![]()
![]()
![]()
3.1 Resources
The following resources have been singled out from the fishery information systems considered in the project:
the oneFish topic trees (about 1,800 topics), made up of hierarchical topics with brief summaries, identity codes and attached knowledge objects (documents, web sites, various metadata). The hierarchy (average depth: 3) is ordered by (at least) two different relations: subtopic, and intersection between topics, the last being notated with @, similarly to relations found in known subject directories like DMOZ.
There is one 'backbone' tree consisting of five disjoint categories, called worldviews (subjects, ecosystem, geography, species, administration) and one worldview (stakeholder), maintained by the users of the community, containing own topics and topics that are also contained in the first four other categories. Alternative trees contain new 'conjunct' topics deriving from the intersection of topics belonging to different categories.
AGROVOC thesaurus (about 500 fishery-related descriptors), with thesaurus relations (narrower term, related term, used for) among descriptors, lexical relations among terms, terminological multilingual equivalents, and glosses (scope notes) for some of them.
ASFA thesaurus, similar to AGROVOC, but with about 10,000 descriptors.
Fig. 1. A class diagram of the source data types taken into account.
Fig. 2. A state diagram that sketches the methodology used to extract and refine the informal data.
FIGIS reference tables, with 100 to 200 top-level concepts, with a max depth of 4, and about 30,000 'objects' (mixed concepts and individuals), relations (specialised for each top category, but scarcely instantiated) and multilingual support; there are modules (water areas, continental areas, biological entities, vessels, commodities, stocks, etc.), also organised by ‘views’.
3.2 Translation and refining of components for IFO building
The data from the resources that have been singled out have been processed, in order to integrate them within a homogeneous environment, and with a clear assessment of their nature. In the following we list a set of guidelines that have been followed to translate and refine data components.
A detailed evaluation of each source (find the schema -explicit or not- underlying the implementation of source data, then describe each data type both qualitatively and quantitatively) is performed.
A language to represent the KB is chosen that hosts the integration activity. A description logic like DLR [9] would an ideal choice for its compatibility with the ontology integration framework.
An ontology server is installed that supports DLR or compatible languages.
Some data types from the sources (Figure 1) seem appropriate to be included in a preliminary prototype. The following steps are performed on them:
Discuss, refine and formalise FIGIS fishery conceptual schemas [12] to build a preliminary core ontology. Also the upper-level concepts from the source thesauri should be matched against the FIGIS conceptual schemas. This results in a resource for core ontology development (R-CO.1).
Translate FIGIS reference tables: taxonomy, individuals, and local relations (to be transformed into formal axioms). This results in a resource for domain ontology development (R-DO.1).
Reuse oneFish topic trees to design a preliminary architecture for IFO library. This architecture should match the preliminary core ontology. This results in a resource for ontology library design (R-OL).
Extract ISA taxonomies from AGROVOC and ASFA BT/NT (Narrower Term) hierarchies. Heuristics from upper and core ontologies can be applied to clean up BT/NT hierarchies, for example, the following rule can be applied: if a body part descriptor is NT of an organism descriptor, then this is probably not an ISA use of NT. This results in resources for core and domain ontology development (R-CO.2,3, R-DO.2,3).
Expand RT (Related Term) relations from AGROVOC and ASFA (heuristics from ISA taxonomies is to be used). Also non-ISA BT/NT hierarchies could be refined (expanded) here. This results in resources for core and domain ontology development (R-CO.4,5, R-DO.4,5).
Reuse existing documentation: oneFish topic summaries, AGROVOC and ASFA scope notes, FIGIS glossary. Consider that documentation can be used at development time (axiomatisation, cf. §4.3.2), as well as at runtime (informal description). Runtime documentation needs a versioning tool to maintain consistency with source glossaries. Specialised ontological documentation should be provided, specially for core ontologies. This results in resources for ontology documentation (R-GL.1,2,3,4).
