![]()
![]()
![]()
In the previous section, we outlined the parts of the Semantic Web architecture with which we will be concerned for the development of a semantic integration solution for European ethics, as we have defined it. In this section, we will define the terminologies we are using and discuss explicitly the rationales and the methodologies for the development of those components.
An application profile (AP) is a flexible, platform- and architecture-independent, information exchange format to facilitate the exchange of information resources via the Web for a given project or application. It consists of data elements (i.e., XML tags), drawn from one or more namespaces (i.e., named collection of elements and attributes), combined together and optimised for a given domain. By reusing elements specified in already-existing metadata standards, such as the DCMES, the AP transcends proprietary systems and organizational boundaries, and thus creates the possibility of improving management of and accessibility to domain-specific information materials.
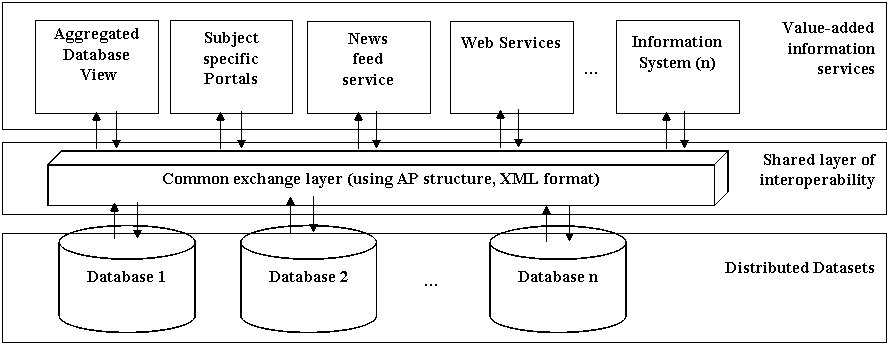
Figure 3: Interoperability between datasets allow for creation of value-added services and systems
Figure 3 shows the use of an AP as a common exchange layer to resolve the heterogeneity among information systems, and as a basis for the development of value-added services.
An AP prescribes the vocabulary, content, and structure rules that can be used to share information between heterogeneous datasets without requiring any change to the local system. With the possibility of using tools such as XSL Transformation (XSLT)[5], the information extraction and conversion becomes a simple yet extremely important task towards facilitating interoperability. The fact that the resource itself does not have to be attached to the metadata makes it easy to control access rights on it.
The process of converting domain-specific data from a non-XML-native db to an AP is illustrated below, in Figure 4.
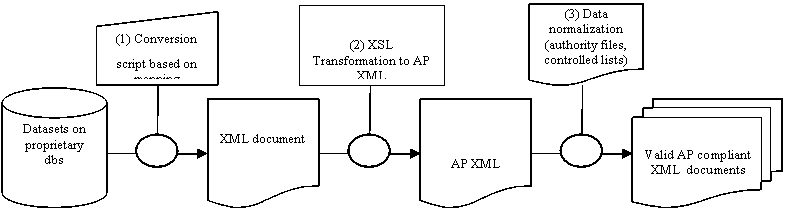
Figure 4: Converting from a proprietary dataset to the AP
The first step (1) involves mapping the local data model to the AP, and then either creation of a conversion script or direct export of data into XML (as allowed by some databases). In the next step (2), XSLT is applied to convert the simple XML document into the AP compliant XML format. In the case of native XML database this step might not take place. The last step (3) comprises data normalization, which ensures not only that the XML file validates correctly against the EEAP DTD but also that all the requirements, such as use of controlled vocabularies or declaration of used schemes, are met.
The next section describes the methodology for developing the AP in the domain of European ethics.
The creation of the EEAP will involve several phases.
