![]()
![]()
![]()
Simultanément à l'analyse descriptive des informations ou des données cliniques ou épidémiologiques, il a été préconisé de construire des modèles mathématiques pour faciliter le développement d'une relation dose-réponse, en particulier lorsqu'il est nécessaire d'extrapoler à de faibles doses. Les modèles mathématiques sont utilisés depuis plusieurs décennies en toxicologie. Dans le domaine de la microbiologie des aliments et de l'eau, il est désormais admis que les modèles mathématiques peuvent faciliter l'évaluation de la relation dose-réponse, et fournir des informations utiles tout rendant compte de la variabilité et de l'incertitude. Les hypothèses sur lesquelles se fondent les modèles actuels, leur utilisation et leurs éventuelles limitations sont passées au crible dans les sections qui suivent.
Ces sections sont centrées sur les pathogènes infectieux et toxi-infectieux, car c'est dans ce domaine que les progrès ont été les plus grands. D'autres pathogènes sont examinés de façon plus superficielle en fin de chapitre.
Le fondement biologique des modèles dose-réponse dérive des principales étapes du processus morbide, qui sont la résultante des interactions entre le pathogène, l'hôte et la matrice. La figure 4 illustre les principales étapes de l'ensemble du processus, chacune d'elles étant composée de nombreux événements biologiques. L'infection et la maladie résultent en quelle que sorte du passage réussi du pathogène à travers les multiples barrières de l'hôte. Ces barrières ne sont pas toutes aussi efficaces pour éliminer ou inactiver des pathogènes et elles peuvent avoir divers effets, suivant le pathogène et l'individu. Chaque pathogène spécifique a une probabilité particulière de franchir une barrière, qui est conditionnée par la réussite de la (des) étapes(s) antérieure(s). Le processus morbide pris dans son ensemble, mais aussi chacune des étapes qui le composent peuvent varier selon le pathogène et l'hôte. Les pathogènes et les hôtes peuvent être regroupés par rapport à une ou plusieurs composantes, à condition de procéder avec prudence et dans la transparence.
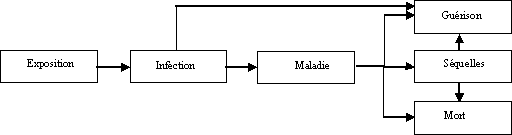
Figure 4. Les principales étapes du processus d'une maladie infectieuse d'origine alimentaire.
Un modèle dose-réponse décrit la probabilité d'une réponse donnée dérivant d'une exposition à un pathogène donné dans une population donnée, en fonction de la dose. Cette fonction est basée sur des données empiriques et ordinairement donnée sous la forme d'une relation mathématique. Le recours à des modèles mathématiques s'impose pour plusieurs raisons:
Les profils d'ensembles de données empiriques concernant la réponse d'un groupe d'individus exposés à la dose (souvent exprimée sous forme logarithmique) ont souvent une forme sigmoïde, et peuvent être ajustés par un grand nombre de fonctions mathématiques. Toutefois, lorsque l'on extrapole en dehors de la région des données observées, ces modèles peuvent prédire des résultats radicalement différents (cf. Coleman et Marks, 1998; Holcomb et al., 1999), d'où la nécessité de faire une sélection entre les nombreuses fonctions dose-réponse possibles. Lorsque l'on se prépare à établir un modèle dose-réponse, les aspects biologiques de l'interaction pathogène-hôte-matrice doivent être examinés avec attention. Les fonctions du modèle dérivées de ces informations théoriques seront ensuite traitées comme des informations à priori. Pour plus de détails, voir la Section 6.2.
En général, les modèles dose-réponse concernant des pathogènes microbiens qui sont plausibles sur le plan biologique doivent tenir compte de la nature discrète (ou particulaire) des organismes et être fondés sur le concept de l'infection provenant d'un ou plusieurs « survivants » à une dose initiale. Avant de poursuivre, il nous faut cependant étudier avec attention le concept de « dose ».
La concentration des pathogènes dans l'inoculum est généralement analysée à l'aide d'une méthode microbiologique, biochimique, chimique ou physique quelconque. En principe, ces méthodes devraient avoir une sensibilité et une spécificité de 100 pour cent par rapport à l'organisme cible, mais c'est rarement le cas. Il peut donc être nécessaire de corriger la concentration mesurée pour que la sensibilité et la spécificité de la méthode de mesure donnent une estimation réaliste du nombre d'agents infectieux viables. Le résultat peut être plus grand ou plus petit que la concentration mesurée. Notons qu'en général, les méthodes de mesure employées pour caractériser l'inoculum dans un ensemble de données utilisé pour la modélisation dose-réponse diffèrent de celles qui servent à caractériser l'exposition dans un modèle d'évaluation des risques. Il doit être tenu compte de ces différences dans l'évaluation des risques.