Reuse UF (Used For) relations and (multi-)linguistic equivalents from all resources. Track must be kept of the context from which a linguistic item has been extracted. This results in resources for ontology lexicalisation (R-LEX.1,2,3,4).
3.3 Parallel tasks
In the following sections we outline the main steps to build the basic taxonomy, documentation, and architecture for the integrated fishery ontology.
3.3.1 Developing a fishery core ontology (FCO)
Pick up uppermost concepts and conceptual (categorisation) schemas from sources and integrate them with a ‘certified’ top-level containing domain-independent concepts, relations and meta-properties. Resources:
Upper ontology resources: the OntoClean upper level [8] is a preferential choice for its compatibility with the methodology. For alternatives, see [13]. Moreover, various formal ontologies and standards for relations, and general lexical repositories like WordNet [14].
Core ontology resources: conceptual templates, (e.g. R-CO.1,2,3,4,5), relational database schemas, theoretical views on domain topics, domain standards, etc.
In the context of core ontology development, some taxonomical branches (core concepts) have relevant conceptual integration issues that are being studied by ontological engineers and domain experts in close collaboration:
biological taxonomies: difficult having a stable framework of reference (in principle, mapping from local taxonomies to a biological one is feasible, but in practice it could be not cost effective)
geographic regions: use GIS as a stable framework of reference? geographic names?
institutions: maybe automatic clustering of individuals through classification
fishing devices (including vessels)
fishing and fish farming techniques (plans and activity types)
farming systems (sets of components)
fishery regulations (norms)
fishery managament systems (plans)
production centers
Development is performed as incremental loading and classification of upper and core level ontologies in the Ontology Server. This results into the secondary resource SR-FCO.
3.3.2 Building domain IS-A taxonomies.
Integrate the resources for domain ontology development (R-DO.1,2,3) with the fishery core ontology (SR-FCO).
Resulting taxonomies could be either 'tolerated' or 'cleaned up'. Tolerance amounts to have widespread and unexplained polysemy for terms, but it is not time consuming. Cleaning is the most time consuming task, since a frequent scenario is the following: concept C from source S1 (C^S1) is in principle similar to D^S2 (usually because they share one or more terms), but they actually occupy two taxonomical places that make them disjoint according to the upper or core ontology.
The ONIONS methodology [10] in this case suggests to axiomatise their glosses (cf. 3.2.3, 3.3.3) and to check if their taxonomical position is correct. If it is not, then they are probably polysemous senses of the same term, and some alternative methods can be applied to relate those senses, to merge them, or to accept the conceptual split of the senses.
Some cleaning will be needed in any case to remove at least the major taxonomical clashes. This results into the secondary resource SR-DTA (Domain TAxonomy). Additional effort should be dedicated to distinguish:
Concepts vs individuals (heuristics applicable: country names, institutions, etc.).
Backbone concepts vs viewpoint concepts (roles, reified properties, contingent notions), cf. [7,8].
This eventually results into SR-RDTA (Refined DTA).
3.3.3 Collect existing documentation and produce glosses.
Integrate the resources for ontology documentation (R-GL.1,2,3,4).
For concepts lacking a gloss, produce a new one.
For core concepts and relations, besides existing glosses, an extensive description of their scope in the FCO should be provided. This results into the secondary resource SR-GL.
3.3.4 Designing a preliminary topic architecture.
Figure out a preliminary topology for most general topics (to be used for ontology modularisation as well). Resources:
Ontologies for topics (Welty’s topic topology [15], topic maps standard [16], OnTopic principles [11], semantic portals design [17]). oneFish topic trees (R-OL).
This results into secondary resource SR-OL.
3.4 Building domain axioms
Once taxonomies are cleaned to a certain extent, documented, and divided into appropriate namespaces, some activities aimed at raising the conceptual detail of the ontology can be started. The most important is the characterisation of domain concepts with axioms.
3.4.1 Integrating resources R-DO.4,5 and upgrading them to the status of logical axioms (formalise informal axioms).
This requires understanding the quantification applicable to those axioms: existential (necessary) or universal (contingent)?
