![]()
![]()
![]()
A scientific database is a computerized, organized collection of related data, which can be accessed for scientific inquiry and long-term stewardship. Scientific databases allow the integration of dissimilar data sets and allow data to be analysed in new ways, often across disciplines, making new types of scientific inquiry possible.
There are several advantages in developing and using scientific databases. First, databases lead to an overall improvement in data quality. The rise in user numbers increases the frequency of detecting and correcting problems in the data. A second advantage is the cost. It generally costs less to save than to recollect data. Also, in many cases uncontrollable factors (such as weather, population influences and ecosystem processes) make data recollection impossible, at any cost.
The development of a database is an evolutionary process. A database will serve a dynamic community of users during its lifetime and will need to change to meet their changing requirements. For this reason four questions need to be asked.
i. Why is database needed?
ii. Who will be the users of the database
|
It is an important question because-
|
iii. What types of questions should the database be able to answer?
|
This will determine how the data will be structured within the database. The data could be structured to maximize the efficiency of the system for the most common types of queries, or multiple indices of the data could be provided to allow different types of searches. |
iv. What incentives will be available for data providers?
|
All database are dependent upon one or more sources of data. The current scientific environment provides few rewards for individuals who contribute data to databases. |
2.1 Types of Database Systems
Database systems have a central structure that governs the basic working and function of the database. This structure is either part of the database management system software or is defined within the code of more homegrown systems. Today, most systems use a relational database structure but other systems also exist which may be more suited to certain types of data (see Table 2).
2.2 Relational Databases
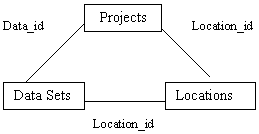
Relational databases are by far the most used database models and are widely used for scientific databases. This is probably because relational databases allow data to be structured in a similar way as hierarchical and network databases but it then allows inter-relationships to be specified based on key values of the data themselves. It is therefore relatively easy to revise the structure of a relational database by changing or adding links between data (Figure 3). These features have made the system popular with users.
Table 2. Database system types and characteristics.
|
Database Type |
Characteristics |
|
File-system-based |
Uses files and directories to organize information. Examples: Gopher information servers (not typically considered a DBMS) |
|
Hierarchical |
Stores data in a hierarchical system. Examples: IBM IMS database software, phylogenetic trees, satellite images in Hierarchical Data Format (HDF) |
|
Network |
Stores data in interconnected units with few constraints on the type and number of connections. Example: Cullinet IDMS/R software, airline reservation database |
|
Object-oriented |
Stores data in objects each of which contains a defined set of methods for accessing and manipulating the data. Examples: POSTGRES database |
|
Relational |
Stores data in tables that can be linked by key fields. Examples: Structured Query Language (SQL) databases such as Oracle, Sybase and SQL server, PC databases such as DBASE and FoxBase |
Figure 3. Relational database structure
2.3 DBMS Software Considerations
The choice of database software will be governed by the tasks that the software is expected to accomplish (e.g. input, query, sorting and analysis). Simplicity is the key.
Many useful functions including the ability to sort, index and search data are built into DBMS software. Large relational databases also include extensive integrity and redundancy checks. These databases can also support transaction processes with ‘rollback’ capabilities, which allows the recreation of the database as it existed at a particular time.
2.4 Interacting with the World Wide Web
An important innovation to DBMS is the introduction of software that enables DBMS to interact with word wide web (www) information servers. This allows a whole range of dynamic www pages to be produced. These pages, called web applications, allow users to retrieve and contribute data and metadata through a common and familiar user interface.
2.5 Data Modelling and Normalization
In database creation, the DBMS constitutes the canvas, but the data model is the painting. The purpose of a data model is to explicitly define the entities represented in a database and to spell out the relationships among these different entities (Figure 4). Ultimately, the data model will be used as the road map for the definition of tables, objects and relations.
Normalization is the process where a data model is reduced to its essential elements. The aim of normalization is to eliminate redundancies and potential sources of inconsistency. During the normalization process, it is not unusual to define new entities and attributes or to eliminate old ones from a data model.
Figure 4. Example for an entity-relationship diagram.
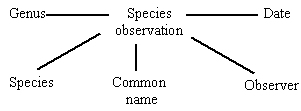
Table 3. ‘Deep’ vs. ‘wide’ databases.
|
‘Deep’ databases |
‘Wide’ databases |
|
· Specialize on one or a few types of data. |
· Contain many different kinds of data. |
|
· Contain large amounts of observations on one (or a few) types of data. |
· Contain many different kinds of observation, but relatively few data of each type. |
|
· Provide sophisticated data query and analysis tools. |
· May provide tools for locating data, but typically do not have tools for analysis. |
|
· Tools operate primarily on data content. |
· Tools operate primarily on metadata content. |
2.6 Examples of Scientific Databases
Based on their content, scientific databases can be placed into one of two categories, deep or wide (see Table 3). ‘Deep’ databases specialize in a single or a few types of data and implement sophisticated search and analytical capabilities.
‘Wide’ databases are data collections that attempt to contain all the data related to a specific field of science.
Databases that can be classified as wide are project-based databases. These databases support a particular multi-disciplinary research project and may include a wide range of data specific on a particular site or research question. Databases at Long Term Ecological Research (LTER) sites are a good example. These databases contain a wide range of ecological data (e.g. weather and climate, primary productivity, nutrient movements, organic matter, trophic structure, biodiversity and disturbance data), along with site management information (e.g. research directories, bibliographies and application proposals).
There are a number of essential requirements that a database must have to be successful with users.
i. The data it contains must be wanted by a group of users.
The data must also be up to date and complete. The datasystem must therefore be easy to update and data providers should be given suitable incentives to update the information.
ii. The data must be presented in an attractive format to the user.
iii. The technological expertise needed to use the system must be compatible with the users.
iv. A mechanism of dialog is needed to deal with user inquiries and for identifying unmet user needs.
A database to be successful must meet all of these requirements.
![]()
![]()
![]()