![]()
![]()
![]()
published by B. Krishnapillay and M. Marzalina in FGRI No. 21: 22–28 pp. (FAO 1993)
by
M. Hühn
University Kiel/Institute of Crop Science and Plant Breeding,
Olshausenstrasse 40, D-24118 Kiel, Germany
Please find below the comments by Dr. Hühn on the above article published in “Forest Genetic Resources Information” No. 21 (1993):
INTRODUCTION
To compute the sample size for moisture content determination, the authors of the article quoted above, published in FGRI No. 21 (1993) applied the well-known formulae for simple random sampling from elementary statistical theory:
n = t2S2 / d2 (for infinite population size) or
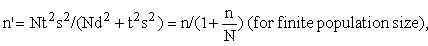
where n and n' = calculated sample size, d= maximum acceptable difference (error) between the sample and unknown population means, s = population standard deviation, N = population size and t = value from the t-distribution corresponding to confidence level (1-α) and (n-1) degrees of freedom.
Instead of t, the authors used the values from the standard normal distribution. These values can be applied if the population variance is known. In the field of practical applications, however, the most common situation will be the case of unknown variances which must be estimated from the data. Consequently, values from the t-distribution for confidence level (1-α) and (n-1) degrees of freedom must be substituted for t in the aforementioned formulae for n and n'. For large sample sizes, however, these t-values coincide with the values from the standard normal distribution. But, for small sample sizes the approach of using the standard normal distribution is not correct and it will yield underestimated sample sizes.
APPROACH
Some years ago, a rough and quite simple rule for correcting this underestimation has been developed by Rustagi (1983): The sample size for a required confidence level can be calculated using the value from the standard normal distribution and then adding a constant K which depends on the confidence level. The numerical values of these constants are (Rustagi 1983): K = 1.87 (for α = 0.90), K = 2.44 (for α = 0.95), K = 3.79 (for α = 0.99), and K = 5.63 (for α = 0.999). These computational rules are based on approximations. Their accuracy, however, seems to be sufficient for practical applications.
RESULTS
It is recommended that data from Table 3 in the quoted paper by Krishnapillay and Marzalina (1993) be replaced by the Revised Table 3, shown below. In this revised table, the approach outlined above has been applied to the results of Krishnapillay & Marzalina (normal distribution-based sample size + Rustagi-correction):
| Desired precision (%) | Probability | Standard deviation of seed moisture content | ||||||||
| 1.00 | 1.25 | 1.50 | 1.75 | 2.00 | 2.25 | 2.50 | 2.75 | 3.00 | ||
| Sample size (number of seeds) | ||||||||||
| 0.5 | 0.90 | 13 (11) | 19 (17) | 26 (24) | 35 (32) | 44 (42) | 55 (53) | 67 (65) | 80 (78) | 94 (92) |
| 0.95 | 18 (16) | 27 (25) | 37 (35) | 49 (47) | 62 (61) | 77 (77) | 93 (94) | 111 (112) | 130 (132) | |
| 0.99 | 30 (-) | 45 (-) | 62 (-) | 81 (-) | 103 (-) | 128 (-) | 154 (-) | 181 (-) | 210 (-) | |
| 0.999 | 48 (42) | 71 (64) | 98 (90) | 128 (121) | 161 (154) | 197 (189) | 235 (227) | 275 (267) | 316 (307) | |
| 1.0 | 0.90 | 5 (3) | 7 (4) | 8 (6) | 11 (8) | 13 (11) | 16 (14) | 19 (17) | 23 (20) | 26 (24) |
| 0.95 | 7 (4) | 9 (6) | 12 (9) | 15 (12) | 18 (16) | 22 (20) | 27 (25) | 31 (30) | 37 (35) | |
| 0.99 | 11 (-) | 15 (-) | 19 (-) | 24 (-) | 30 (-) | 37 (-) | 45 (-) | 53 (-) | 62 (-) | |
| 0.999 | 17 (11) | 23 (17) | 30 (24) | 39 (32) | 48 (42) | 59 (52) | 71 (64) | 84 (77) | 98 (90) | |
| 1.5 | 0.90 | 4 (1) | 4 (2) | 5 (3) | 6 (4) | 7 (5) | 8 (6) | 10 (7) | 11 (9) | 13 (11) |
| 0.95 | 5 (2) | 6 (3) | 7 (4) | 8 (5) | 10 (7) | 12 (9) | 14 (11) | 16 (13) | 18 (16) | |
| 0.99 | 7 (-) | 9 (-) | 11 (-) | 13 (-) | 16 (-) | 19 (-) | 22 (-) | 26 (-) | 30 (-) | |
| 0.999 | 11 (5) | 14 (7) | 17 (11) | 21 (14) | 25 (19) | 30 (24) | 36 (29) | 42 (35) | 48 (42) | |
| 2.0 | 0.90 | 3 (1) | 3 (1) | 4 (2) | 4 (2) | 5 (3) | 6 (3) | 7 (4) | 7 (5) | 8 (6) |
| 0.95 | 4 (1) | 4 (2) | 5 (2) | 6 (3) | 7 (4) | 8 (5) | 9 (6) | 10 (8) | 12 (9) | |
| 0.99 | 6 (-) | 7 (-) | 8 (-) | 9 (-) | 11 (-) | 13 (-) | 15 (-) | 17 (-) | 19 (-) | |
| 0.999 | 9 (3) | 10 (4) | 12 (6) | 14 (8) | 17 (11) | 20 (13) | 23 (17) | 26 (20) | 30 (24) | |
Revised Table 3. Adjusted values for the table determining the size of sample required for testing the moisture content of Shorea leprosula and S. parvifolia seeds at various levels of confidence and precision (based on a seed lot of 1500 seeds). Original values, as reported by Krishnapillay and Marzalina, are shown in brackets. For level 0.99 no values were originally calculated; these are marked with (-).
References
Krishnapillay, B. & Marzalina, M (1993). A statistical approach to determine sample size for moisture content determination in recalcitrant forest tree seeds (A case study using Shorea leprosula and S.parvifolia). Forest Genetic Resources Information No 21: 22–28
Rustagi, K.P. (1983). Determination of sample size in simple random sampling. Forest Science 29: 190–192.
RESPONSE FROM DR. KRISHNAPILLAY TO DR. HÜHN'S COMMENT1
“I received your valuable comments on the above paper that I published in FGRI no. 21 and wish to thank you. As you rightly pointed out, we in fact used the t-values from the standard normal distribution for our calculations. Based on your arguments, I fully agree that as the variance of the population is not known. Table 3 in our paper which is based on t-values from the standard normal distribution, is inappropriate and should be replaced with your modified table. I therefore, strongly recommend that your comments be published to rectify this error for the benefit of other interested readers. Thank you again for your valuable comments.”
Forest Genetic Resources no. 22 FAO, Rome (1994)
applied to the results of Krishnapillay & Marzalina (normal distribution-based sample size + Rustagi-correction):
![]()
![]()
![]()