This results into secondary resource SR-DAX.1 (upgraded Domain Axioms).
3.4.2 Axiomatising glosses from SR-GL.1,2,3,4.
Here the ONIONS methodology [10] can be applied to derive formal domain axioms from natural langage descriptions.
This results into secondary resource SR-DAX.2.
Warning: this activity is time-consuming, and semi-automatic techniques are still a research issue [13]. Scalability and approximate results should be considered for the final project phases.
3.4.3 Revising and harmonising formal descriptions from SR-DAX.1,2 according to conceptual schemata (FCO).
This results into secondary resource SR-DAX.3.
3.5 Modularising ontology library according to topics
Reconstruct dependency chains in SR-DAX.3 and check preliminary topic topology (SR-OL) to produce a first version of the ontology library architecture (OLA). Here the OnTopic methodology [11] can also be applied to derive boolean search spaces from dependency chains of topics.
3.6 Providing multi-lingual lexicalisation to elements in the ontology library
An integrated fishery ontology benefits from the existence of terms already related to concepts in the original resources, since these semi-automatically provide the so-called lexicalisation of concepts. On the other hand, having an integrated ontology also provides a powerful tool to check polysemous senses of terms, as well as to check consistency of UF thesaurus relations and consistency of multi-lingual equivalents.
R-LEX.1,2,3,4 are integrated according to SR-RDTA.
3.7 A mediation architecture
Figures 3 and 4 show two simple architectures to support information brokering [6] or unified search after merging of fishery information systems by means of Fishery Ontology Service.
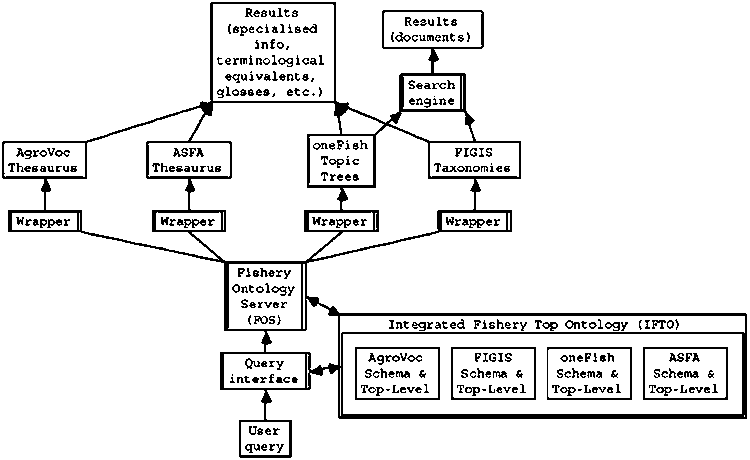
Fig. 3. A brokering architecture for querying heterogeneous fishery ISs.
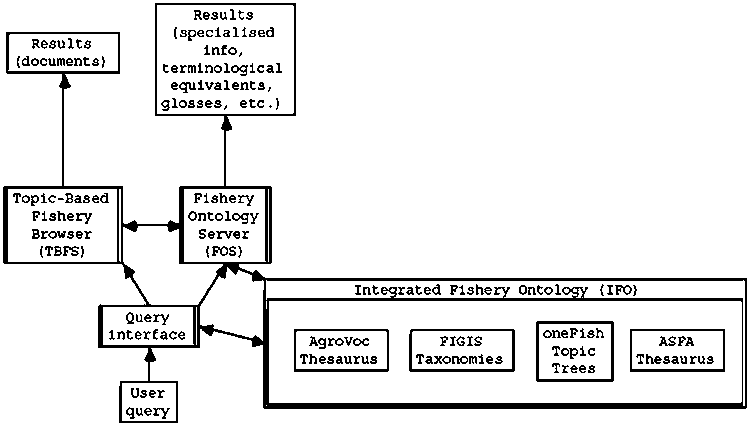
Fig. 4. A unified interface after merging of heterogeneous terminological resources.
![]()
![]()
![]()
){kind=link}
){kind=link}