Chapter 6 - Classification of available data and techniques of imputing missing data
Introduction
Planning for the compilation of SEAFA
Classification of basic data
Techniques for estimation of missing data
Commodity
flow approach
Some remarks on the use of statistical tools
6.1 The compilation of SEAFA, including its associated principal aggregates, presupposes an ideal situation in which the statistician is not only aware of all activities and transactions of the system but also that regular and comprehensive data on outputs, inputs, prices, taxes, subsidies, purchases of assets, inventories and uses of output are available on a continuing basis. This is however a situation that may never occur. In practice, not even the minimum desirable amount of data are always available for compilation of the main aggregates such as output and value added; partly because the collection of complete sets of data is a gigantic task and partly because of the costs involved. Whatever the situation, however, the compilation of SEAFA and its associated aggregates is a basic necessity for analysis, policymaking and planning. The job of the statistician is to make judicious use of the available information by manipulating it to obtain a picture of the economy. The purpose of this chapter is to list some of the general techniques used in different situations and also their underlying assumptions. It is necessary to point out the underlying assumptions so that users may be sure that conclusions drawn from the data are not simply dependent on assumptions. For example, if data on consumption of fixed capital are not available and it is assumed that this constitutes "x" percent of gross value added any statement comparing gross and net value added has no real significance.
Planning for the compilation of SEAFA
6.2 The framework, concepts and definitions of SEAFA have been explained in previous chapters. However, the compilation of SEAFA is not a routine arithmetical exercise where various sets of data are simply pooled together and presented in the framework. The compilation of SEAFA requires: careful examination of the various databases available; processing of these databases to achieve complete coverage in a logically consistent way; and pooling them together, keeping in view their reliability and gaps. Work on the compilation of SEAFA can be divided into broad four stages as listed below:
Stage One
Study the production process of the economy, keeping in view the appropriate activities listed in ISIC. List the principal agricultural products (crop and livestock), the system for providing agricultural services, agro-based industries, etc., the dependence of the economy and agricultural activity on imports and the amount of agricultural goods being exported.
Stage Two
Prepare a detailed list of various sources of data on output, the production or import of inputs and their utilization, items used as inputs for agro-based industries along with their sources of supply (i.e. domestic or imported), etc. that are required for the compilation of SEAFA. The list may also indicate the coverage and periodicity of these elements. While doing this exercise the statistician might also note that such a list could also indicate which of the three approaches, (viz. production, income and expenditure approach) can be used for the measurement of value added.
6.3 The production approach takes into account the production process. In this approach, value added is derived by deducting from the total value of output the goods and services purchased from other producer units and used as intermediate inputs in the production process. In the income approach, the cost structure of the producer unit is studied from financial data on income and expenditure. The sum of the compensation paid to employees and the operating surplus or mixed income (plus any taxes less subsidies payable on production) is taken as the measure of value added. In the expenditure approach the final use of output, i.e. output being used as final consumption (by the population, general government and non-profit institutions serving households), gross fixed capital formation, export and changes in inventory, less imports are recorded to measure value added or GDP. This last approach may not be appropriate for SEAFA and is normally used to prepare estimates for the economy as a whole.
Stage Three
A critical review of the listed data may be made to examine: reliability; areas for which no data are available; and areas for which more than one set of data are available.
6.4 For areas where more than one set of data are available, only one set of data, the more reliable, would be used to prepare estimates. It may be useful, however, to monitor the reliability of all sets continuously. For example, the output of some crops may be available from crop estimation surveys and from marketing boards dealing with trade of the crop concerned. In such cases depending on the coverage of the two data sources and the precision of the two sets of data, it may be decided to use only one of the sources to prepare the estimates, but the reliability of both sets of data should be compared every year.
6.5 Sometimes, the data may be such that the sector is divided into two sub-sectors and a different approach adopted for each of these sub-sectors. For example, for crop and animal husbandry, reliable data on output as well as intermediate consumption may be available through the production approach, but for the operation of irrigation systems, data may be available on income and expenditure, so that it is feasible to follow the income approach. Thus, the agriculture sector could be divided into two sub-sectors, one covering agricultural crop and livestock production and the other covering the operation of irrigation systems. However, in such a situation, payments made for using water from the irrigation system would have to be considered as intermediate consumption in crop and livestock production to avoid double counting.