Phase 0: Definition of the project, its goal, and its scope
The first and foremost task is to specify the goals of the project, especially in terms of its short-term and long-term objectives. This allows the scope of the project to be defined in order to keep the work within its boundaries. In the case of the project to develop an integrative information system for European ethics, the following goals are identified:
1. provide a platform independent exchange format that can alleviate the semantic heterogeneity characterizing the resources provided by the 200-some information systems identified thus far;
2. do the groundwork to enable information service providers of ethics resources to achieve digital information management standards for the next generation Semantic Web.
The solution for the first goal is clearly to provide a format, such as XML, that will not bind data owners to any specific information system yet allow them to share their data, regardless of the platforms and technologies they are using. These resources can remain distributed and can use either Hypertext Transfer Protocol or Web Services to perform multi-host searches, or they can be centralized to a single database. If they remain distributed, Web Services is recommended both for scalability and for automatic discovery of resources, especially for the future, when the adoption and implementation of semantic technologies (presumably) becomes more widespread. The second goal, which depends on the first, as well as on the development of the ethics metadata and subject ontologies (defined above in section 2), provides a means of converting data into machine-processable smart data, a prerequisite for transformation of the WWW into the Semantic Web.
As shown in Phase 1 below, a review of the resource types identified by the initial surveys of the ethics information services indicates that in all likelihood, it will need to be extended to include not only DLIOs but other entities such as institutions, individuals, and projects, and even services provided by collaboration software and texts generated by means of those services.
Phase 1: Assessment of the information objects
The major objective of this phase is to specify the range of resource types comprising the ethics domain. Within the domain of European ethics, the following resources have been identified thus far (cf. Hopt et al. 2004 and Denger 2004b)[6]:
internet portals, link collections, personal web pages, web pages of institutions and organisations
databases: institutes, experts, literature, press articles, multimedia files, bibliographic data, projects, events
publications: journals, newsletters, book excerpts, online texts
collaboration software: discussion fora, calendars, event notification service, etc.
Once the actual resource types to be accounted for has been determined, for example, through user surveys, web logs, etc., each needs to be analyzed to determine the properties characterizing it. Such analyses establish the initial requirements for specifying an ethics application profile. Non-traditional information objects such as institutions and collaboration services may also need to be considered. Note that different types of resources will be described using different criteria. For example, part of an adequate description of a book should include information such as its title and its identifier, which usually is expressed as an ISBN. An adequate description of a journal article should include not only the title of the article and its ISSN but also the title of the serial. In contrast, to describe an individual, information such as the employing institution, the individual's title, research areas, and email address, might be deemed crucial.
Phase 2: Assessment of the existing metadata standards and creation of the AP
As shown above, different types of resources exist within the domain of European ethics: DLIOs; non-DLIOs such as persons, institutions, events, and projects; and services provided by collaboration software.
Because many of the resources are in fact document-like resources found in digital library collections, a natural starting point from which to create an AP is the set of standards proposed by the Dublin Core Metadata Initiative[7] (DCMI). The DCMI has come up with a set of widely accepted elements, refinements, and schemes, such as the DCMES, mentioned previously, for the description and discovery of resources. The DCMES is clearly defined yet shallowly scoped to serve the aim of wide applicability, i.e., cross-domain description, discovery and retrieval of information objects. It is also extensible in that additional elements, refinements or schemes may be added. However, this extensibility has to be controlled as it can be counterproductive to achieving the aim of interoperability.
Other entity types for which suitable metadata standards must be found or developed. For instance, for describing persons, the suitability of standards such as vCard and FOAF can be assessed.
Phase 3: Developing new properties.
Because currently available metadata standards may not be sufficient to cover all of the needs particular to ethics, rather than extend the current standards beyond recognition, a metadata element set specific to the domain, European Ethics Metadata Element Set (EEMES), can be developed to act as an umbrella namespace under which new elements that are deemed necessary for resource description in the domain of ethics can be declared.
The initial step is to determine a set of properties needed to describe the different resources available in ethics independently of any given standard. This process helps to decide if a particular property is really needed to describe the resource. Table 1 outlines the series of questions to be posed for determining the necessary properties.