En multipliant la concentration de pathogènes dans l'inoculum par le volume ingéré, il est possible de calculer le nombre moyen de pathogènes ingérés par un grand groupe d'individus. Le nombre réel ingéré par tout individu exposé n'est pas égal à cette moyenne, mais est un nombre variable qui peut être caractérisé par une distribution de probabilité. On suppose habituellement que les pathogènes sont distribués au hasard dans l'inoculum, mais il en est rarement ainsi. Une distribution composée (ou sur-dispersion) peut résulter de deux mécanismes distincts:
On a généralement recours à une distribution de Poisson pour caractériser la variabilité des doses individuelles lorsque les pathogènes sont répartis au hasard. Les micro-organismes tendent à s'agréger dans des suspensions aqueuses. En pareil cas, le nombre d'unités comptées n'est pas égal au nombre de particules infectieuses, mais au nombre d'agrégats contenant une ou plusieurs particules infectieuses. Il est alors important de savoir si les agrégats demeurent intacts durant la préparation de l'inoculum ou dans le tube digestif. Les différents niveaux d'agrégation dans les échantillons expérimentaux et dans l'eau ou dans les denrées réels doivent aussi être pris en compte.
Dans la dose ingérée, chaque organisme individuel est censé avoir une probabilité distincte de survivre à toutes les barrières pour atteindre un site cible où former des colonies. La relation entre le nombre effectif d'organismes survivants (dose efficace) et la probabilité de colonisation de l'hôte est un concept clé pour la dérivation de modèles dose-réponse, comme on le verra plus loin.
Selon la définition la plus commune, une infection est une situation dans laquelle le pathogène, après avoir été ingéré et avoir survécu à toutes les barrières, croît activement sur son site cible (Last, 1995). Une infection peut être mesurée par diverses méthodes, telles que l'excrétion fécale ou la réponse immunologique. Les taux d'infection apparents peuvent différer des taux d'infection réels, suivant la sensibilité et la spécificité des méthodes diagnostiques. Habituellement, la mesure d'une infection consiste seulement à détecter sa présence ou son absence, en fonction d'un critère déterminé. L'utilisation de variables de réponse continue (par exemple, titre d'anticorps) peut être utile pour affiner les modèles de dose-réponse. Les infections peuvent être asymptomatiques, lorsque l'hôte ne développe aucune réaction adverse à l'infection et élimine le pathogène en peu de temps, mais elles peuvent aussi déboucher sur une maladie symptomatique.
Les pathogènes microbiens ont des facteurs de virulence très divers et peuvent déclencher un large spectre de réponses néfastes, qui peuvent être aiguës, chroniques ou intermittentes. En général, les symptômes peuvent résulter soit de l'action de toxines, soit de dégâts aux tissus hôtes. Les toxines peuvent s'être formées antérieurement dans la matrice alimentaire ou hydrique (« intoxication ») ou être produites in vivo par des micro-organismes dans l'intestin (« toxi-infection »), et agissent en fonction de différents mécanismes pathogéniques (Granum, Tomas et Alouf, 1995). L'endommagement des tissus peut aussi résulter de mécanismes très divers, dont la destruction des cellules hôtes, l'envahissement et les réactions inflammatoires. Pour de nombreux pathogènes d'origine alimentaire, la séquence pathogénique précise des événements n'est pas connue et elle est probablement complexe. On notera que les risques sanitaires liés à la présence de toxines dans l'eau (par exemple de toxines cyanobactériennes) sont généralement liés à des expositions répétées et requièrent une autre approche, similaire à la caractérisation des dangers liés aux produits chimiques.