Stage Four
Prepare the required breakdown of output, intermediate consumption, etc. using supplementary data and ad hoc studies and merge the data sets to get the final
SEAFA. The following discussion goes into details of the classification of basic data and explain techniques for imputing missing data.
6.6 The data for compilation of SEAFA are available either from statistical enquiries (census, survey or case-study) or as a by-product from administrative records. The data can be classified in two ways -- by their periodicity or by their purpose - and divided into three main groups according to the frequency with which they are collected, viz. regular (for each period), periodic (at fixed intervals e.g. every five or ten years) or ad hoc (i.e. only once in a while). The data can also be divided into three groups according to the purpose for which they have been collected, viz. primary (where data are collected directly for the purpose for which they are to be used through statistically designed censuses, surveys or case-studies), secondary (where data are collected for some other purpose but can also be used for the purpose under consideration) and tertiary (where the data are not directly relevant but, by making certain assumptions, can be used for the purpose under consideration). Taking the two criteria of periodicity and purpose together, sets of data that can be used to compile the SEAFA can be divided into nine groups as shown in Table 6.1.
6.7 In Table 6.1, as the cell identification number (calculated by numbering the rows consecutively from left to right and the columns from top to bottom and then multiplying the row number by the column number of the cell) increases from unity the reliability and representativeness of the estimate derived from the data in the cell decreases and progressively more care is required when using the data for the compilation of SEAFA. This implies that countries tend to have more reliable data for the compilation of SEAFA in the years in which they take censuses and similar surveys than in other years. Therefore one of the guiding principles for conducting censuses and surveys is that activities that change frequently and have a significant share in the total should be covered regularly in the scheme of data collection. Another important conclusion to be drawn from the table is that the reliability of the estimate of an aggregate could be worked out by classifying the basic data in the above groups and combining them according to the contribution they make to the calculation of the aggregate. Using this method it can be stated that a particular share of the data used to prepare the estimate is available directly and regularly and so a specified share of the estimate is based on direct data. Sometimes it is also possible to give margins of error for data that falls under different headings thus allowing the margin of error in the 'estimate' to be calculated using the share of such data in the total value. For example, let us say that 80 percent of the estimate of the value of output is based on (1,1)-type data with an error of +/- 5 percent, 15 percent comes from (2,1)-type data where the error is +/- 10 percent and the remaining 5 percent belongs to the (2,3)-type with an error of +/- 15 percent. Thus the combined margin of error in total value of output would be: 6.25
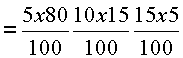 percent
percent
Table 6.1 Classification of Data
| TYPE OF PURPOSE | ||||
| PRIMARY | SECONDARY | TERTIARY. | ||
| P E R I O D I C I T Y |
R E G U L A R |
Direct data on crop Production, producer's prices | Yield on cost structure of a crop from neighbouring areas | Price data of Machinery and equipment (general) applied to agricultural machinery |
| P E R I O D I C |
Agricultural or Livestock census | Cost of production study done at regular intervals for one rop used on other crop | Consumer expenditure surveys to estimate final expenditure on agricultural products | |
| A D H O C |
Census/survey of age of fixed assets used in agriculture purchases of agricultural | Tabulation of government purchases to find out allocate draught animal goods by government | Use of result of transport survey to between agricultural and non-agricultural sector | |
Techniques for estimation of missing data
6.8 Once the basic data has been classified one of the following four alternative types of situation generally arises:
· Type A situations occur when direct data are available on a regular basis according to the period for which estimates are required. Examples of this type include data on the production and prices of major crops.
· Type B situations include cases where direct data are available at different points of time or at a single point. In such cases techniques of interpolation or extrapolation may be applied.
· Type C situations occur when only partial data are available on a regular basis. In such cases, imputations have to be made for the remaining data.
· Type D situations occur when no data are available and the whole item needs to be estimated.
6.9 The compilation of aggregates or items of SEAFA in the last three types of situation require special care and methods. In a Type B situation detailed benchmark estimates are generally prepared for the year(s) for which data are available. The benchmark estimates are extrapolated to other years until data for another point of time become available. While extrapolating the benchmark estimate, it should be disaggregated into its different components when these are known to have different growth patterns. For example, values are disaggregated into their quantity and price components. Livestock are disaggregated by type, sex, age and variety (indigenous or improved). The different components of the estimates are extrapolated independently and checked against new data for another point of time when those become available. If necessary, data for previous years are revised after getting new data for the next point of time.
