is possible, as described in other sections, to carry out assessments directly from length-data, most assessments are more easily done in terms of age. It is, therefore, convenient to convert length-compositions into the corresponding age-compositions. In principle, it is possible, when age-determination of individual fish is easy, to collect age-data directly by large-scale collection of scales or otoliths, without any separate observations on length. Nearly always this is a wasteful procedure. Even if age-determination is easy, the time taken to collect a scale, mount it on a slide or otherwise prepare it for reading, and reading the age, takes very much longer than measuring a fish. Otolith collection is likely to take longer, and cannot be done without damaging the fish, which may not be acceptable on a large scale when sampling commercial fish.
Most sampling of commercial catches is, therefore, based on large-scale sampling for length, backed up by sampling for age on a smaller scale. This approach, which has a tradition of at least half a century (Fridriksson, 1934), is particularly useful when there are several groups of fishermen using different gears or fishing at different times and places that result in different effective selectivities. That is, the groups take different sizes and ages of fish. However, unless there is something unusual about the regional patterns of growth, the relation between age and length will be the same for all groups. To reach a correct estimate of age- or length-composition it is essential that all groups of fishermen are sampled, but this sampling can be restricted to length measurements. Thus in many international fisheries it is common to obtain the age-composition of the total catch by adding together the length-compositions of the individual national catches. The total age-composition is then obtained by applying to this length-composition a single age-length key, obtained by pooling all available age-determination data, which need not, and often will not, include contributions from all countries.
Though some of the methods (e.g., those splitting a length-distribution into its constituent normal distributions) discussed earlier for estimating growth will at the same time provide estimates of the age-distribution, these methods tend to be time-consuming, and it is more usual to use simpler methods for routine conversion from length to age. Much the most common method has been the use of age-length keys. However, despite their widespread use over a long period, they are not always used correctly.
The basic principle of the key is to establish, for each length-group, the proportion of each age in that group. This is clearly influenced by the growth, and if all fish grew in exactly the same way, then all fish of the same length would be the same age, and fish in a given length-group would differ in age only by the time taken to grow through that group. This does not happen, and, especially among the larger groups, differences in growth result in several ages being present. The proportion of these groups will depend on their relative proportions in the population as a whole, and hence on the recent mortality rates and on the relative strengths of the year-classes. These will vary from year to year. Therefore an age-length key constructed from otoliths collected in one year cannot, without risk of error, be applied to a length composition in another year to estimate the age composition in that year.
The extent of the errors that can be introduced by using an age-length key based on data from the wrong year will depend on the range of ages within a length group, and will be small if only one or two ages are present. For example in the cod data given in Table 3.8 below, nearly all the cod in the 40–49 cm group were 2-year-old, and this would probably be true whatever the age composition of the stock - unless 1- or 3-year-old fish were extremely abundant. In other cases the spread of ages is large. For example, Table 3.7 below gives the age-determinations of male plaice sampled at Lowestoft in 1955 (data from Gulland, 1966). The spread of ages on most groups is large, and the 7-year-old fish are the commonest in both the 35–39 cm and 40–44 cm groups. This is presumably because the 1948 year-class was strong, and in 1956 it is likely that 8-year-old fish will be commonest. If a key were constructed after a period of much higher mortality it would presumably look very different, with for example few fish over 7 in the 35–39 cm group.
| Age | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Length | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Total |
| 25–29 | 33 | 82 | 30 | 13 | 8 | 1 | 0 | 0 | 0 | 167 |
| 30–34 | 8 | 48 | 53 | 24 | 34 | 12 | 5 | 1 | 1 | 186 |
| 35–39 | 1 | 14 | 26 | 33 | 42 | 19 | 11 | 10 | 6 | 162 |
| 40–44 | 1 | 8 | 2 | 12 | 5 | 5 | 0 | 3 | 0 | 36 |
| 45–49 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 4 | 4 | 99 |
The principle of using a key is simple. An example is given in Table 3.8 below, which is in fact a direct output from using a spreadsheet (in this case Supercalc) to do the calculations.
The first step is to tabulate the actual age-determinations, in terms of the number of otoliths (or scales) within each length-group found to be of each age. These are set out in the entries from B3 to I11. In the case of an international fishery these entries can include all age-determinations (assuming that readings by different institutions have been shown to be consistent). This should not introduce any bias, even if the different fisheries have different selection patterns, provided there is no reason for such selection to affect the age-distribution within a length-group. This seems unlikely. Many gears are selective in favour of fish of a particular size, but within a length-group it is not easy to see how a gear would select a fish of one age in preference to another.