Table 1. Determining the necessary properties to describe a given type of resource.
|
Is the elements/refinement/scheme really required for supporting:
|
Then, with the properties deemed necessary (for description and searching), another sequence of questions, shown in Table 2, concerning each of these elements is posed, again in iterative fashion[8].
Table 2. Determining the need for a new element.
|
Once it is determined that the need for a given property exists, then:
|
This task of trying to match each property to an existing element, refinement, or scheme is meant to avoid reinventing the wheel. One consequence is that all declared elements, refinements and schemes in EEMES may end up looking like a hodgepodge. To make sense of them, they would need to be seen along with their parent. Two further steps are necessary for implementing this phase.
(a) Provide the ISO/IEC 11179 metadata for each element, refinement and scheme in the EEMES namespace
Once the elements, refinements, and schemes are given entry into the EEMES, they should then be carefully described using the ISO/IEC 11179 standard for the description of metadata elements. The use of the ISO/IEC 11179 helps to improve consistency with other communities and augments the scope, consistency, and transparency of the EEMES.
Ten attributes are used for defining the elements, all of which may be deemed suitable for meeting the project's needs.
|
Attribute Name |
Definition |
|
Name |
The unique identifier assigned to the data element. |
|
Label |
Label assigned to the data element. |
|
Version |
The version of the data element. |
|
Registration Authority |
The entity authorized to register the data element. |
|
Language |
The language in which the data element is specified |
|
Definition |
A statement that clearly represents the concept and essential nature of the data element |
|
Obligation |
Indicates if the data element is always or only sometimes required (mandatory, optional, conditional) |
|
Data type |
Indicates the type of data that can be represented in the value of the data element |
|
Maximum Occurrence |
Indicates any limit to the repeatability of the data element. |
|
Comment |
A remark concerning the application of the data element. |
The terms Name and Label are not as they appear in ISO/IEC 11179 and were modified to adhere to the terminology currently being used in the XML community. This approach is taken to facilitate the assimilation of this set into the XML and RDF communities.
Additionally, the following two attributes may also be used.
|
Attribute Name |
Definition |
|
Element Refined |
The name(s) of element(s) refined. |
|
Scheme |
The applicable schemes for encoding the values of the term. |
(b) Create the data model of the AP
The next step involves taking each of the terms and defining them in the context of European ethics. APs allow us to provide application specific definitions as long as they do not change the concepts themselves. For each element, we can provide its definition, cardinality, and data type information by giving some examples of best practice guidelines. These guidelines should try to cover as many scenarios as possible but cannot be exhaustive for practical reasons. They should suggest the use of schemes whenever possible; for example, the ISO639-2 scheme should be used to indicate the language, when necessary.
This process should be applied to all the elements and refinements.
Phase 4: Create an XML DTD or schema
The guidelines should then be converted into an XML DTD which would eventually be used to validate all the XML-based inputs to the European Ethics network. The XML DTD provides the following:
|
Logical structure of the record |
The sequence and/or nesting of elements |
|
Obligation |
If a term is mandatory or optional |
|
Cardinality |
How often can this term appear in one record (0, 1 or more times) |
Phase 4: Test the XML DTD using real data
The application profile should then be made available as both a document and also as an XML DTD, which is necessary for validating XML inputs. The guidelines should ideally be applied by an information provider for subsequent refinements of both the document and the DTD.
Once the first release of the AP is established, it will undoubtedly undergo revision. The technical implementers, i.e., those who would be responsible for converting their proprietary databases to the AP format, should be provided with documentation on how to handle the conversion. Each implementer would be given one-to-one feedback to help them successfully implement the exchange standard. In some cases, this could involve the creation of crosswalks or mappings between the local systems and the European Ethics AP.