6.10 There are two ways of extrapolating benchmark estimates. The first, and preferred, technique is to use information (data) on some other variable that is highly correlated with the variable under consideration. In this method, the true movements (i.e. ups and downs) can be seen in the projected time series. However, needless to say, it is necessary to have direct evidence on the correlation between the two series. When fresh data for any other point of time become available, a critical analysis should be undertaken to explain the difference between the projected and actual estimates. For example, to project the price of machinery and equipment used in the agricultural sector, general wholesale, retail or import prices, of machinery and equipment can be used, depending on the local situation and availability of data. However, when new data for the projected time point become available and a significant difference is observed between the actual and projected prices, it is necessary to determine the reason for this. It may be caused by any of the following factors: the general price level of machinery and equipment might have been influenced by some special type of machinery that was not included before; the agricultural machinery industry itself might have changed with the arrival of a new factory or new type of machinery; and/or a substantial inflow of machinery from abroad might have influenced the market. In such cases, it would be necessary to identify the year when the change has occurred, to correct the independent variable and to revise estimates for previous years. However, such a situation would not occur if the system is constantly reviewed and data on those items that are sensitive for the compilation of SEAFA are collected regularly.
6.11 The second approach is either to fit a trend line to the data (assuming that the data are available for more than one point of time) or to express the variable as a ratio of another variable to which it is known to have a direct relation and for which regular data are available. Numbers of livestock from livestock censuses are an example where the trend line approach is applicable. An example of the second approach occurs when the quantity of seed can be expressed as a ratio to the area sown under the crop. In such cases it is also necessary to establish that the two series are directly related. For example, in estimating the value of seed through area under the crop it is necessary to see that the relationship is expressed in constant prices or in quantity terms rather than in current values. The derived series will have to be adjusted independently for changes in the price level.
6.12 In a Type C situation where partial data are available, it is necessary to compute the component for which information is not available. Consider, for example, the estimation of production of a crop that is either new or relatively unimportant for the area and so is not covered in the scheme of crop cutting experiments. However, data on the area under crop are available from sources such as land records, crop insurance records and government extension schemes. In such a case, it is necessary to impute the crop yield to get an estimate of the production. There are usually two choices available; to impute either the yield of the crop from data for neighbouring areas, keeping in view the seed variety and agro-climatic conditions or the yield of some other crop which is similar to the crop under consideration and grown in the same area is taken as the imputed value of yield. Examples of the latter type of situation arises when area is available for 'other coarse cereals' or 'other fruits and vegetables' that are not explicitly recognized. In such cases, either the yield of a known crop, which is a close substitute, or the weighted or simple avenge of the yield of a group of crops is taken.
6.13 The Type D situation, where no direct data are available, presents a real challenge for the statisticians' ability to impute the value of a missing observation. The following factors may be borne in mind: what is the practice in other countries in the same part of the world where the situation is the same? if relevant data are available, what method and database were used in the past either to prepare estimates for this particular item or in macroeconomic or economic studies of such aggregates? what is the likely size of the activity? and what cross-checks are available to test the reliability of the imputation? For example, if no estimate of own consumption of agricultural goods is available, the estimate for the benchmark year could be made by multiplying the per caput consumption norm from a survey covering the rural areas by the total population dependent on agriculture. The benchmark estimate can be extrapolated to other years on the basis of total annual output and growth of the population. However, allowance would have to be made for relative movements of the prices of different commodities that enter into the consumption basket, changes in consumption habits (if the series is sufficiently long) etc. A consistency check with total population, size of the population that is not dependent on agriculture, domestic production, imports and exports, etc. would have to be repeated every year until direct data become available.
6.14 The kind of manipulation of available information described above is a necessary evil for any exercise in which official statistics are used to compile a secondary database such as SEAFA. At the same time, it must be remembered that the application of checks of the type discussed above do not guarantee the accuracy of any particular estimate but can only ensure that a relatively consistent picture is provided by the set of data as a whole. Checks of the type discussed above (own account consumption) are based on total utilization of the goods produced. Accuracy of the estimate depends on the imagined picture created and the contents of the data available. No statistician should hesitate to use such techniques when necessary, but constant monitoring is required.