As in the case of direct age sampling, some decision will usually have to be taken about fish whose otoliths or scales are unreadable. Since these fish are likely to be the larger and older ones, omitting them risks bias. Omitting them from a key, however, only risks bias to the extent that they may be older than the average fish of the same size. Thus, by using an age-length key there is less risk of bias in using the convenient procedure of omitting the unreadable otoliths.
| A | B | C | D | E | F | G | H | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | AGES | ||||||||||
| 2 | Length | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Total | |
| 3 | 30 | 12 | 36 | 0 | 0 | 0 | 0 | 0 | 0 | 48 | |
| 4 | 40 | 1 | 73 | 3 | 0 | 0 | 0 | 0 | 0 | 77 | |
| 5 | 50 | 1 | 54 | 6 | 0 | 0 | 0 | 0 | 0 | 61 | |
| 6 | 60 | 0 | 43 | 25 | 0 | 0 | 0 | 0 | 0 | 38 | |
| 7 | 70 | 0 | 0 | 277 | 34 | 0 | 0 | 0 | 0 | 311 | |
| 8 | 80 | 0 | 0 | 8 | 12 | 7 | 3 | 0 | 0 | 30 | |
| 9 | 90 | 0 | 0 | 0 | 10 | 9 | 5 | 3 | 0 | 27 | |
| 10 | 100 | 0 | 0 | 0 | 0 | 4 | 2 | 7 | 3 | 16 | |
| 11 | 110 | 0 | 0 | 0 | 0 | 0 | 3 | 4 | 3 | 10 | |
| 12 | Proportions | Numbers | |||||||||
| 13 | 30 | .25 | .75 | .0 | .0 | .0 | .0 | .0 | .0 | 160 | |
| 14 | 40 | .013 | .948 | .039 | .0 | .0 | .0 | .0 | .0 | 488 | |
| 15 | 50 | .016 | .885 | .098 | .0 | .0 | .0 | .0 | .0 | 394 | |
| 16 | 60 | .0 | .342 | .658 | .0 | .0 | .0 | .0 | .0 | 205 | |
| 17 | 70 | .0 | .0 | .794 | .206 | .0 | .0 | .0 | .0 | 139 | |
| 18 | 80 | .0 | .0 | .267 | .4 | .233 | .1 | .0 | .0 | 75 | |
| 19 | 90 | .0 | .0 | .0 | .370 | .333 | .185 | .111 | .0 | 42 | |
| 20 | 100 | .0 | .0 | .0 | .0 | .25 | .125 | .438 | .188 | 15 | |
| 21 | 110 | .0 | .0 | .0 | .0 | .0 | .3 | .4 | .3 | 2 | |
| 22 | Total | 52.8 | 1102 | 323 | 74.2 | 35.3 | 17.8 | 12.0 | 3.41 | 1520 | |
The next stage is to calculate, within each length group, the proportions of each age-group, viz.
pij = nij/n.j
where pij = proportion of fish aged i in the sample of fish in length group j for which ages were determined
nij = number of fish age i in that sample and n.j = total fish in the sample of length group j
This and later calculations can be readily set out on a spreadsheet (as in Table 3.8) (i.e., the entry in cell B13 = 12/48), but regular samples are better handled in a bigger database system.
The total number in an age-group is then given by the expression
Ni. = sum{Nij}
where the summation is over all years j and where Nij = pijN.j
and N.j = total numbers in length group j as determined by length
sampling.
The variance of the estimates can and should be calculated. If the sampling errors in determining the overall length distribution are ignored, then
var(pij) = pij(1-pij/n.j) and
var(N.j) = sum{Nipij(1-pij)/n.j}
A term should be added to include the contribution to the variance due to uncertainties in the length-composition. An exact expression for this is given by Kutkuhn (1963) assuming that this contribution to the variance is due only to the errors in sampling randomly, from a uniform population. In this case it will be inversely proportional to M, where M is the number of fish measured. In practice M is likely to be much larger than the number of fish aged, so this contribution will be small. On the other hand the true variance in the estimates of N.j will be much larger than indicated by assuming random sampling from a uniform population. It will depend on the variation in length from sample to sample, and hence on the number of samples, as well as the number of fish measured.