An ontology is a shared model of a given domain whose basic components consist of a vocabulary of terms, a precise specification of those terms, and the relations between them. Although an ontology has a structure similar to that of a taxonomy, the real power of an ontology comes from the ability to go beyond the information encoded in the structure to generate new information through inferencing. Using an ontology creates a separate knowledge layer distinct from any local information technology, information architecture, or application. It is more scalable than traditional methods of integration, where fields from separate data sources are mapped to each other. In traditional methods, the addition of a single database to be mapped to n databases requires n mappings from each field in the new database to each corresponding field(s) in the other n databases. Moreover, drawing the correspondences between fields from the new database to those in the others requires an understanding of the semantics of each field in each database. Thus, the task of integrating every new database to the system, or indeed, making a change to any one of the databases, becomes more and more unwieldy, increasing by an order of magnitude the number of mappings to be carried out[9]. However, when the knowledge layer is abstracted away from the details of a specific application, each new system has only to perform a single mapping in order to communicate with the other systems. This facilitates management of and communication among otherwise heterogeneous systems.
By definition, a standardized metadata element set consists of uniquely defined concepts that are in specific relations to each other. Whether explicit, as in the relationship between translations of corresponding resources, e.g., the ags:isTranslationOf element, or implicit, as in the relationship between a resource and its file name, the semantics of those elements can be expressed via an ontology.
The European Ethics Application Ontology (EEAO), is the root ontology of the system. The representation of resource metadata elements as an ontology is motivated by the recognition that, as far as a resource metadata is concerned, the normally underexploited semantics existing between extrinsic descriptors of resources could be used to enhance the user's information retrieval/knowledge acquisition experience. For example, nearly all bibliographic metadata contain the following assertions.
[resource] dc:creator v[dc:creator]
[resource] dc:subject v[dc:subject]
where v represents the value of the property.
A simple but useful inference that can be drawn from these assertions is
v[dc:creator] hasWrittenOn/hasPapersAbout dc:subject
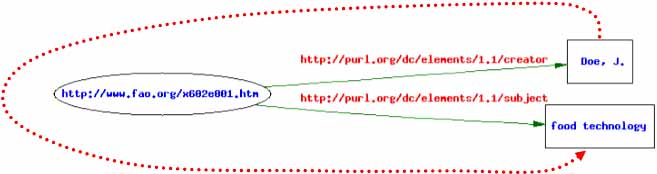
Figure 5. v[dc:creator] hasWrittenOn/hasPapersAbout dc:subject
as shown in Figure 5.
An application such as a search engine could make use of such meanings not asserted by the metadata or the resource (e.g., to make suggestions to the user, to enhance the user's learning experience, etc.). Yet, rarely do bibliographical information retrieval systems take advantage of the ability to make these kinds of inference.
Other metadata standards describing other types of resources (e.g., events, experts, etc.) are treated analogously.
Figure 6 depicts the three-tiered organization outlining the relationships between the resource, the metadata elements from, in this case, the AP, and then the application ontology.

Figure 6. The three-tiered relation between Resource, Metadata, and Ontology.
The resource metadata is marked up using the AP. The AP elements and the relations between them correspond to concepts and relations in the application or root ontology that make it possible to generate new information through the extraction of inferences. To take a simple example, a search for any publication associated with a given organization could also yield, by inference, the email address of the institution responsible for that publication. Indeed, in the future, with the use of the W3C standard for OWL, this inference could be made even if the information about the email address and the publication were on different websites.
Query: "Kennedy Institute of Ethics" "publication"
Result: website containing information about the Kennedy Institute of Ethics Journal
Result based on inferencing: email address of Kennedy Institute of Ethics
Using the EEAO as a root ontology to express the semantics of metadata descriptors (e.g., title, creator, publisher) considerably enhances the value of the resources that are described, even without the use of subject keywords to describe their contents. As mentioned above, formalizing the semantics of the metadata of European ethics resources already expands the knowledge provided by the ontology, via inferences, concerning resources. That is, by virtue of explicitly asserting that resources have certain attributes like author, publication year, and keyword, other information, such as number of articles written about a given topic within a range of years, can be extracted through reasoning across those assertions.
