![]()
![]()
![]()
par
Bjerne Ditlevsen
Danish Forest Service
Strandvejen 863
DK-2930 Klampenborg
Denmark
INTRODUCTION
Devant le flot incessant d'informations, les programmes d'amélioration des arbres forestiers rencontreront de plus en plus de difficultés à utiliser les données recueillies s'ils ne disposent que des systèmes d'information ordinaires. Il est donc souhaitable d'établir des systèmes d'enregistrement et de récupération des données sur ordinateur qui soient en mesure de fournir rapidement le renseignement désiré sans avoir à chercher laborieusement le dossier.
Au Danemark, à l'Arboretum d'Hørsholm, où sont en cours depuis plusieurs années des travaux d'amélioration sur l'épicea, l'épicea sitka, le mélèze et le pin contorta, le besoin d'un système d'information efficace est devenu manifeste et, en 1974, on a entrepris la mise au point d'un système d'information sur ordinateur. En 1976/77, le système a été mis sur ordinateur IBM 370/165 où la majorité des données dont on disposait déjà à l'Arboretum ont été transférées; ce transfert se poursuit en même temps que l'entrée de “nouvelles” informations.
Dans les autres pays scandinaves, le besoin d'un système efficace est encore plus marqué car le volume d'informations qu'ils possèdent est de beaucoup plus important que celui du Danemark. C'est pourquoi la Norvège aussi bien que la Suède et la Finlande ont manifesté un vif intérêt pour le système danois et, au début de 1979, ont entrepris l'exécution d'un projet conjoint de recherche, portant sur la mise au point et la coordination des systèmes nordiques d'information AAF. Le système danois, décrit ci-après, sert de base aux activités de ce projet de recherche.
INFORMATION SUR L'AMELIORATION DES ARBRES FORESTIERS
Le système d'information est conçu pour traiter non seulement les données locales de l'Arboretum mais également les données d'un certain nombre de stations de recherche et même d'autres pays. Il peut en outre traiter des informations provenant de différents types de programmes d'amélioration (par exemple programmes de provenance, programmes d'amélioration des arbres et programmes de multiplication végétative).
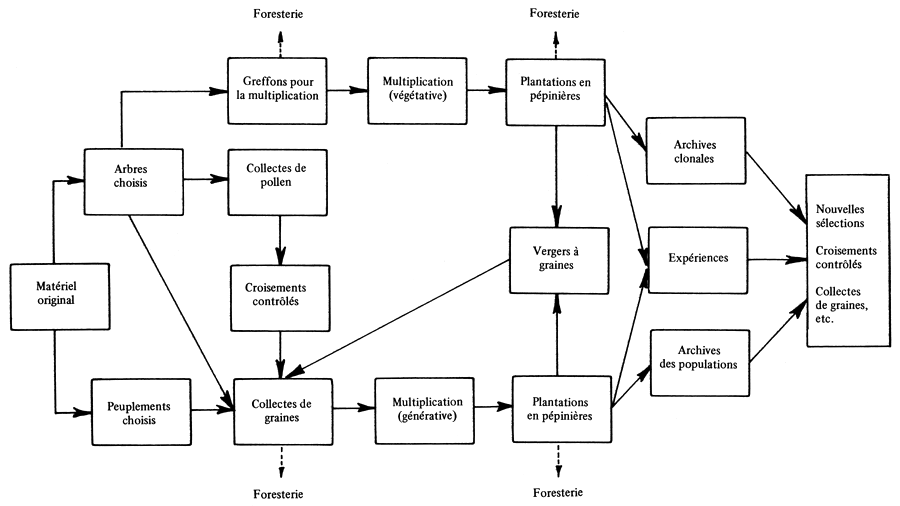
Figure 1. Données sur les principales activités que peut traiter le système d'information danois/scandinave sur l'amélioration des arbres forestiers.