The condition that the age-length key used in any one year should be based solely on age-determinations of samples taken in that year is a restrictive one, and one that, strictly interpreted, limits the use that can be made of individual age-determinations. When age-determination is difficult, time- consuming or expensive (because for example large fish have to be purchased in the market) this limitation can be serious. Under these circumstances it is important to make as much use as possible of each fish sampled for age determination.
One way of doing this is by putting most sampling effort into those length-groups where there is most uncertainty about age, and thus contribute most to the variance in the estimated age distribution. This usually implies putting more effort into taking samples from the larger length-groups. For example in Table 3.8 nearly all the fish in the 40–49 cm length group are age 2, and very little sampling is needed to confirm this, while the 90–99 cm group contains four ages in appreciable numbers. It is worth sampling this group and other larger fish in much greater intensity than their occurrence in the population might suggest. The benefits of such an approach among the smaller fish are increased by using keys for shorter intervals than a whole year. Thus the key in Table 3.8 is based on samples taken in the third quarter of the year, and only in this quarter is the 40–49 cm group made up so overwhelmingly of 2-year-old fish.
The determination of the optimal distribution of age-determinations is not easy. One criterion for the optimum has been proposed by Lai (1987). This is to minimize the sum of squares of the estimated and true numbers at each age. On this basis the best strategy is random sampling, with the numbers aged in each length-group being proportional to the numbers in that group. This is probably not a good criterion since it results in the less abundant (and older) ages being estimated with a larger percentage error than other strategies that sample relatively more of the bigger fish. In terms of the ultimate uses of age- data, e.g., in estimating mortalities, it is probably advantageous to have all ages (or all of the commoner ages) estimated with equal precision. Certainly it is not useful to have just the one or two peak ages estimated with high precision. The precise sampling pattern that will, for example, result in the least variance in the estimates of mortality is not easy to determine. In practice the simple rule-of-thumb of spreading sampling for age (e.g., collection of otoliths) evenly through the length groups is as satisfactory as anything.
A common problem in commercial fisheries in which sampling is irregular is that length sampling is done in each year, but age-data are missing in some years. It is then tempting to find some method of interpolation to produce an age-length key for the missing years. This has been considered by Kimura and Chikuni (1987) who noted that, while differences in relative year-class strength or mortality can affect the age at length (i.e., the horizontal pattern in an age-length key), unless there are also changes in growth, there will be no change in length-at-age (i.e., the vertical pattern). This enabled them to develop an iterative procedure in which an initial key derived from the adjacent years is modified, to provide the best possible match with the observed length-frequency in the year with no age-data. This method probably works best when the number of age-classes is less than the number of length-intervals, and there is not too much variance in length-at-age.
Other methods of interpolation can be suggested. It is also possible to approach the problem of few age-determinations in any one year by pooling data from several years. This might be done by a rolling grouping, i.e., using a key for the 1986 length-data based on age samples from 1985, 1986 and 1987, for 1987 from 1986–88 and so on. Unless the interpolation procedure is perfect, which is unlikely, errors will be introduced, but these may not, depending on the ways in which the resulting age distribution is used, be serious. The most obvious effect will be to flatten out any differences in abundance between adjacent year-classes. Interpolation of keys should therefore be done with caution when year-classes are variable, especially when the extent of this variation is of interest - though as a practical matter it may be noted that age-determinations are rarely absolutely accurate, and errors in reading otoliths have the same effect of smoothing out year-class differences. If, as is often the case, errors in reading tend to be in one direction (e.g., some rings are missed in difficult otoliths, leading to an underestimation of age) there will be a bias in the estimated age- composition. Using interpolated keys may only be continuing a process that is already occurring.
The use of the wrong key can also affect any estimate of mortality obtained from the resulting age-distribution, and an effect of this kind can be serious for many stock assessment purposes. However, if interpolation or grouping is done over a short period the differences in mortality are likely to be small, and the errors introduced might be acceptable. At present not enough work has been done on the errors introduced by different procedures and the impact on later assessments to give definite advice. The most serious errors are likely to arise when the same key is used over a period of years during which the mortality or recruitment is changing appreciably, and bias can arise. Large errors can also arise when unusually strong, or weak, year-classes are present, but these will not introduce bias over a period.
