![]()
![]()
![]()
The workshop Programme covered the most important themes of information management, including the organization of data systems, quality assurance and control, the use of metadata and data archiving. Information was also provided on GTOS and the TEMS database. All workshop participants were provided with a copy of the book Ecological Data: Design, Management, and Processing, Methods in Ecology Series by W. K. Michener and J. W. Brunt, Eds. (2000), Blackwell Science.
This book was the source for the majority of the lectures given during the workshop and is the source of the tables and figures within this report.
The lecture topics were as follows:
General Data Management Principles
A sound philosophy for data management in ecology research is that it should be people-oriented. It must offer practical solutions to ecologists and place training and education above technical sophistication and complexity. It should provide well managed high quality ecological data which is easy to access but is also secure and durable in time.
Two basic principles can facilitate successful data management:
Start small, keep it simple, and be flexible;
Involve scientists in the data management process.
Ecologists have the responsibility for defining scientific objectives for the data management system. They must establish research priorities and determine resource allocation. The data management system at a site should be developed from a research/monitoring perspective and must reflect the objectives and priorities of the research/monitoring programme.
Data management can provide added value to a project’s database by assuring that archived data are of an acceptable quality and can be retrieved and understood by future investigators. Data management systems for ecological research have mainly evolved over the last 30 years out of large projects like the IBP and the US Long-Term Ecological Research projects, with systems becoming broader and more complex. Many future advances in ecology are likely to hinge on the ability to integrate diverse computerized data sets. Carefully considered and applied data management practices are therefore required.
1.1 Data Management Implementation
The reasons for implementing a data management system are to:
Formalize the procedures used to acquire and maintain the products (e.g. data) of a research project so that they may extend beyond the lifetime of the original investigator(s).
Facilitate the resurrection of currently inaccessible historical data.
Support the preparation of data sets for peer-review, publication in data journals, or submission to a data archive.
Provide access to data sets that are commonly used by more than one investigator on a project.
Provide access to data sets by the broader scientific community (e.g. via the world wide web).
Reduce the time and effort spent by researchers in locating, accessing, and analysing data, thereby increasing the time available to generate results.
Increase research capacity by allowing the analysis of broader scale questions, which would be impossible without the organization of a data management system (e.g. the need to integrate multiple dissimilar data sets).
Incorporate data from automated acquisition systems into ongoing analytical efforts such as ecological modeling.
To manage ecological data a logical organized structure for the data management system is essential.
The primary goal of a system is to provide the best quality data possible within a reasonable budget. The second system requirement is that data is easily accessible by investigators. Thirdly (but just as important as access) short- and long-term security of data through data archiving needs to be provided. The fourth requirement is that computational support and quality assurance is given to users of the system.
The protocols and computational infrastructure required to achieve these goals vary considerably within the research community and can range from relatively simple to extremely sophisticated implementations. Technology affects the way data management is carried out but it should not affect the principles that are applied.
1.2 Data Management System Components
Research data management in ecology (as in other disciplines) involves acquiring, maintaining, manipulating, analysing, archiving and facilitating access to both data and results.
Six components or activities are fundamental in the implementation of a data management system:
i. An inventory of existing data and resources will have to be compiled, and priorities for implementation set.
ii. A logical structure needs to be developed so that data can be organized within data sets. This will facilitate data storage, retrieval and manipulation.
iii. Procedures for data acquisition, quality assurance and quality control (QA and QC) will need to be established.
iv. Data set documentation protocols will need to be developed. Including the adoption or creation of metadata content standards and procedures for the recording of metadata.
v. Measures for the storage and maintenance of printed and electronic data will have to be developed.
vi. Finally, an administrative structure will need to be developed so responsibilities are clearly defined.
1.3 Inventory of Existing Data Sets
It is essential to have an inventory of past, present and also future data sets and resources. Research programmes and activities, data type and quantity, staff, facilities and financial standing should all be included. Once the inventory is completed the objectives for each data set will need to be determined. These objectives should then be made available to the project investigators with as much supporting information as possible. This information will be invaluable for initiating the data management system and will be requested, used and revised countless times.
1.4 Data Design, Organization and Manipulation
Data design (the ‘logical’ organization of data into tables) should primarily reflect the experimental design in use. Decisions about data design will be necessary before data is collected to allow field and laboratory data sheets to be constructed. The completed design can be transferred directly to data entry tools to aid data collection, facilitate analysis by statistical software, support metadata development and to structure the data set for archiving. Designing the precise structure of data tables for use in database management systems (DBMS) is called normalization. The use of this design process on ecological data requires detailed knowledge of the data to avoid costly mistakes.
Organization of the Data Sets
Commercial DBMS software may be inappropriate for initial file organization and management. A file management systems can be initially used to organize data sets. The data, metadata, analytical and management tools are all stored in a logically built structure (see Figure 1).
