![]()
![]()
![]()
The Thai AGRIS Centre is pursing its goal to expand into an agricultural knowledge centre this year, which coincides with its 25th anniversary. The knowledge management activities conducted to date and its future plans are briefly explained in the following sections.
Objective
The overall objective of the Thai AGRIS’s current activities is to transform its function from an information and resources centre to an agricultural knowledge centre. With that target, a number of projects have been proposed in three areas of emphasis:
Knowledge management
Capacity-building
IT development
Knowledge management plan
Knowledge acquisition
The plan is to assemble available agricultural information or to make it comprehensive and complete. Another activity will be to transform tacit knowledge, such as expertise of experienced academics or wisdom of local people or communities, into explicit knowledge. The acquisition process will be implemented through networking. Communication and information transfer will be carried out over the Internet using tools and methodologies developed on common standards. Coordination and collaboration will take place at three levels: organizational, personal and specialized group or interest group levels.
Knowledge formalization
In the formalization process, assembled knowledge will be systematically classified, grouped, indexed and stored according to AGRIS standards, using available tools such as the AGROVOC thesaurus. Accordingly, the centre also plans to enlarge the Thai AGROVOC to a comprehensive Thai agriculture thesaurus as standard vocabulary for indexing Thai agricultural information.
Knowledge dissemination
Disseminating knowledge to a wider audience will be done with support of tools such as web portals and intelligence retrieval service systems. To accommodate the system and make it more efficient in bringing knowledge to users, there is a necessity to cultivate a knowledge-sharing culture.
Knowledge building and application
The centre plans to develop a knowledge mapping and capability management system.
Capacity-building plan
Human resources are a critical factor for the Thai AGRIS Centre to achieve its goals. Their skills need to be developed and transformed from clerical to technical levels and therefore some routine duties will be outsourced to qualified persons. The centre’s staff will have managerial responsibilities, including general management, monitoring and quality control.
Information specialists with agriculture expertise will be trained as knowledge managers to supplement other duties of indexing and cataloguing.
IT development plan
IT development will be achieved in collaboration with the Specialty Research Unit in Natural Language Processing and Intelligent Information System Technology, computer engineering department and knowledge management research unit. The planned equipment acquisitions are as follows:
In the knowledge acquisition phase, a scanner noise-cleaning system, knowledge extraction and generalization;
In the formalization process phase, a Thai language processing system that will enhance the performance of automatic document annotation, document indexing and subject categorization;
In the knowledge sharing and accessing phase, a machine translator for accessing Web-based English information; and
In the knowledge tracking phase, a multi-viewpoint knowledge tracking system based on information extraction and ontology.
Knowledge sharing via a multilingual Web-based active reading application
The objective of this project is to develop a reading assistant for the local farmers to access agricultural information on the Internet. The system consists of two components: active reading assistant and tabular translation. The first module applies the multilingual dictionary for word-level translation while the second module translates all tables in a Web page and converts all measurement units to more locally familiar units. The experiment is based on the FAOSTAT4 corpus.
4 For more information, visit http://apps.fao.org.
This project intends to overcome reading obstacles of users by developing a Web-based multilingual active reading system. Furthermore, a word-level translation with word reordering function will be provided for whole-page translation.
Multilingual dictionary
In this project, the multilingual dictionary will serve as the knowledge base for word-level translation for many natural language processing applications, such as machine translation and cross-language information summarization. The multilingual dictionary from the Multilingual Service Working Group (http://ml-wg.cpe.ku.ac.th) will be used. This dictionary currently supports ten member languages: Bahasa Indonesian, Chinese, English, French, Italian, Japanese, Korean, Tagalog, Thai and Vietnamese. In order of generalization, English was selected as the intermediate language for lexical acquisition.
Multilingual Web-based translation
The system consists of the following four principal components:
Input analysis module to analyse information tables within the input page;
Word-level translation module to translate each cell of tables with a multilingual dictionary;
Unit conversion that converts each numeric cell whose measurement unit is not used in the target language into one of the target language; and
Output generation to produce tables and display them to the end-users.
The Web-based multilingual active reading system was developed for information exchange. This research intends to surmount the reading obstacles experienced by the local users. Currently, the multilingual dictionary with English-Thai agricultural word alignments has been completed and paves the way for the launch of the English-Thai translation.
The techniques of language engineering, namely anaphora resolution, discourse processing, named entity recognition and knowledge engineering including information and knowledge extraction techniques, will be integrated for Thai AGRIS management. These techniques will develop an information extraction and knowledge summarization system focusing on Thai documents. Its expected role is to analyse and cluster crucial themes in order to produce a corresponding domain-specific knowledge.
To improve the performance of the document retrieval system, the following capabilities should be addressed:
Information extraction. This elicits thematic information of query results and performs as a decision clue because it allows users to decide reading more rapidly.
Multiple-viewpoint knowledge tracking. This determines the relationship of the query results and can represent it by multiple-viewpoint paths of continuity; for example, the result clustered by periods, the root causes of the problems, the methods to solutions, or the reader classes.
Document taxonomies. This subsumes and represents the query results in the taxonomic fashion.
Knowledge discovery. This extracts crucial knowledge from the documents.
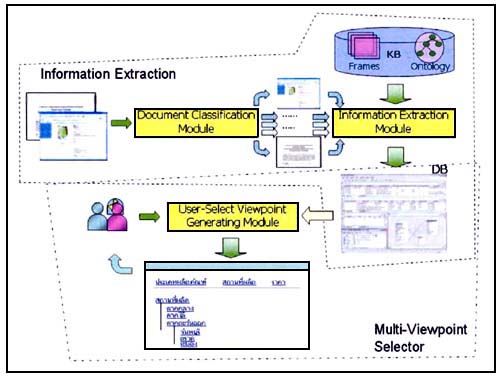
Figure 10 presents the system architecture composed of two important parts: information extraction module and user-select viewpoint-generating module. The former is responsible for extracting the relevant information from interested document by using information extraction and natural language processing techniques. An ontology will be used in both modules to aggregate data.
Figure 10: System architecture information extraction and tracking
![]()
![]()
![]()