La Figure 1 indique les informations que peut traiter le système tel qu'il est aujourd'hui. Les informations provenant de ce réseau d'activités peuvent être groupées comme suit:
Informations expérimentales. Les données provenant de divers tests et expériences font habituellement l'objet d'analyses statistiques appropriées. A l'Arboretum, ces dernières sont effectuées par un “Système d'analyses statistiques” séparé et seules les “données clés”, c'est-à-dire les résultats finals des analyses seront inclus dans le système d'information.
Descriptions générales de matériel de base et de matériel choisi (description de provenances et d'arbres plus, etc.).
Descriptions générales du matériel d'amélioration (pollen, graines, boutures et greffes).
Descriptions générales des emplacements utilisés pour les programmes d'amélioration (stations expérimentales, vergers à graines, archives clonales, lieux d'emmagasinage des graines ou du pollen).
Descriptions générales des différentes méthodes ou procédures utilisées dans les programmes d'amélioration (procédés d'entreposage des graines, méthodes de greffe, de bouture ou de semis, etc.).
Descriptions des degrés de parenté de différents individus ou groupes d'individus. Le système doit être capable de décrire la relation entre la descendance, les parents, les grands-parents, etc. et vice versa.
Descriptions des relations existant entre le matériel (individu ou groupe d'individus) et les emplacements: le système doit être en mesure, pour un matériel donné, de fournir une liste des emplacements où on peut le trouver, et pour un emplacement donné, de fournir une liste du matériel que l'on peut y trouver.
Descriptions des relations existant entre la date et les “activités” des programmes d'amélioration (date de la description d'un arbre plus, de la greffe d'un arbre plus, ou de l'évaluation d'une expérience).
On trouvera ci-dessous une brève description du système d'ordinateur en tant qu'“instrument” qui manipule l'information. Le diagramme de la Figure 2 illustre, dans ses grandes lignes, le fonctionnement du système. Ce dernier est décrit plus en détail, en danois, par Ditlevsen (1977) 1.
SAISIE DES DONNEES
Comme la collecte des données sera faite par des personnes différentes à des endroits différents et à des époques différentes, il est extrêmement important de disposer d'un guide donnant une description claire des informations à réunir.
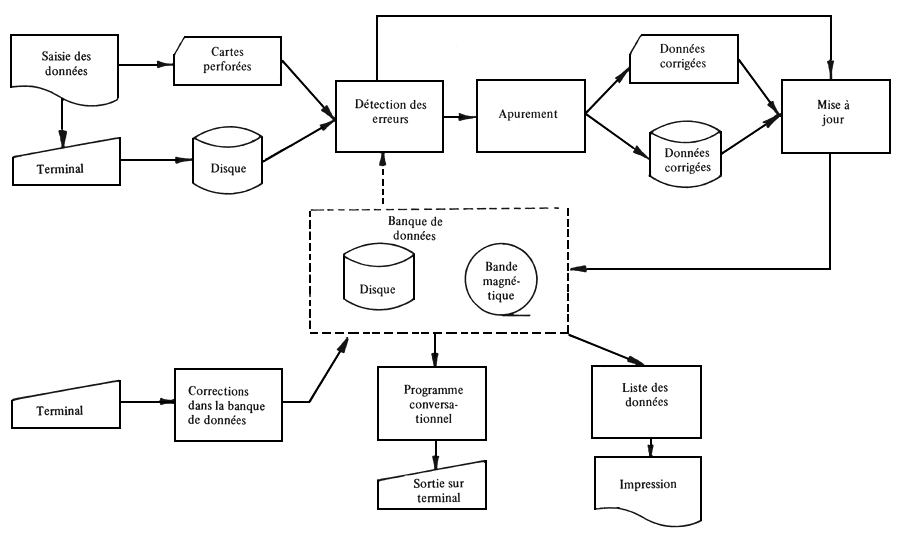
Figure 2. Diagramme indiquant le fonctionnement du système d'information sur l'amélioration des arbres forestiers.
A cet effet, un manuel de saisie a été mis au point. Il a deux objectifs principaux:
Il donne une définition et une description complètes de chaque élément des données qui peut être enregistré. Chaque description comporte:
l'identification des données;
la définition et la description du contenu des données;
la description du type des données (numérique, alphamérique ou alphanumérique) et la longueur du fichier;
la définition des codes au cas où l'information est codée.