However, the ontology can be further extended beyond basic bibliographical metadata. On the one hand, subtypes of concepts already existing in the root ontology can be added. For instance, the dc:creator concept subsumes the sub-concept ags:creatorPersonal[10], from which more specific concepts such as main author and alternate author can be derived. On the other hand, the root ontology can also be extended through the incorporation of controlled vocabularies. These vocabularies may simply consist of a flat list of terms, such as language codes. When the controlled vocabulary has some explicit semantics, as does a thesaurus, it lends itself to realization as a sub-ontology. These extension types are elaborated in the next two sections.
Addition of sub-concepts
As mentioned previously, Dublin Core, whose semantics is being used as the basis of the EEAO root ontology, was deliberately designed to be shallow. This shallowness allows for flexibility in its applicability to the specific needs of a given domain or application. For instance, a need may arise within European ethics to distinguish different kinds of authors (e.g., personal authors are often also experts and should thus be considered resources in their own right while corporate authors might be associated with institutions that can provide other information, e.g., events, etc., relevant to the domain). Consequently, the concept dc:creator can be further refined to the more specific concepts ags:creatorPersonal and ags:creatorCorporate.
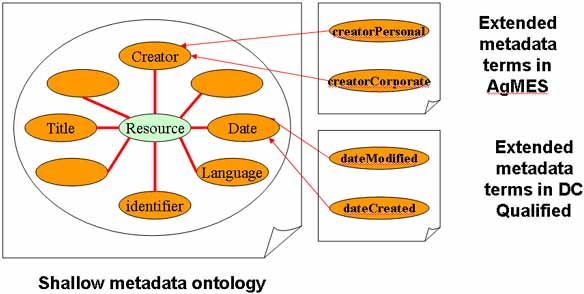
Figure 7. The shallow metadata ontology can be extended with terms
Controlled vocabularies
Controlled vocabularies are terminologies consisting of a set of terms and associated meanings that have been standardized for searching for and describing resources. They often represent the intellectual work of experts and/or standards bodies that can and should be reused both to avoid reinventing the wheel and also to increase the possibilities for interoperability. In general, we will be concerned with, on the one hand, the controlled vocabularies whose terms occur as flat lists without identifiable relations among them and can be used as valid metadata values (e.g., language codes), and those, on the other hand, with rich(er) semantics whose terms and relations can be used for the development of sub-ontologies (e.g., domain specific glossaries).
Valid attribute values
Their main distinguishing features are that they tend to occur as a flat file and/or as short lists without any systematic semantic structure among their elements. Examples include language codes, identification types for bibliographical resources, and abbreviations. These kinds of controlled vocabularies supply a set of valid values for specifying resource attributes. For instance, the values of the scheme attribute of the dc:identifier element identifies the type of number, e.g., ISBN, ISSN, etc., which indicates the type of resource, i.e., whether it is a book, a journal, and so on. Within the Agris AP, the allowed values of scheme have been defined to be ags:isbn, ags:issn, ags:arn, etc.
<dc:identifier scheme= "ags:isbn">1234567</dc:identifier>
Using controlled values is another way of unambiguously defining the semantics of a concept, in this case, one of its properties. It enhances its interpretability by both humans and machines.
Sub-ontologies
Vocabularies that contain rich semantics occur with some indication of the meanings of their terms, whether accompanied by prose definitions where the semantics is interpretable exclusively by humans, as in a glossary or dictionary, or situated within a more or less machine interpretable context of terms linked through explicit relations, as in a taxonomy. These kinds of vocabularies tend to describe the concepts and relations that make up a given domain. In terms of the EEAO, the vocabularies in question describe the content of resources, as opposed to their external characteristics such as author, publisher, and so on. Vocabularies such as thesauri are a good starting point for ontology development because they already are to some degree machine readable. Vocabularies that are primarily meant for humans, such as glossaries, may be used to extract relations to other terms, explicit relations, and other information for incorporation into the ontology. With regard to the root ontology, these domain vocabularies can be developed into a sub-ontology attaching to the root via the dc:subject concept.