En gros, on peut dire que la maladie est un processus d'accumulation de dégâts chez l'hôte qui conduit à des réactions adverses. De nombreux signes et symptômes de maladie différents apparaissent en général simultanément chez un individu, et la sévérité des symptômes varie suivant les pathogènes et suivant les hôtes infectés par un même pathogène. La maladie est donc un processus qui se mesure au mieux à une échelle multidimensionnelle, quantitative et continue (nombre de selles évacuées par jour, température corporelle, examens en laboratoire, etc.). En revanche, dans les études d'évaluation des risques, la maladie est ordinairement interprétée comme une réponse « tout ou rien » (présence ou absence de maladie), de sorte que les résultats dépendent très largement de la définition de cas. Or on trouve dans la littérature des définition de cas très diverses pour les maladies gastro-intestinales, établies sur la base d'une liste de symptômes variable, avec ou sans échelle de temps déterminée, et incluant parfois une confirmation en laboratoire des agents étiologiques. Ce manque d'uniformisation est un gros handicap pour intégrer des données provenant de différentes sources.
Une petite fraction des malades peut développer une infection chronique ou des séquelles. Certains pathogènes, comme le sérotype Typhi de Salmonella enterica sont invasifs et peuvent causer des bactériémies et des infections généralisées. D'autres produisent des toxines qui peuvent entraîner non seulement une entéropathie, mais aussi de graves dégâts dans des organes vulnérables. À titre d'exemple, on peut citer le syndrome hémolytique-urémique, dû à la détérioration des reins par des shiga-toxines de certaines souches d'Escherichia coli. Des complications peuvent aussi découler de réactions d'origine immunologique: la réaction immunitaire au pathogène est alors également dirigée contre les tissus hôtes. L'arthrite réactionnelle (y compris le syndrome de Reiter) et le syndrome de Guillain-Barré sont des exemples bien connus de ces maladies. Les complications de la gastro-entérite requièrent normalement un traitement médical et aboutissent souvent à l'hospitalisation du patient. Le risque de mortalité lié aux séquelles peut être important et certains patients ne se rétablissent pas complètement et souffrent de séquelles pendant toute leur vie. C'est pourquoi, bien que la probabilité que des complications surviennent soit faible, les conséquences peuvent être lourdes du point de vue de la santé publique. Il y a également un risque direct de mortalité par maladie aiguë, en particulier chez les personnes âgées, les nouveaux-nés et les sujets fortement immunodéprimés.
Plusieurs concepts clés doivent être étudiés pour formuler des modèles dose-réponse biologiquement plausibles. Ces concepts concernent:
Nous allons maintenant examiner chacun de ces concepts par rapport aux différents stades de l'infection et du processus morbide. En principe, les modèles dose-réponse devraient représenter les séries d'événements conditionnels ci-après: probabilité d'infection résultant d'une exposition; probabilité de maladie aiguë résultant d'une infection; et probabilité de séquelles ou de mortalité résultant d'une maladie aiguë.
Dans la pratique les concepts et les données nécessaires ne sont cependant pas encore au point pour suivre cette approche. C'est pourquoi nous allons également examiner des modèles qui quantifient directement la probabilité de maladie ou de mortalité résultant d'une exposition.
Selon l'interprétation traditionnelle des informations sur la relation dose-réponse, il existerait un seuil en pathogènes qu'il faudrait ingérer pour que le microorganisme provoque une infection ou une maladie. On dit qu'il existe un seuil si aucun effet ne se produit en deçà d'un certain niveau d'exposition, mais si au-dessus de ce niveau, il est certain que l'effet se produit. D'une manière générale, les efforts déployés pour définir la valeur numérique de ces seuils dans les populations étudiées n'ont pas abouti, bien que ce concept soit largement documenté dans la littérature, sous le nom de « dose infectieuse minimale ».
Une autre hypothèse postule que, étant donné que les micro-organismes ont la capacité de se multiplier à l'intérieur de l'hôte, une infection peut résulter de la survie d'un seul organisme pathogène infectieux, viable (« concept du choc unique »). Cela signifie que, même si la dose est faible, il y a toujours, au moins au sens mathématique, une probabilité d'infection et de maladie, vraisemblablement très petite, mais différente de zéro. Bien entendu, cette probabilité augmente avec la dose.
On notera que l'existence ou l'absence de seuil, tant au niveau de l'individu que de la population, ne peut pas être démontrée de manière expérimentale. En effet, les données expérimentales sont toujours soumises à un seuil d'observation (la limite de détection expérimentale), en ce sens qu'une réponse infiniment petite ne peut pas être observée. La question de savoir s'il existe réellement une dose infectieuse minimale ou si elle résulte simplement des limitations des données est donc purement théorique. La solution pratique consiste à ajuster les modèles de dose-réponse sans seuil (sans discontinuité mathématique), mais suffisamment flexibles pour permettre une forte courbure à de faibles doses, de manière à mimer une dose-réponse de type seuil.