Data manipulation and maintenance
Special software is needed to store, manipulate and maintain scientific data. There are several software packages available to data managers that are designed specifically for the manipulation and analysis of scientific data (e.g. SAS and S+). There are also other types of software that are designed for general database management systems (e.g. Foxpro, Oracle and MS SQL Server).
One of the most important decisions by the data manager will be whether to invest time and money in a DBMS. The decision will depend on many factors, including the type and the intended use of the data. Geographic information systems (GIS) represent a special type of DBMS that combines spatial mapping and analytical capabilities with relational database functions.
Figure 1. An example of the use of a computer system directory structure in the data management system. The dashed lines indicate the physical separation on the hard disk while the solid lines represent virtual links between directories.
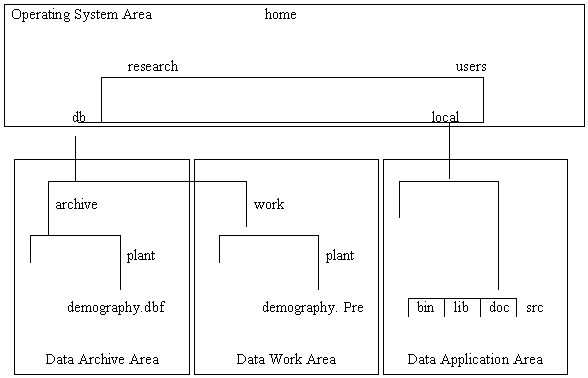
GIS should be viewed as part of the overall data management system, particularly if the research has a strong spatial component. Considerations, including the use of accepted practices in documenting and storing coordinates, should be made in all data management systems for the potential use of the data in GIS.
A Internet-based information system may be needed to deliver data and data derived products. Such a system is also likely to be required for advanced query, integration and analysis functions. Information systems expand the capabilities of data and database management systems by providing additional integrative services and access. A theoretical example is the development of a database that integrates other databases and then provides the integrated product via the world wide web.
1.5 Data Acquisition and QualityAssurance (QA) and Quality Control (QC)
Ecological data are usually collected using paper and then transferred on to computer for analysis and storage. There is also an increase in the use of automated data collectors which record data directly onto a computer. Normally, the fewer the times data are transferred, the lower will be the errors introduced. Ideally the transfer of data from one form to another should only occur once, with appropriate QA and QC procedures during the process.
Paper data forms
Paper is one of the primary tools used to acquire data. The development of suitable data sheets is therefore important.
Prior to data collection each page should contain basic information on the study for which it is to be used. Each page should be numbered and contain a section for comments and metadata (like date, weather conditions, names of the collectors, etc). Where possible, each page should reflect the design structure of the data set. This single requirement will greatly reduce entry errors and greatly facilitate QA and QC procedures.
Tape recorders
Tape recorders can provide a high quality, efficient method of collecting data that can be easily operated by a single person in the field. The recorded observations can then be transcribed to paper or entered into computer files under the more favourable conditions of the laboratory.
Hand-held computers
Acquiring data with hand-held computers is probably the best way of obtaining high quality data especially if combined with point-of-entry data quality checks.
Automated data acquisition systems
After the data is acquired automatically it is subsequently downloaded or transferred to another computer for processing. Small data loggers are also widely used and are an efficient way of collecting continuous sensor data. On the negative side, they usually require considerable programming and electronic expertise and must be routinely downloaded as their physical memory is usually limited.
Quality assurance and quality control
QA and QC mechanisms are designed to prevent data contamination (the introduction of errors into a data set). Commission and omission are the two fundamental types of errors that can occur. Commission errors include incorrect or inaccurate data. These can be derived from a variety of sources including malfunctioning instrumentation and data entry and transcription errors. Such errors are common and are relatively easy to identify. Errors of omission, on the other hand, may be much more difficult to identify. Omission errors frequently include inadequate documentation of legitimate data values (affecting the way a given data value is interpreted).
QC procedures can be very effective at reducing errors of commission. Control mechanisms are usually constructed in advance and applied during the data acquisition and transcription process to prevent corruption and contamination.
QA procedures are used to identify errors of omission and commission. QA mechanisms can be applied after the data have been collected, transcribed, entered in a computer and analysed.
Combined quality control and assurance procedures for ecological data include four actions which range from relatively simple and inexpensive to sophisticated and costly. The four actions are:
i. Defining and enforcing standards for formats, codes, measurement units and metadata.
ii. Checking for unusual or unreasonable patterns in the data.
iii. Checking for comparability of values between data sets.
iv. Assessing overall data quality.
Most QA/QC is typically in category 1. The most basic element of QA/QC begins with data design and continues through to data acquisition, metadata development, and preparation of data and metadata for submission to a data archive. Examples of QA/QC for each of these stages are listed in Table 1.
