![]()
![]()
![]()
Thus far, we have been placing emphasis on the use of the AO for retrieving information from structured metadata repositories. In this section, we broaden the discussion to the relationship between ontologies and data in general. That is, we show that it is possible
(1) to make use of the AO to search structured data that has not been indexed;
(2) to make use of an ethics domain ontology to search unstructured data;
(3) to make use of a semantically enriched AO at various stages of complexity.
The continuum depicted in Figure 9 shows the kinds of resources that can be incorporated into the AO to enhance the latter's semantic richness. The scenarios will be described using vocabularies taken from different locations on the continuum.
We first outline the main architectures within which the AP and AO may be contextualized. These vary along two dimensions, namely, the centralization/distributedness of the AO, on the one hand, and of the data repositories described by the AO, on the other. Then we show that while the development of semantic structures is an ongoing process, each stage can be used as the basis for solving many of the problems currently plaguing heterogeneous domain-specific information retrieval and knowledge management systems. The richer the semantics, the more possible it becomes to develop "smart" applications that not only increase the effectiveness of IR/KM but also enhance the user's experience in the process of search and retrieval.
The overall architecture integrating the AP and the AO is depicted in Figure 11. However, as shown, the system works with both structured and unstructured data.
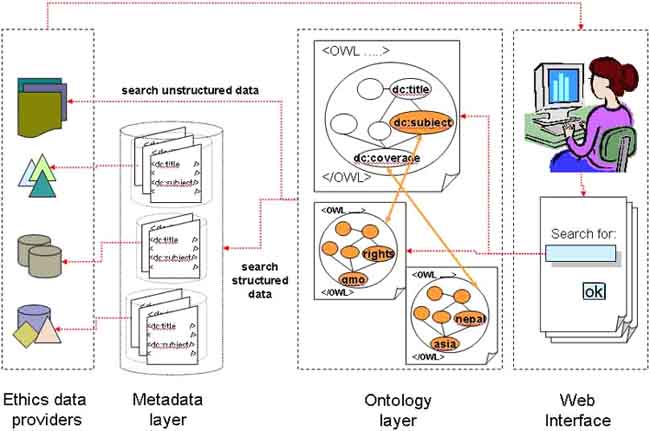
Figure 11. Integrating the ontology layers with the metadata layers.
In Figure 3, we showed graphically the role of the AP as a layer mediating, on the one hand, between heterogeneous, distributed datasets and, on the other, applications making use of the information contained in those datasets. Once owners of distributed databases have mapped their records to and exposed their content in the AP format, this mediating layer may be realized in one of two ways. Either the resulting metadata is sent to a centralized database or it is made available in individual databases that are accessible to multi-host searching. In either case, the corresponding AO will be made available in a pre-defined location so that the metadata vocabulary can be interpreted (i.e., ascribed meaning). In the future, the AO in its entirety may be stored in a registry of ontologies and accessed dynamically via Web Services technologies. However, the use of OWL to describe the AO will allow distributed storage, maintenance, and enhancement of the ontology. Applications based on the development of this AO will see it as a single ontology.
In the mediated approach, all metadata is stored in a single centralized location. Queries are first pre-processed (e.g., parsed, spellchecked, normalized for singular/plural forms) and then interpreted via the AO, where they are resolved to concepts or instances. These concepts or instances are then matched to the relevant fields within the central database. Note that, as mentioned, the AO itself may be centralized or distributed.
In contrast, in a federated architecture, databases are stored locally and made available for WWW access. As in the mediated approach, queries would undergo pre-processing and interpretation via the AO. But rather than conducting a search on a single database, the interpreted query would be sent via web services to databases hosted on multiple distributed servers and a search executed on each of those databases.
Thus, there are two dimensions to the building of the architecture: the centralization (or not) of the data, i.e., resources, and the centralization (or not) of the domain knowledge that describes those resources.
In the first scenario, the AO is exclusively based on the AP, and consequently, consists only of concepts describing resources. That is, it is the root ontology without any further extensions. In this case, relatively little analysis is required for the development of the ontological structures involved.
The concepts concern only those used to describe the extrinsic properties of resources. Controlled vocabularies or lists may provide values for the attributes of the resource, e.g., language, keyword, etc., and in such cases, should be specified; however, they are not essential for this scenario.
In and of itself, the AP already resolves, in a substantial way, the issue of semantic heterogeneity and the associated problems of maintaining interoperability among multiple distributed data repositories. However, further explicating the semantics of the AP in the form of an ontology provides the foundation for the development of semantically driven applications.
For instance, an information retrieval application based on the AO could have the following features.
The user could search resources by resource type, author, year, publisher, organization, etc.
The user could issue complex queries, such as checking to see if a given author wrote any articles written within a given time period, or if there were any current projects ongoing.
The system could present the user with information related to her query, such as titles associated with a particular author, co-authors with which a given author has written, and so on.