La probabilité de maladie résultant d'une infection dépend de l'ampleur des dégâts dans l'organisme hôte aboutissant au développement de symptômes cliniques. En ce qui concerne ces mécanismes, on peut raisonnablement supposer que les pathogènes qui se sont développés in vivo doivent dépasser un nombre minimal donné. Une relation non linéaire peut être appliquée car l'interaction entre les pathogènes peut dépendre de leur nombre in vivo et il faut des nombres élevés en germes pour activer les gènes de la virulence (effets du quorum-sensing dépendant de la densité). Ce concept est cependant différent de celui de seuil concernant une dose administrée, car il existe une possibilité, aussi petite soit-elle, qu'un seul organisme ingéré parvienne à survivre aux multiples barrières dans l'intestin pour s'établir et se reproduire.
L'hypothèse de l'action indépendante postule que la probabilité moyenne p par pathogène inoculé de causer (ou de contribuer à causer) une infection (symptomatique ou létale) est indépendante du nombre de pathogènes inoculés et que, chez un hôte partiellement résistant, elle est inférieure à un. A l'opposé, les hypothèses de synergie maximale et partielle postulent que les pathogènes inoculés combinent leur action de sorte que la valeur de p augmente avec la taille de la dose (Meynell et Stocker, 1957). Plusieurs études expérimentales ont tenté de vérifier ces hypothèses et les résultats ont d'une manière générale plutôt confirmé celle de l'action indépendante (pour une synthèse, voir Rubin, 1987).
Le quorum sensing est un nouveau domaine de recherche qui présente de toute évidence un grand intérêt pour la virulence de certaines bactéries. L'idée est que certaines caractéristiques phénotypiques, comme les gènes spécifiques de virulence, ne s'expriment pas de façon constitutive, mais sont dépendantes de la densité cellulaire, et utilisent diverses petites molécules pour envoyer des signaux de cellule à cellule, et que ces caractéristiques ne s'expriment que quand la population bactérienne a atteint une certaine densité (De Kievit et Iglewski, 2000). Alors que les aspects biologiques du quorum sensing et de la réponse sont encore à l'étude, la nature de l'impact est claire, à savoir que certains facteurs de virulence ne s'expriment que quand la population bactérienne a atteint une certaine taille. Le rôle du Quorum sensing aux premiers stades du processus infectieux n'a pas fait l'objet d'une étude approfondie, et aucune conclusion ne peut être tirée sur la signification du quorum sensing par rapport à l'hypothèse de l'action indépendante. En particulier, le rôle de la communication entre les espèces ou entre les spécimens d'une même espèce est important. Sperandio et al., (1999) ont démontré que la colonisation intestinale par des E. coli entéropathogènespouvaitêtre induite par un quorum sensing de signaux produits par des E. coli non pathogènes de la flore intestinale normale.
Les propriétés spécifiques des données ne deviennent significatives que dans le contexte d'un modèle. Des modèles différents peuvent cependant conduire à des interprétations différentes d'une même donnée, de sorte que le choix d'un modèle doit être rationnellement justifié. Différents critères peuvent être appliqués lorsque l'on sélectionne des modèles mathématiques. Pour qu'un modèle soit acceptable, il doit satisfaire aux critères statistiques de la qualité de l'ajustement. Cependant plusieurs modèles différents s'ajustent ordinairement à un ensemble de données déterminé (par exemple, voir Holcomb et al., 1999) si bien que la validité de l'ajustement n'est pas un critère suffisant pour le choix d'un modèle. D'autres critères comme la prudence et la flexibilité pourraient être retenus.
La prudence peut être analysée de différentes manières: « La structure du modèle est-elle prudente? » « Les estimations des paramètres sont-elles prudentes? » « Les propriétés spécifiques du modèle sont-elles prudentes », ainsi de suite. Il n'est pas recommandé d'intégrer la prudence dans la structure même du modèle. Dans l'optique d'une évaluation des risques, un modèle devrait se limiter à décrire les données et à tenter de distinguer le signal biologique du bruit. L'adjonction de paramètres améliore habituellement la qualité de l'ajustement d'un modèle, mais l'utilisation d'un modèle flexible à paramètres multiples peut accroître l'incertitude des estimations, en particulier pour les doses extrapolées. Les modèles flexibles et les ensembles de données insuffisants peuvent conduire à une surestimation de l'incertitude, alors qu'un modèle fondé sur des hypothèses solides peut être trop restrictif et conduire à une sous-estimation de l'incertitude dans les estimations du risque.