Within any given domain, especially one that is as interdisciplinary as ethics, several vocabularies are likely to exist and to overlap in their coverage of the domain. They may use different terms for the same concept. Moreover, these vocabularies may have slightly different understandings of a given concept or set of concepts. That is, one provider might use gmo crop while another might use novel food to refer to the same concept. One provider may view a gmo crop as a type of plant while another might view it as both a type of plant and a biotechnological invention. The sub-ontology can act as a mediating structure for multiple vocabularies within the same or overlapping domains. Because an ontology is concept- and not string-based, terminologies can map their specific terms to the corresponding concepts within the ontology. Further, with the help of domain experts, relations can be drawn between each uniquely defined concept. Consequently, providers can maintain the use of their terminologies while also being semantically interoperable with other vocabularies by integrating them based on a common semantic structure that can specify both terminological relationships (such as synonymy) and taxonomic and other semantic relationships (such as part-of).
European Ethics Application Ontology
The EEAO is based on elements constituting the EEAP. Most of these elements are derived from already existing standards whose definitions and relations are already well-understood. Indeed, an ontology already exists for the Dublin Core Metadata Element Set (cf. Kamel-Boulos et al. 2001) that can be used both as a model and as a starting point for the construction of the EEAO. Therefore, the construction of this ontology should be relatively straightforward. Figure 8 shows the correspondences among the concepts derived from resource, the EEAP, and the EEAO.
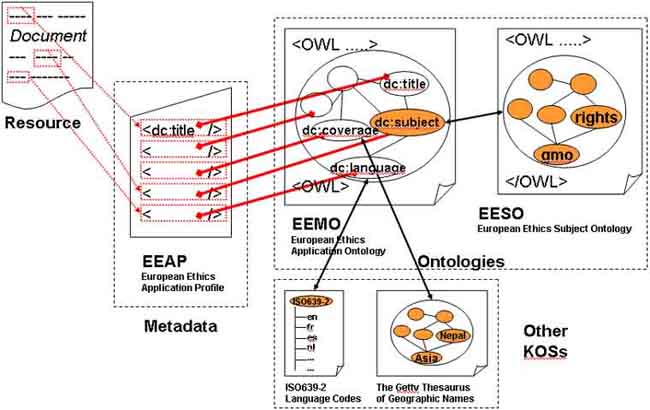
Figure 8. Corresponding concepts in the resource, application profile, and application ontology and the use of different knowledge organization systems
Extensions to the AO
Once the root EEAO has been developed, there may be additional extensions through the abovementioned subclassing of root concepts and the development of sub-ontologies. This section outlines the development of sub-ontologies using semantically rich controlled vocabularies. It considers the problem of integrating multiple controlled vocabularies covering the same domain.
Phase 1: Gather and characterize existing terminological resources in the domain.
In keeping with the principle of reuse (and in the service of interoperability), the first step is to identify the lexical resources that can furnish the raw materials, i.e., terms and meanings, from which to build the ontology. These lexical resources may involve semantics of varying degrees of explicitness (e.g., a word list only identifies concepts without definitions or relations; a taxonomy has some semantics expressed through terms connected via a hierarchy), that may or may not be machine-interpretable (e.g., a glossary is intended for human interpretation; a database scheme can be "understood" and used by a computer). They include glossaries, wordlists, thesauri, taxonomies, subject classifications, XML DTDs, and database schemes as well as ontologies. Figure 9 shows how these resources fall along a continuum, according to the explicitness of their semantics and their amenability to machine interpretation.

Figure 9. Terminological resources on a continuum of semantic explicitness. (Based on McGuinness 1999.)