Grâce au recueil complet que constitue ce manuel, la saisie de chaque élément de donnée sera faite correctement et de façon uniforme.
Les saisies sont effectuées sur 59 formats d'enregistrement différents, chacun d'eux étant identifié par un code registre (CR). Ce dernier est préimprimé dans les premières colonnes de chaque formats. Le code registre est toujours suivi d'un code d'entrée (code-matériel, code-emplacement, ou code-méthode) auquel se réfère l'information portée sur la partie restante du format d'enregistrement. La Figure 3 ci-après donne un modèle des formats d'enregistrement.

| Code-registre | Code-matériel | |
| Code-emplacement | ||
| ou | ||
| Code-méthode | ||
| 59 | V 1124 |
Figure 3. Illustration de la structure des formats d'enregistrement.
Dans chaque cas, le manuel indique le ou les formats à utiliser et donne en outre des instructions sur la façon de les remplir, ce qui permet d'utiliser les mêmes formats pour les mêmes cas et de les remplir correctement. Les formats utilisés pour l'enregistrement ont une longueur fixe de 80 caractères, correspondant à une carte perforée de 80 colonnes et, dans la mesure du possible, les éléments des données sur chaque format constituent une unité logique qui, normalement, sera enregistrée en même temps. Les formats d'enregistrement étant identiques aux registres de la banque des données (voir ci-dessous), le manuel donne également une description complète de la structure des données de la banque des données.
MISE A JOUR DE LA BANQUE DES DONNEES
Les données sont mises sur cartes perforées ou entrées directement sur un disque à partir du terminal de l'ordinateur.
Avant la mise à jour de la banque de données, ces dernières sont vérifiées, pour détecter les erreurs, à l'aide d'un programme spécial. Cette vérification est faite de deux façons:
Le programme vérifie tous les espaces de données sur les enregistrements pour détecter, par exemple, les codes invalides, les dépassements ou les données manquantes. Cette vérification n'est pas complète mais elle aide le chercheur à déceler les erreurs graves (codes invalides, valeurs manquantes, etc.); un contrôle plus détaillé devra être fait à la main.
Le programme aide le chercheur à vérifier les nouveaux codes d'entrée (code - matériel, code - emplacement; code - méthode; etc.) en les cherchant dans la banque de données pour savoir s'ils existent déjà et, dans ce cas, dans quel fichier on peut les trouver. Ce contrôle supplémentaire s'est révélé très efficace pour détecter les codes d'entrée erronés.
Les erreurs décelées par le programme d'apurement ou par un contrôle manuel sont, pour la plupart, corrigées sur les cartes perforées avant que la banque de données soit mise à jour, mais la mise au point d'un nouveau programme pour la correction des données dans la banque a rendu très facile et très rapide la correction des erreurs également après la mise à jour.
Les nouvelles données sont incorporées aux données existantes à l'aide d'un programme spécial de mise à jour.
Le contrôle des erreurs et la mise à jour décrits ci-dessus peuvent être effectués en même temps que les enregistrements dans l'espace des données, ce qui permet aux chercheurs de travailler indépendamment les uns des autres.
LA BANQUE DE DONNEES
Toutes les informations sont emmagasinées dans une banque de données, d'où l'on peut récupérer celles dont on a besoin.
Telle qu'elle apparaît aujourd'hui, la banque de données comprend sept fichiers principaux 1:
Le fichier UDV - qui contient des descriptions générales du matériel original (peuplement) et du matériel choisi (peuplement et arbres). Le matériel en question est identifié par un code-matériel.
Le fichier FORM - qui contient les descriptions générales du matériel d'amélioration (pollen, graines, boutures, greffes). Il comporte également des informations sur les méthodes d'amélioration utilisées (manipulation des semences, méthode de greffe ou de bouturage, etc.). Le matériel est identifié par un code-matériel.
Le fichier NGL - qui contient des “données clés” sur le matériel, c'est-à-dire les résultats finals de l'analyse statistique de données expérimentales (tests en laboratoire, en pépinières, expériences sur le terrain, etc.).