Il est conseillé d'élaborer les modèles de dose-réponse sur la base d'une série d'hypothèses mécanistes biologiquement plausibles, puis d'effectuer une analyse statistique avec les modèles qui sont considérés comme plausibles. On notera qu'il est généralement impossible de « procéder à l'envers », c'est-à-dire de déduire les hypothèses qui sous-tendent la formule d'un modèle donné. Un problème d'identifiabilité se pose: la même forme fonctionnelle peut résulter d'hypothèses différentes, alors que deux ou plusieurs formes fonctionnelles différentes (basées sur des hypothèses diverses) peuvent décrire aussi bien les unes que les autres les mêmes données de dose-réponse. Ceci peut se traduire par des courbes d'ajustement très différentes si les données contiennent peu d'informations, ou par des courbes pratiquement identiques si les données contiennent des informations solides. Toutefois, même dans ce dernier cas, l'extrapolation d'un modèle peut être très différente, de sorte que le choix entre divers modèles ou hypothèses ne peut pas être fait uniquement sur la base des données.
Les considérations qui précèdent nous amènent à poser l'hypothèse suivante: pour des pathogènes microbiens, les modèles dose-infection basés sur les concepts du choc unique et de l'action indépendante sont considérés comme les plus plausibles et les plus défendables sur le plan scientifique. Sachant qu'en outre les pathogènes ont une nature « discrète », ces concepts nous conduisent à une famille de modèles, dits du choc unique (voir encadré 1).
Les modèles du choc unique sont une série spécifique de modèles rentrant dans la catégorie plus large des modèles mécanistes. Haas, Rose et Gerba (1999) décrivent des modèles qui supposent l'existence de seuils – constants ou variables – pour l'infection, à savoir qu'il faut un nombre minimum d'organismes survivants, supérieur à un, pour que l'infection se produise. Des modèles empiriques (ou de distribution de tolérance), tels que les modèles log-logistic, log-probit et Weibull(-Gamma), ont également été proposés pour la modélisation de la relation dose-réponse. L'utilisation de ces autres types de modèles est souvent motivée par un argument intuitif, à savoir que les modèles du choc unique surestiment les risques à de faibles doses.
Jusqu'à présent, les modèles infection-maladie n'ont guère retenu l'attention et les données disponibles sont extrêmement limitées. Des observations expérimentales montrent que la probabilité d'une maladie aiguë parmi les sujets infectés peut augmenter avec la dose ingérée, mais une diminution a aussi été notée (Teunis, Nagelkerke et Haas, 1999) et les données permettent rarement de tirer des conclusions sur la dépendance à l'égard de la dose, en raison du petit nombre de cas étudiés. Dans ces circonstances, les modèles de probabilité constante (c'est-à-dire indépendante de la dose ingérée), si possible stratifiés par sous-groupes de la population ayant des sensibilités différentes, semblent une hypothèse raisonnable par défaut. Outre la dose ingérée, les modèles de maladie devraient prendre en compte les informations disponibles sur les périodes d'incubation, la durée de la maladie et le moment de la réponse immunitaire, et ils devraient dans la mesure du possible évaluer la maladie comme un concept multidimensionnel, sur des échelles continues. Il n'y a pas encore de fondement pour modéliser la probabilité de maladie en fonction du nombre des pathogènes qui se sont développés chez l'hôte.
L'hypothèse par défaut de modèles de probabilité constante de maladie résultant d'une infection permet de conclure que la seule différence entre les modèles dose-infection et les modèles dose-maladie est que les seconds n'ont pas besoin d'atteindre une asymptote de 1, mais de P(mal/inf). Ils appartiendraient encore essentiellement à la famille des modèles basés sur la théorie du choc.
Pour une maladie donnée, la probabilité de séquelles et /ou de mortalité dépend bien entendu des caractéristiques du pathogène, mais plus encore de celles de l'hôte. Les séquelles ou la mortalité sont en principe des événements rares qui affectent des sous-populations spécifiques. Celles-ci peuvent être identifiées par des facteurs comme l'âge ou l'état immunitaire mais le rôle des facteurs génétiques est de plus en plus reconnu comme déterminant. Comme ci-dessus, les modèles de probabilité constante sont pratiquement les seuls à être applicables, dans les circonstances actuelles. Une stratification paraît nécessaire dans presque tous les cas où il existe une description acceptable des classements en groupes de risque.