Further, the degree to which the resource covers the domain in question, as well as the sub-domains covered, should also be assessed. For instance, a dedicated Ethics Thesaurus would obviously be relatively coextensive with the domain whereas a thesaurus such as AGROVOC, which is a general agricultural thesaurus, would contain only parts, scattered throughout the thesaurus, that were relevant. Other information that should be identified are:
Concepts (and their equivalents in other terminological resources)
Semantic relations, hierarchical and associative (e.g., RT)
Top-level terms for those terminologies with hierarchical structure
Depth of trees
Classes v. individuals
Annotations
Thus far, in ethics, about 20 terminological resources, whose content is of varying degrees of relevance to the domain, have been identified:
Biothics Thesaurus, published by the Kennedy Institute of Ethics
Euroethics Thesaurus, the multilingual thesaurus in Ethics
INSERM Thesaurus
Parts of MeSH, published by the NLM
Parts of CSA Life Sciences Thesaurus
Parts of Biosis Controlled Vocabulary
Etc.
With the help of subject matter experts (SMEs), those parts that are relevant to the domain and need to be incorporated into the ontology would need to be identified.
Based on the findings in phase 1, the next phase can be implemented.
Phase 2: Determine correspondences between individual terminologies and ontology model.
This phase requires analysis of each of the individual terminologies to establish the correspondences to be made to the data model of the ontology. Thus, for example, for multilingual thesauri, the following correspondences are assumed:
Terms are treated at a level distinct from the conceptual one to distinguish between meaning and form and to allow for lexical relations such as synonymy and translation.
Terms are treated differently from strings to allow for within-term relations such as acronymy, spelling variants, etc.
Concepts correspond to classes.
BT/NT are converted to superclass/subclass relations.
RT is reserved for non-hierarchical relations.
An individual is distinct from and a member of a class.
USE/UF may or may not correspond to synonymy relations (e.g., many of the USE/UF relations in AGROVOC actually correspond to super/subclass relations, antonyms, semantically related but not synonymous relations, indeed, anything but synonymy).
Note that other terminologies may have other correspondences, e.g., in an XML DTD, elements may correspond to concepts; in a glossary, each term might correspond to a concept while relations to other terms or concepts might be derived from informal definitions.
Phase 3: Convert terminologies, following the correspondences made in Phase 2, into OWL.
This stage involves the transformation of the correspondences made in Phase 2 to a knowledge representation language. Each transformation should retain information about the source terminology. The following exemplifies the concept-to-class correspondence.
Bioethics Thesaurus:
human rights ==> <owl:class rdf:id="HumanRights@BioThes">
Thesaurus di bioetika:
human rights ==> <owl:class rdf:id="HumanRights@ThesdiBio">
Phase 4: The core subject ontology: Subject matter experts (SMEs)
The core subject ontology consists of the fundamental concepts, relations, and assumptions for a given domain. In this phase, SMEs are provided with a set of questions to identify these basic notions for building the ontology. Within European Ethics, a dual-pronged approach to define the domain was suggested (cf. WP1) combining the problem-oriented perspective (e.g., laws governing the growth of crops with genetically-modified organisms) with the real-world one (e.g., genetically-modified organisms as a product of biotechnology). Thus, two sets of question types would be drawn up, e.g.,
Problem/issue oriented:
What issues exist that are of concern to anyone, etc.?
Why are they of concern?
To whom are they of concern?
Whom do they effect?
Real-world oriented:
What is the purpose/function of X?
What does it consist of?
The objective of this stage is to specify the domain-specific concepts and relations at the highest level of abstraction. The ontology that is developed at this stage then can serve as the foundation for the hierarchies identified and extracted in the next phase.
Phase 5: Identify hierarchies within terminologies.
Once the resources have been identified, they need to be classified according to the degree of explicit structure contained in the resource. Those terminologies containing hierarchical structures can be (re)used to build the structure of the ontology while those with semantics meant for human interpretation such as glossaries can serve to provide synonyms and annotations.
Phase 6: Alignment.