1.6 Data Documentation (Metadata)
Metadata or 'data about data' describe the content, quality, condition, and other characteristics of data.
Without supporting metadata, the data would be meaningless. Metadata can easily be more extensive and complex than the data it is associated with.
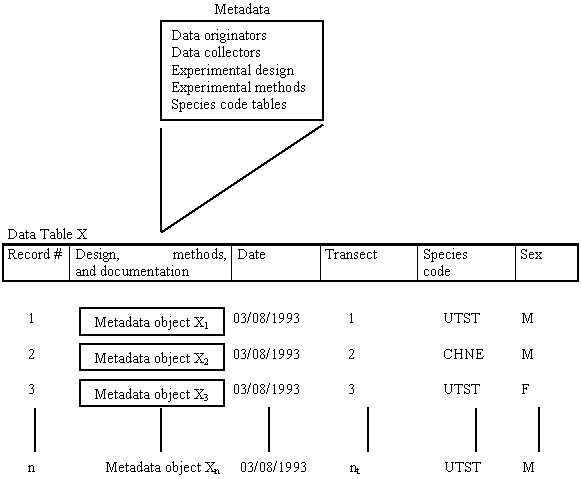
The metadata needed to understand a observation should be compressed to fit under a single attribute in a table. The experimental design, sampling methods and other supporting documentation are a fundamental and logical component of each data record (Figure 2).
1.7 Archival Storage and Access
Data stored in a computerized information system may be of tremendous value. This value is determined not only by what is stored, but how it is stored. The type of storage device, the format of the stored data and the types of access available to the data have a significant influence on the ultimate value of the stored data. Ideally (once entered and verified) data are transferred to an archive file or format. The archive file then becomes the reference version of the data, regardless of whether it exists locally or in a formal data archive. All subsequent alterations should be carried out on the archived file or a copy of the archived file, which will then replace the original. This helps avoid the proliferation of ‘offspring’ files containing different versions of the data.
Tape or optical disk backups should be made of data that are archived online. Backups should be placed in two or more locations off the premises to protect against data loss. It is important to keep these and on-site copies up-to-date.
Table 1. Quality assurance and quality control procedures that are associated with data design, data acquisition, metadata development and data archival in a comprehensive data management system.
|
Quality assurance and quality control (QA/QC) Check that: |
Design |
Acquisition |
Metadata |
Archive |
|
Data sheets represent experimental design |
+ |
|
|
|
|
Measurement units are defined on the data sheet |
+ |
|
|
|
|
Attribute names meet project standards |
+ |
|
|
|
|
Date, site, and coded values meet project standards |
+ |
|
|
|
|
Attribute names and descriptions are provided |
+ |
|
|
|
|
Data are complete |
|
+ |
|
|
|
Data entry procedures were followed |
|
+ |
|
|
|
Information such as time, location, and collector(s) was included |
|
+ |
+ |
+ |
|
Measured data is within the specified range |
|
+ |
|
|
|
Data values or codes are represented correctly |
|
+ |
|
|
|
Data is formatted correctly for further use |
|
+ |
+ |
+ |
|
Data table attributes are reasonable |
|
+ |
+ |
+ |
|
Data table design reflects experimental design |
|
+ |
+ |
+ |
|
Values for each attribute are represented in one way |
|
+ |
+ |
+ |
|
Errors and corrections are recorded |
|
+ |
+ |
+ |
|
Metadata are present |
|
|
+ |
+ |
|
Check metadata for content (accuracy and completeness) |
|
|
+ |
+ |
|
Data glossary is present and accurate |
|
|
+ |
+ |
|
Measurement units are consistent |
|
+ |
+ |
+ |
|
Data and metadata are complete |
|
|
|
+ |
Figure 2. Hypothetical relationship of the design, methods, and metadata (represented as a single object) associated with the ecological observation. The metadata object becomes a logical and obligate part of the primary key to each observation.
1.8 Data Administration
Data can originate from a variety of sources and be stored in many locations in a number of formats. This variation makes administration of the data management system an important task. The purpose of data administration is to coordinate the storage and retrieval of computerized information and to oversee the implementation of data management policies and procedures in larger projects. An important task of the data administrator is to establish measures for data protection, for example, by having data backup and recovery procedures.
Data access policy
Guidelines need to be established on the level and type of access allowed by the different users. Access rules can be controversial and may have to be dealt with on a case-by-case basis.
Data management personnel
Project data management has high resource and labour demands. In large projects, a data manager, information manager or a data administrator directs this effort. There is an important distinction between a database manager and a data manager. A database manager deals with the technical issues involved in storage and retrieval of data from the database management system. While a data manager, data administrator or information manager deals with the administration and management of all project data, not just the data stored in a database management system.
![]()
![]()
![]()