Les informations sur la relation dose-réponse sont généralement obtenues dans la fourchette où la probabilité de résultats observables est relativement élevée. Dans les études expérimentales sur des sujets humains ou animaux, ceci s'explique par des restrictions d'ordre financier, éthique et logistique sur la taille des groupes. Dans des études d'observation, comme les études épidémiologiques, les effets de faibles doses peuvent être observés directement, mais seuls les effets importants peuvent être distingués d'une variationdu bruit de fond. Comme les modèles d'évaluation des risques comprennent souvent des scénarios avec des expositions à de faibles doses, il est généralement nécessaire d'extrapoler au-delà de la gamme des données observées. Les modèles mathématiques sont des outils indispensables pour ces extrapolations et de nombreuses formes fonctionnelles différentes ont été appliquées. Le choix des modèles sera dicté en premier lieu par des considérations biologiques, et en second lieu seulement par les données disponibles et leur qualité. Les hypothèses de travail de l'absence de seuil et de l'action indépendante conduisent à une famille de modèles qui est caractérisée par des extrapolations linéaires vers les faibles doses sur une échelle log/log, ou même à l'échelle arithmétique. Cela signifie que, dans la gamme des faibles doses, la probabilité d'infection ou de maladie augmente de façon linéaire avec la dose. A l'échelle logarithmique, ces modèles ont une pente de 1 à de faibles doses. Parmi les exemples, on peut citer:
Encadré 1. Modèles basés sur la théorie du choc unique Supposons qu'un hôte ingère exactement une cellule d'un micro-organisme pathogène. Selon l'hypothèse du choc unique, la probabilité que ce pathogène survive à toutes les barrières et colonise l'hôte a une valeur pm différente de 0. Ainsi, la probabilité que l'hôte ne soit pas infecté est de 1-pm. Si une seconde cellule du pathogène est ingérée et si l'hypothèse de l'action indépendante est valable, la probabilité que l'hôte ne soit pas infecté est de (1-pm)2. Pour un nombre n de pathogènes, la probabilité de non infection est (1-pm)n. La probabilité d'infection d'un hôte qui ingère exactement n pathogènes peut donc être exprimée par l'équation:
À partir de cette fonction de base, il est possible de dériver une famille élargie de modèles de dose-réponse (modèles basés sur la théorie du choc). Les modèles les plus fréquemment utilisés sont le modèle exponentiel et le modèle béta-poisson, qui se fondent sur de nouvelles hypothèses concernant la distribution des pathogènes dans l'inoculum, ainsi que sur la valeur de pm. Lorsque la distribution des organismes dans l'inoculum est supposée aléatoire et caractérisée par une distribution de Poisson, on peut constater (voir Teunis et Havelaar, 2000) que la probabilité d'infection en fonction de la dose est donnée par la formule:
où D est la dose moyenne ingérée. Si pm est censé avoir une valeur constante r pour un hôte et pour un pathogènes donné quels qu'ils soient, le modèle exponentiel simple donne:
Si
si la probabilité de contracter une infection diffère selon les organismes présents dans les hôtes et est supposée suivre une distribution bêta, on a:
For
When Pour
D'autres assomptions concernant n ou p conduisent à d'autres modèles. Par exemple, l'agrégation de cellules dans l'inoculum peut être représentée par une distribution binomiale négative ou par tout autre distribution contagieuse. Toutefois, cela n'a guère d'effet sur la forme de la relation dose-réponse (Haas, Rose et Gerba, 1999) bien que la courbe limitante relative à l'intervalle de confiance soit affectée (Teunis et Havelaar, 2000). Il est également possible de modéliser pm en fonction de co-variables, telles que l'état immunitaire ou l'âge. |
où D = dose ingérée moyenne et r, α et β sont les paramètres des modèles. On note que si α > β, le risque d'infection prédit par le modèle Bêta-Poisson est supérieur au risque d'ingestion, ce qui n'est pas plausible sur le plan biologique. D'où la nécessité d'étudier avec attention s'il convient d'utiliser ce modèle simplifié pour analyser des données de dose-réponse.
Les ensembles de données expérimentales sont généralement obtenus dans des conditions rigoureusement contrôlées et les données s'appliquent à une combinaison spécifique du pathogène, de l'hôte et de la matrice. Or dans les conditions d'exposition réelles, chacun de ces facteurs a une variabilité plus grande et les modèles de dose-réponse doivent être généralisés. Pour évaluer cette variabilité, il faut utiliser des ensembles de données multiples qui captent la diversité des populations humaines, des souches de pathogènes et des matrices. La non-prise en compte de ces variations peut conduire à une sous-estimation de l'incertitude réelle des risques.