6.15 The commodity flow approach was developed in the 1930s to prepare estimates of private consumption expenditure but is also widely used to prepare estimates of fixed capital formation. The logic of the approach is based on calculating the total availability of each good or service (or group of goods or services) by adding domestic output, imports and opening inventories and subtracting closing inventories to obtain the goods and services that are available for intermediate and final uses. The net availability calculated in this manner is further adjusted for trade and transport margins and taxes or subsidies on products to arrive at values at purchasers' prices. The goods and services available are allocated to different uses in the form of government purchases, gross fixed capital formation, exports and intermediate consumption. The balance of goods and services remaining, after adjusting for wastage, would be available for final household consumption. A similar procedure can followed to prepare estimates of gross fixed capital formation.
Some remarks on the use of statistical tools
6.16 As already mentioned, the use of statistical tools such as averaging and ratio or regression techniques is unavoidable while processing the data. However, some judgement and caution are required while using these techniques to obtain SEAFA aggregates from official statistics. Some of the more important points are mentioned below for ready reference.
(a) Average: Averaging of primary data is essential in order to present the main features of the data. The use of either simple or weighted averages is prevalent and the decision as to whether to use one or the other does not depend entirely on the availability of data. The homogeneity of the data is one of the important criteria used to decide whether a simple or weighted average of a given data set should be taken. Before processing the data it is necessary to analyze the sources of variation in the observations. Variation may be caused by either the geographical conditions prevailing in the area where the data are being collected or by other factors, e.g., the intervention of external economic forces such as changes in the quantum of import or export, varietal differences, consumer preferences and season. The next question that requires examination is whether the volume of the activity that is effected by the variation is the same or evenly distributed over the total period. If not, it is necessary to give due weight by stratifying the sources from which the data emerge and estimating their shares. Even if no quantitative character is readily available, it is necessary to impute a weight (i.e. to give more weight to places that cover larger volumes) to represent the true situation. Consider the example of a good (fruit or vegetable) that is sold throughout the year but that has high prices during its off-season of about ten months. A simple average to represent the annual price level of the good would give an equal weight to all the prices throughout the year. In actual practice more than 60 percent of the output may be sold in the first two months, higher prices in successive months being caused by storage charges, wastage in storage and trade margins. Thus, in the succeeding months the observations do not represent only the "pure" good but "the good" plus "some services". Even if consumer or purchasers' prices are being estimated, equal weighting of the prices recorded in different months is not justified. If weights representing sales in different months are not available, they may be imputed on the basis of the consumer population belonging either to different income or consumption classes or living in different agglomerations, e.g. city, town, village, rural or urban areas.
6.17 Another important aspect of averaging relates to the treatment of missing observations. Missing observations play a vital role in time series. If proper estimates of missing observations are not made before averaging the data, the average may present a completely false picture. Consider the example of a price or wage series where data are regularly collected from 100 sites (say). At a particular point it is noted that returns from only 80 out of the 100 sites have arrived by the date when results have to be presented. In such a situation, a simple average of the available observations if taken as representing the level in the current year vis-à-vis last year's level may present a misleading picture. The statistician has two alternatives to estimate the true situation. The first alternative selects those sites for which returns are available for both years, calculates the average growth rate for these sites and applies this growth to the overall level reported for the previous year. In this case, the growth rate in the selected sites is assumed to be the same as that for the excluded sites. The second alternative requires that the statistician be aware of the local conditions of the total population (universe), in which case the missing observations can be estimated with the help of available data for each of the 20 sites averaged out. In this case, the variation in the individual site has been taken into account. However, whichever alternative is used the calculated average should be revised after more data are received.
6.18 In either of the two situations (i.e. choice of weights or estimation of missing observations) a better judgement can be made if the coefficient of variation of the cross-sectional data is calculated.
(b) Ratio or regression techniques: Ratio or regression techniques may be used to extrapolate data. Obviously a choice has to be made between the two methods when data are available in the form of a time series. The situation can be illustrated with the help of an example. Consider the time series of goat and cattle meat prices that are available for a country or region for a long period although data for one of the series are not available for the latest year. In such a case, either the ratio or the regression method can be used to estimate the missing observation(s). When the ratio method is chosen the implicit assumption is that the rate of inflation for 'goat' and 'cattle' meat in the period with missing data is the same as for the last year in which the ratio has been worked out. On the other hand, if the regression technique is chosen the fitted regression equation would also take into account the differential rate (trend) of inflation. Another possibility in such a situation is to include some other explanatory variable, such as animal imports, in the regression equation in order to improve the estimate. Use of these methods depends on the length of the series (since at least 12 degrees of freedom are necessary to estimate the error component), the time available to prepare the estimate and the availability of explanatory data.