The user could learn about resources and their properties, e.g., discovering that the same individual who led a project promoting a certain technology also wrote a paper arguing against it, by traversing the links in the ontology.
The second scenario comprises the use of the ethics subject ontology and one or more unstructured data repositories. In this case, the SO is used primarily to help the user form effective queries using the terms and relations in the ontology for query expansion. The actual query expansion that is realized depends on whether the data repository is domain-specific, or if it is a general one such as the WWW. The richer the vocabulary (synonyms and translations), the more effective the search.
For instance, if the user is looking for information on BSE within domain-specific repositories, and he issues the query term BSE, the query would be expanded to include all of the synonyms for that concept. This ensures the greater recall of resources.
Domain-specific context
User's Query: BSE
Expansion: BSE OR bovine spongiform encephalopathy OR mad cow disease
Because the search context is limited to the domain, the problem of false positives is reduced. That is, in a repository of information on, say, bioethics, the string BSE is more likely to refer to the bovine spongiform encephalopathy concept than the Bombay Stock Exchange and thus retrieve the correct results.
Within general data repositories, the expansion strategy may be slightly different. In this case, the abovementioned query would be much more likely to retrieve false positives. To minimize ambiguity, the query would then be expanded to include the parent concept, with which it would be combined with the Boolean AND.
General context
User's Query: BSE
Expansion: (BSE OR bovine spongiform encephalopathy OR mad cow disease) AND (disease OR syndrome OR disorder)
By expanding the query to include the parent term, which disambiguates the term, false positives arising from the ambiguity of the original query are reduced.
When the contents of a repository are determined (automatically or manually) to occur in a particular language, the terms in the appropriate language can be used to expand the query in the same manner as described above. When the repository is general and multilingual, as is the WWW, a simple OR query consisting of all synonyms and translations corresponding to the user's query could be issued.
Thus, in addition to the following functionalities,
aided query formulation through query expansion
multi-lingual search
the SO also enables the user to
learn the domain vocabulary as well as the domain itself
search related terms
The third scenario comprises the root ontology with one or more thesauri containing the usual BT/NT/RT/UF relations. In contrast to the previous scenarios where semantic relations exist only between metadata descriptors but not between terms within controlled vocabularies, or only between concepts specific to the ethics domain, in this scenario, the controlled vocabularies supplying values to one or more of the concepts, usually dc:subject, contain some explicit semantics. Although the terms and relations within thesauri are often ill-defined and cannot be used for reasoning, they nonetheless contain some machine-readable semantics that can be exploited for the development of intelligent applications.
An information retrieval application based on this extended ontology can have, in addition to the features described above in the previous two scenarios, the following:
Resources containing terms related to those in the user's query, as well as the terms themselves, could be displayed.
If the user enters a query, she receives a list of results containing the metadata for the articles associated with those keywords. Clicking on an author's name retrieves all the resources containing those same keywords.
The system can help the user find the information she is searching through a series of questions that filter through the information, e.g.,
- what resource type? (e.g., author)
- wrote what publication type? (e.g., introductory text)
- about what? (e.g., keywords k1, k2, and k3)
- when? (e.g., between the years y1 and y2)
- in which language? (e.g. language l)
The third scenario is the most complex. It consists of the root AO containing concepts corresponding to all the resource types. Where a given concept is associated with multiple controlled vocabularies, those vocabularies are integrated. If they consist of flat lists, a list akin to an authority file can be incorporated into the ontology. If they contain a more complex structure, a sub-ontology can be developed that integrates the different terminologies (cf. Section 3.2.4.1.1).
Moreover, in this scenario, the knowledge itself may be distributed. Thus, parts of the root and sub-ontologies may be stored on distributed servers. Access to these distributed parts may be made via URL references or through web services.
All functionalities described in the previous scenarios are possible. Because the semantic structures are truly concept-based, other features such as
cross-language information retrieval,
terminology brokering across multiple databases using different terminologies,
intelligent query expansion become possible.
In addition, more sophisticated applications can be developed. For instance, an customizable information delivery system can filter information for people needing to monitor and assess large volumes of information. The volume of targeted information is reduced based on its relevance according to the user's "need to know." In a real-time monitoring system consisting of online RSS news feeds, the user could enter parameters of interest (i.e., concepts). A change or update in information that conforms to those parameters (i.e., that contain those or child concepts) could trigger an alert. In a well-designed robust ontology, information can be filtered independently of language or specific terms used.
A robust ontology also serves as the basis for automatic indexing of texts at multiple levels of granularity. Based on the usual statistical analyses of term frequencies, terms can be resolved to corresponding concepts in the AO (and indeed to those in corresponding vocabularies). Documents can then be tagged with those concepts. At the content level, semantic tags can be provided that allow a resource to be "better known" by one or more systems so that search, integration, or invocation of other applications becomes more effective. Tags are automatically inserted based on natural language analyses of texts.
![]()
![]()
![]()