Lorsque l'on élabore des modèles de dose-réponse à partir d'ensembles de données multiples, il convient d'utiliser toutes les données pertinentes. Il n'existe actuellement aucun moyen de déterminer quelle est la meilleure source de données. L'évaluateur des risques doit donc faire des choix. Ces choix seront dans la mesure du possible fondés sur des arguments scientifiques objectifs, avec toutefois inévitablement une composante de subjectivité. Ces arguments seront discutés avec le gestionnaire des risques et leur signification et leur impact pour la gestion des risques seront examinés. La crédibilité des modèles de dose-réponse augmente considérablement si les relations dose-réponse dérivées des différentes sources de données sont cohérentes, surtout si les types de données sont variés.
Lorsque l'on combine des données provenant de différentes sources, une échelle commune sur les deux axes est nécessaire. Cela suppose souvent d'ajuster les données reportées pour les rendre comparables. Pour la dose, on tiendra compte de la sensibilité du test, de la spécificité du test, de la taille de l'échantillon, etc. Pour la réponse, une définition de cas cohérente est nécessaire; à défaut, la réponse reportée doit être ajustée à un dénominateur commun (par exemple infection x probabilité conditionnelle de maladie résultant d'une infection). La combinaison de données provenant de différentes sources dans un modèle de dose-réponse unique (multiniveau) exige des compétences statistiques approfondies et une connaissance détaillée des processus biologiques qui ont généré les données. Ceci est illustré par le modèle dose-réponse multiniveaux qui a été élaboré pour différents isolats de Cryptosporidum parvum (Teunis et al., 2002a). Le problème de la combinaison des données issues de différentes études épidémiologiques est examiné dans les évaluations FAO/OMS des risques de salmonellose dans les poulets de chair et dans les œufs (FAO/OMS, 2002a).
Lorsqu'un agent pathogène n'affecte qu'une partie de la population, il peut être nécessaire de séparer les sous-populations de la population générale afin d'obtenir des résultats significatifs pour la relation dose-réponse. Pour utiliser ces modèles de dose-réponse stratifiés dans des études d'évaluation des risques réels, il faut pouvoir estimer le pourcentage de la population effectivement sensible. L'étude de ces sous-populations est particulièrement importante pour l'établissement de relations dose-réponse en cas d'infections grave ou de mortalité. Toutefois, elle est également utile pour étudier un agent susceptible de n'infecter qu'une partie de la population.
Une analyse stratifiée peut aussi être utile lorsque l'on a affaire à des résultats en apparence aberrants, qui peuvent indiquer une sous-population avec une réponse différente. Le retrait d'une ou plusieurs valeurs aberrantes revient à supprimer (ou à analyser séparément) tout le groupe qui est à l'origine des résultats aberrants. Si l'on ne parvient pas à identifier une raison particulière pour la séparation, on aura probablement un biais en tenant compte de telles données. Toute élimination de données sera communiquée de façon claire pour garantir la transparence de l'évaluation.
Le développement d'une immunité spécifique chez l'hôte est une particularité extrêmement intéressante des modèles de dose-réponse microbiologique. La plupart des expériences sur des volontaires ont été conduites sur des sujets sélectionnés en raison de leur absence de tout contact antérieur avec le pathogène, ordinairement démontrée par l'absence d'anticorps spécifiques. Dans la réalité, la population exposée aux pathogènes d'origine alimentaire et hydrique est généralement un mélange de personnes qui n'ont jamais été en contact avec le pathogène et de personnes protégées à des degrés divers par une immunité. Aucune généralisation ne peut être faite sur l'impact de ces facteurs, car il dépend fortement du pathogène et de la population hôte. Certains pathogènes, comme de nombreuses maladies infantiles et le virus de l'hépatite A, confèrent une immunité permanente dès la première infection, qu'elle soit clinique ou subclinique, alors que l'immunité conférée par d'autres pathogènes peut disparaître en quelques mois ou en quelques années ou être évitée par dérive antigénique. Parallèlement, l'exposition à des souches non pathogènes peut aussi conférer une protection contre des variants virulents. Ce principe est à la base de la vaccination, mais il a aussi été démontré pour l'exposition naturelle, par exemple à des souches non pathogènes de Listeria monocytogenes (Notermans et al., 1998). Le degré auquel la population est protégée par une immunité dépend dans une large mesure des conditions d'hygiène générales. Dans de nombreux pays en développement, de larges segments de la population ont développé des niveaux d'immunité élevés, ce qui explique probablement la plus faible incidence de la maladie ou ses formes moins graves. La forme essentiellement aqueuse de la diarrhée due aux infections par Campylobacter spp. chez les enfants, et l'absence de maladie due à cet organisme chez les jeunes adultes dans les pays en développement illustrent bien ce phénomène. L'absence apparente de maladie liée à E.coli 0157:H7 au Mexique a été expliquée comme résultant d'une immunité croisée après des infections par d'autres E.coli, comme les souchesd'E.coli entéropathogènes qui sont répandues dans ce pays. A l'inverse, dans le monde industrialisé, le contact avec des entéropathogènes est moins fréquent et une plus grande partie de la population est sensible. L'âge est bien entendu un facteur important à cet égard.