Le fichier ADM - qui donne une liste de tous les codes-matériel et des informations sur le degré de parenté et la multiplication. Ce dossier permet d'établir le pédigree complet de tout matériel contenu dans le système.
Le fichier LOK - qui contient des descriptions générales de tous les emplacements utilisés dans le programme AAF. Pour les stations expérimentales, il donne des informations sur l'agencement et les plans de mesure, etc. Chaque emplacement est identifié par un code-emplacement.
Le fichier DIST - qui contient des données sur les rapports matériel-emplacement, de sorte que pour tout matériel le fichier contient une liste des différents emplacements où l'on peut le trouver et, vice versa, pour tout emplacement le fichier contient une liste du matériel que l'on peut y trouver.
Le fichier MET - qui contient des descriptions de différentes méthodes utilisées dans les programmes d'amélioration des arbres forestiers, par exemple pour emmagasiner les graines ou le pollen, pour induire une floraison précoce, etc. Chaque méthode ou procédure est identifiée par un code-méthode.
Pour permettre l'utilisation efficace et souple de la banque de données, ces dernières sont mises en mémoire de deux façons:
Sur bandes magnétiques, où les enregistrements sont faits en ordre séquentiel, c'est-à-dire que les fichiers ne peuvent être traités que d'un bout à l'autre. Cette version est fréquemment utilisée pour obtenir des listes; en même temps que le traitement des données de la banque, on peut prélever des informations de la banque en accès direct (voir point B) et les incorporer à l'information dont on fait la liste, ce qui confère une grande souplesse à l'utilisation de l'information.
Sur disques en accès direct à chaque enregistrement. Comme on l'a déjà mentionné, les enregistrements sont identiques aux formats d'enregistrement (voir Figure 3). Les codes-matériel, codes-emplacement et les codes-méthode servent de codes d'accès aux différents fichiers.
Les fichiers de la banque de données sont entrés et référenciés comme suit: (voir aussi Figure 4).
Le fichier UDV est repéré par un code-matériel. Il comporte une référence croisée aux fichiers ADM, NGL et LOK.
Le fichier FORM est repéré par un code-matériel. Il comporte une référence croisée aux fichiers ADM, NGL, DIST, LOK et MET.
Le fichier NGL est repéré par un code-matériel. Il comporte une référence croisée aux fichiers ADM, FORM, UDV et DIST.
Le fichier ADM est repéré par un code-matériel. Il comporte une référence croisée aux fichiers FORM, UNDV, NGL et DIST. En outre, le fichier ADM conserve des codes-matériel comme variables de contrôle pour le matériel apparenté. Ces variables peuvent être utilisées pour réentrer le fichier ADM.
Le fichier LOK est repéré par un code-emplacement. Il comporte une référence croisée au fichier DIST.
Le dossier DIST est repéré soit par un code-matériel soit par un code-emplacement. Il comporte une référence croisée aux fichiers ADM, FORM, NGL et LOK.
Le fichier MET est repéré par un code-méthode, qui ne peut être utilisé pour l'entrée d'aucun autre fichier.
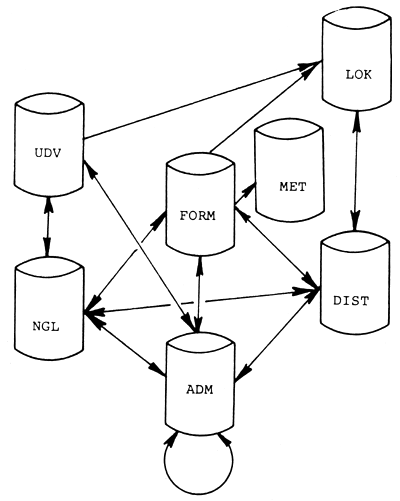
Figure 4. Illustration des liaisons entre les sept fichiers de la banque de données en accès direct.