These top terms along with their hierarchies are then aligned to the core domain ontology created in Phase 4. If a corresponding class does not exist, and the term is pertinent to the domain, the relevant part of the core domain ontology is enriched to create a place for alignment. At least some parts of this procedure can be done automatically based on tools using a string-matching algorithm. Figure 10 shows a graphic of how alignment is done using the example given in Phase 3..
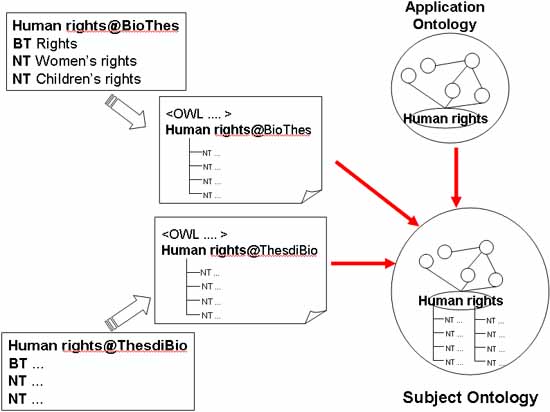
Figure 10. Aligning hierarchies from different terminologies to the core subject (i.e., domain) ontology.
Phase 7: Merging.
Merging is the process of integrating corresponding concepts from the source terminologies. In some cases, this is trivial. For example, the concept { stem cell } is homonymous in the Bioethics Thesaurus, Euroethics thesaurus, and AGROVOC, the concept { stem cells }, i.e.,
Bioethics Thesaurus: stem cell
Euroethics: stem cell
AGROVOC: stem cells
Þ core: stem cell
Thus, the three sources are realized in the core domain ontology as lexicalizations of the same concept. Tools[11] are available to help SMEs with this process.
In other cases, homonymous terms may refer to different concepts. In AGROVOC, euthanasia refers to putting animals to death, while in the Thesaurus di Bioetika, the context in which it occurs suggests that it refers to the putting a human to death as a treatment for certain medical conditions.
AGROVOC:
Euthanasia
USE Destruction of animals
Thesaurus di bioetika:
Euthanasia
BT Killing
NT Active euthanasia
NT Involuntary euthanasia
NT Allowing to die
NT Voluntary euthanasia
RT Extraordinary treatments
RT Coma
RT Right to die
RT Terminally ill
RT Treatment refusal
RT Living will
For terms referring to the same concept, e.g., GMO crop and novel food, a SME is required to make the determination of synonymy.
Phase 8: Enrich through annotations.
Comments (e.g., glosses, contexts, etc.) and identifier numbers can be mapped to the concepts. Synonyms and translations are also treated as annotations.
Phase 9: Post-processing.
Once alignment and merging have taken place, the resulting structure should be checked for inconsistencies. The exposure of such inconsistencies is facilitated using tools[12] built for such purposes.
XThes: DisjointClasses(a:female a:male)
XThes: Class(a:Sam partial a:female)
XThes: Class(a:Sam partial a:male)
Þ inconsistent
| [5] XSL Transformations (XSLT)
Version 1.0 http://www.w3.org/TR/xslt [6] Later revisions of this paper will account for survey data collected by WP2 on commonly accessed websites in ethics as well as types or resources searched for. [7] Dublin Core Metadata Initiative: http://www.dublincore.org/ [8] Adopted from original guidelines from Stuart Sutton (add URL to his presentation) [9] n! = n_P_2 / n - 2)! Where n = number of databases that want to share information with each other. [10] See the examples of extending the DCMES at http://www.fao.org/agris/agmes/Documents/Elements.html [11] Prompt and (http://protege.stanford.edu/plugins/prompt/prompt.html) and Chimaera (http://www.ksl.stanford.edu/software/chimaera) from Stanford are among those tools developed for managing multiple ontologies. [12] For instance, the OWL plug-in in Stanford’s Protégé tool is able to highlight logical inconsistencies in an ontological structure. |
![]()
![]()
![]()