Mention should also be made of a method developed by Hoenig (1987) and his colleagues. Though somewhat similar to the method of Kimura and Chikuni (1987), it does not attempt to construct an age-length key. Rather, given two samples, the first a random sample giving age and length of each fish sampled, and the second a random sample of length only, it finds, via a mathematical algorithm, the age-distribution, of the second sample which best fits the observed length-distribution, given the observed distribution of length-at-age in the first distribution. It thus assumes that the length-at-age (i.e., the growth) is the same in the two samples. This is less restrictive than the assumption in age-length keys that the age-at-length (i.e., the age- distribution) is the same in both samples.
A method that is less demanding on data is the slicing of length-compositions. This is closely allied to the use of age-length keys, and in fact, as will be seen, uses a simplified form of key. The principle is simple. If the “average fish” reaches, say, 34 cm on its third birthday, and 41 cm on its fourth birthday, then, if all fish grew exactly in this manner, all the fish between 34 and 41 cm would be 3-years-old. Following this argument all we have to do is to establish the boundaries between age groups, slice up the length-compositions at these points, and the sizes of each piece will give the age- composition. The method is illustrated in Figure 3.12 using the cod data of Table 3.8. When using this method the boundaries are usually taken as the mid-points between the mean lengths of each age-group, as estimated from some independent study of growth. In this case the growth is estimated as the smoothed length-at-age obtained from the data in Table 3.8. It will be seen that this in fact establishes an age-length key, though one that is likely to contain fewer non-zero entries than that derived from actual age-determinations. Thus the 80–89 cm group is supposed, on the basis of the slicing procedure, to contain only 4- and 5- year- old fish, (30% and 70% respectively), but in fact also contains a number of 3-and 6-year-old fish.
Figure 3.12 Method of slicing the length-composition of North Sea cod to give an age-composition. Note that the effect is similar as using an age-length key
The age-composition thus obtained is therefore likely to be a smoothed version of reality. This is shown in Table 3.9 which gives the estimated age-composition from the standard age-length key, and from slicing.
| Age | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8+ |
| From age-length key | 53 | 1002 | 323 | 74 | 35 | 18 | 12 | 3 |
| By slicing | 430 | 596 | 248 | 137 | 59 | 28 | 12 | 10 |
As can be seen, the slicing method leads to over-estimation of the youngest and oldest age-groups, and under-estimation of the 2-year-old fish that seem to be particularly abundant. The general shape of the two age-compositions is similar, and would imply rather similar values of total mortality, as estimated, for example, by the catch-curve method (Ricker, 1975). This is important, since the slicing approach is part of some of the length-based methods of studying mortalities, e.g., length-based cohort analysis (see 3.2.4).
Two points should be made here, and remembered when using these methods. First, the age-composition is a smoothed version of reality, and any estimates obtained should be considered as averages, rather than point estimates relating from one particular year (i.e., the figure of Z obtained from data collected in 1989 gives an estimate of the mortality in the same period prior to 1989). Second, the slicing method uses in effect a fixed age-length key, and thus fails, in the same way as using a traditional age-length key for the wrong year, to take account of changes in mortality. Thus it is probable that length-based cohort analysis will underestimate changes in mortality, due for example to increased fishing. That is, it will take account of the impact on the length-composition, but not of changes in age-composition within a length-group. The magnitude of this effect can be judged by looking at the distribution of age at length where this is available (e.g., from a few otoliths). If a length-group contains many ages (as is the case of the larger plaice in Table 3.7) then changes in mortality (or in relative year-class strength) can make a big difference to the distribution of age-at-length. The slicing method (or pooled age-length keys) in which the conversion of length to age is less affected by changes in mortality can be used with more confidence.
While the use of keys or the slicing of length-compositions are simple, and probably the best ways of routinely handling length-data when the growth is well known, they do not use the information contained in the shape of the length-frequency. If this contains clear modes, then several of the methods discussed earlier for estimating growth (usually by noting the positions of the modes) also produce estimates of the age-frequency (as the relative numbers in different modes). Where these methods, such as those of Schnute and Fournier (1980) or Sparre (1987), are used then converting from length to age does not need to be treated as a separate operation, but is an integral part of the analysis of the data for estimating growth. Under favourable conditions, if the modes are fairly well defined over the whole length frequency, and if the data-series is short, and will all be analysed for the purposes of estimating growth, the other methods will not be necessary. More usually this or the length- splitting method will be needed for the larger fish, or to handle large volumes of regular samples.
![]()
![]()
![]()