Prenons un exemple pour illustrer les mouvements dans la banque de données:
Si l'on désire obtenir la description d'un arbre plus, ainsi qu'une liste de ses descendants et des différents emplacements où l'on peut trouver ces derniers, on pourrait procéder de la façon suivante: consulter le fichier UDV qui donne une description générale de l'arbre plus. De là, consulter le dossier ADM qui donne une liste des descendants et, pour chaque descendant trouvé dans le dossier ADM, consulter le fichier DIST pour retenir une liste des emplacements où se trouvent les descendants.
Comme on peut le constater, cette organisation de la banque de données permet une utilisation souple et efficace des informations mises en mémoire.
UTILISATION DU SYSTEME
Le système ayant été conçu pour être souple, et les données de plusieurs programmes d'amélioration des arbres forestiers pouvant être mis en mémoire dans la même banque, les possibilités d'utilisation du système sont nombreuses.
Pour illustrer quelques-unes de ces possibilités, on donne ci-après des exemples des trois principaux emplois du système:
Fourniture de listes à usage intérieur
Le rôle le plus important du système est de fournir différentes sortes de listes mises à jour. Ces dernières (listes de provenance, d'arbres plus, d'expériences de terrain, de vergers à graines, etc.) contiennent habituellement des informations utilisées par les chercheurs dans leurs activités quotidiennes. D'autres (listes de pollen ou de graines emmagasinées, listes récapitulatives de tous les travaux d'amélioration des arbres effectués dans une année donnée) sont fournies principalement à des fins administratives.
Fourniture de listes à usage extérieur
L'un des objectifs poursuivi lors de la création d'un système d'information sur ordinateur est de promouvoir l'échange de données entre chercheurs, pour faciliter la coordination et la coopération. Le type de listes mentionné au paragraphe précédent ne peut pas toujours être utilisé à l'extérieur, en raison surtout du langage employé, et des informations très détaillées qui donnent des listes trop volumineuses. En outre, les listes destinées à être utilisées à l'extérieur doivent généralement se conformer à certains critères, ou ensemble de critères spécifiques. A titre d'exemple, un sélectionneur suédois peut demander une liste des arbres plus danois d'un épicea norvégien, (origine Istebna) qui ont été choisis pour la forte densité de leur bois. Ces listes peuvent également être demandées par des Services gouvernementaux ou des organisations internationales comme la FAO ou l'IUFRO; elles devront alors de préférence être imprimées en anglais.
Demande de renseignements
Outre la possibilité d'obtenir des listes de différents types, il est essentiel de pouvoir disposer d'un système souple et efficace auquel on peut poser des questions.
Ce système peut répondre à des questions spécifiques de deux manières:
Grâce à un programme donnant des listes d'informations répondant à des critères spécifiques. Comme mentionné plus haut au paragraphe précédent, cette procédure est souvent utilisée pour satisfaire des demandes extérieures.
Grâce à un programme conversationnel au moyen duquel le chercheur peut “communiquer” directement avec la banque de données et ainsi poser des questions, obtenir des réponses, poser de nouvelles questions, etc.
Dans les deux cas, les questions peuvent être très complexes mais le programme conversationnel en particulier donne au chercheur des possibilités presque illimitées de formuler des questions et d'obtenir exactement les renseignements qu'il désire.
CONCLUSIONS
La mise au point du système brièvement décrit ci-dessus permettra de satisfaire les demandes des spécialistes de l'amélioration des arbres forestiers et, comme déjà mentionné, elle se fera à l'avenir dans le cadre d'un projet conjoint des pays scandinaves.
Bien qu'il soit avant tout destiné aux spécialistes de l'amélioration des arbres, on peut aisément l'utiliser pour traiter des données relatives à d'autres domaines connexes - conservation des ressources génétiques, enregistrement des arbres dans les Arboreta, les parcs, etc. Bien que les informations provenant de ces domaines connexes soient mélangées avec les données relatives à l'amélioration des arbres forestiers dans la banque de données, elles peuvent être traitées séparément, ce qui permet au chercheur n'utilisant qu'une partie du système de travailler indépendamment des praticiens de l'amélioration des arbres forestiers.
![]()
![]()
![]()