![]()
![]()
![]()
In his vision of the Semantic Web, Tim Berners-Lee (Berners-Lee 2000) outlines an architecture for the Web that is multi-layered and machine processable, as depicted in the much-reproduced image in Figure 1. The layers with which we will principally be concerned are the resource description framework layer and the ontology layer. The XML layer will be touched upon insofar as it addresses the issue of content.
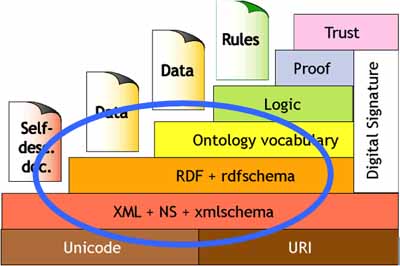
Figure 1. Layers of concern for the development of semantic standards in European Ethics.
The XML layer is concerned with the description of what a document or resource is about. Inasmuch as data that is proprietary to an application has limited use, the XML layer provides for standardized means of describing content in order to free up that content for use by any number of applications.
Domain-specific XML tags can be used to mark up the content of a resource at various levels of granularity ranging from the level of the resource itself (i.e., to describe what the resource is about using descriptor terms or abstracts) down to the level of the section or passage within the document (if it is a text), to the sentence-level, to the level of a single term (i.e., to describe what the term means or refers to). In the case of structured data such as databases, the database itself might be described, or the fields of the database might be semantically indexed.
The level of granularity at which data is indexed is directly related to the types of queries the user can ask and the types of results that can be retrieved. If resources are marked up coarsely, such as at the level of the website (or individual pages on a website) or metadata record, then the user's query, normally in the form of one or more keywords, will retrieve a set of links that either contain or are associated with (via, for example, matching strings in the resource's metadata) the user's keywords. This option limits resources to those that can be identified via a URL or metadata records retrieved via a SELECT SQL query. Contrastively, at finer-levels of marking up information, such as the chapter of a book, or a passage, the results retrieved can be more directly targeted to the user's query, more so than matching keywords against metadata describing a document or URL, which may not contain the information needed by the user. For instance, if the user is looking for information on the health hazards to humans of pesticide use in Africa, she might indeed find a document keyworded with (or having significant frequencies of occurrences of) "pesticides", "health hazards", and "Zambia," but the document might be about the removal of these substances, or the amount sold of those types of substances, or regulations about their use, etc., rather than about the ways in which they are hazardous. This is because there is little or no indication of what the relationship is between the terms used to describe a given resource and the resource itself, or among the terms themselves. When information is described below the level of the resource, retrieval results may match user queries more effectively. So an article containing a section on pesticides, health hazards, and Zambia would be indexed differently, and ranked at a higher position than one containing one section on pesticides and health hazards and another on Zambian culture. At the finest level of mark-up, where individual words are indexed, the system understands the meaning of each term in a sentence, as well as its relation to other terms. In such a system, the user can issue a well-formed question as a query, and the result elicited would be in the form of an individual sentence, based on an analysis of the user's query and a search for the best match among the sentences within the resources. For example, it would be possible for the user to input "What are the health hazards of pesticides used in Zambia?" and for a direct response to be in the form of a sentence drawn from resources, e.g., "Pesticide use in Zambia are associated with the following toxic effects."
Within the domain of ethics, content description is initially envisaged at the metadata level, within the RDF layer (cf. next section), using controlled vocabularies. Thus, what can be retrieved are resources such as experts, software, and document-like information objects[2] or DLIOs (as opposed to individual answers, discussion threads, or text passages). This is mainly for practical reasons, given that there already exist numerous bibliographical databases that contain descriptions of bibliographic metadata using controlled vocabularies. The database structures can be studied to develop the initial version of the EEAP and the EEAO, while the controlled vocabularies can serve as the basis of further developing the EEAO. However, it must be stressed that this is a starting point, and that more sophisticated systems can be developed once the EEAO has been extended using vocabularies containing rich semantics.
The RDF layer contains information about a resource, viewed externally, that is, from outside the resource, and includes information such as its title, author, and publisher. This information that describes a resource is called metadata. Standardized XML tags can be used to mark up metadata. For resource description, there already exist standards such as the Dublin Core Metadata Element Set[3] (DCMES). What distinguishes, however, the lower XML layer, which merely describes a resource, from the RDF layer is that the latter is able to express relations between resources. In contrast to the WWW, where associations, i.e., hyperlinks between resources are meaningful to the extent that they are interpretable by humans (e.g., while a human could understand why a string President Bush would be hyperlinked to an image of the American flag, to a computer, such a relation would be indistinguishable from any other text that was hyperlinked to an image). RDF provides a standardized format for uniquely defining resources and a well-defined syntax for making statements about those resources. Figure 2 exemplifies the type of statements that RDF allows about a resource.

Figure 2. [resource] --dc:title--> v[dc:title]
As mentioned, for developing an integrated information service for the domain of European ethics, resources will be described using an application profile (AP), metadata elements that are drawn from one or more standardized metadata element sets that may also be extended and customized to the types of resources to be provided by the information service. This will allow resources to be described using standard mark-up languages that, on the one hand, are independent of local platforms and applications and, on the other hand, can enhance the possibility of semantic interoperability of resources within the domain. In section 3, we specify a methodology to develop an AP for European ethics.
In the RDF layer, resources are defined by virtue of their relationships to other resources. The ontology layer offers, in addition, the possibility of reasoning within the domain through precise specifications of concepts, relations, and rules, thereby creating the possibility of inferring new data from existing data. In other words, an ontology provides a knowledge model of a given domain that can interface with the RDF layer via mappings to its metadata elements. The model is made explicit via a knowledge representation language. Although many such languages exist, we use OWL Web Ontology Language[4], the W3C standard knowledge representation language that offers rich semantics and is native to the Web (i.e., is serialized in XML).
For the domain of European ethics, we distinguish two levels of knowledge to be represented: (1) One consists of the root ontology, where concepts, relations, and rules corresponding to the resource metadata will be specified for and mapped to the elements comprising the aforementioned application profile. (2) The other consists of all other ontologies derived from knowledge organisation systems such as thesauri and terminologies that can extend the root ontology. These other knowledge organization systems may provide a set of valid metadata values for resource attributes, or they may comprise an entire (sub)ontology in their own right that can extend the root ontology.
|
[2] A DLIO is a unit that is
comparable to a paper document. The term is used to indicate resources such as
websites, presentation files, photos, etc. but may not cover, for example,
organizations or projects. [3] Dublin Core Metadata Initiative http://www.dublincore.org/ [4] Cf. the OWL Web Ontology Language Overview (http://www.w3.org/TR/2004/REC-owl-features-20040210). |
![]()
![]()
![]()