L'intégration de l'effet de l'immunité dans les modèles de dose-réponse n'a jusqu'à présent guère retenu l'attention. Or, le fait de ne pas en tenir compte dans les modèles peut compliquer les interprétations ainsi que les comparaisons entre les endroits. Ceci pourrait en particulier poser un problème avec des infections communes comme Campylobacter spp., Salmonella spp. et E. coli. L'immunité peut avoir une incidence sur la probabilité d'infection, la probabilité de maladie résultant d'une infection ou la sévérité de la maladie. Actuellement, on dispose de peu de données pour construire des modèles. Lorsque ces données sont disponibles, l'approche consistant à recourir à une analyse stratifiée et à diviser la population en groupes de sensibilités différentes (voir par exemple FDA/USDA/CDC, 2001) est une option simple, qui peut être efficace. Récemment, une étude expérimentale sur l'infection de volontaires caractérisés par différents niveaux d'immunité acquise à Cryptosporidium parvum a été analysée avec un modèle de dose-réponse incluant les effets de l'immunité (Teunis et al., 2002b).
Avant tout, comme pour d'autres aspects du processus d'évaluation des risques, les procédures d'ajustement des modèles doivent être expliquées de façon claire, pour garantir la transparence et la reproductibilité des modèles.
Les méthodes basées sur la vraisemblance sont préférables. L'approche adoptée dépend des types de
données disponibles et de la variation stochastique présumée présente. Par
exemple, pour des données binaires, l'ajustement du modèle se fait à l'aide de
la fonction de vraisemblance binomiale appropriée. Pour une fonction
dose-réponse 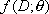 avec un vecteur paramètre
avec un vecteur paramètre 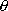 , la fonction de vraisemblance d'une série d'observations
est:
, la fonction de vraisemblance d'une série d'observations
est:
![]()
où le produit est absorbé par tous les groupes de dose, à raison d'un indice i. Pour une dose Di, un nombre ni de sujets est exposé, et ki sont infectés. L'ajustement consiste à trouver les valeurs de paramètre qui maximisent cette fonction, d'où l'expression : valeurs de paramètre présentant le maximum de vraisemblance. L'optimisation peut être très délicate, car de nombreux modèles dose-réponse sont essentiellement non linéaires. La plupart des logiciels mathématiques techniques, comme Matlab, Mathematica ou Gauss, ou des logiciels statistiques, comme SAS, Splus ou R, fournissent des procédures d'optimisation non linéaire.
Haas (1983) et Haas, Rose et Gerba (1999) donnent des informations techniques spécifiques sur les méthodes d'ajustement des modèles de dose-réponse. Tous les manuels de statistiques mathématiques notamment celui de Hogg et Craig (1994) en donnent un aperçu général. McCullagh et Nelder (1989) est la source qui fait autorité pour les méthodes statistiques associées, et de nombreux modèles de dose-réponse peuvent être formulés comme des modèles linéaires généralisés (sauf le modèle exact du choc unique - voir Teunis et Havelaar, 2000). Vose (2000) est une source précieuse pour avoir une description générale des méthodes mathématiques et statistiques employées dans le domaine de l'évaluation des risques.
Lorsque la fonction de vraisemblance d'un modèle est disponible, le modèle peut être vérifié en calculant des rapports de vraisemblance. La validité de l'ajustement peut être évaluée par rapport à un maximum de vraisemblance, c'est-à-dire à un modèle avec autant de degrés de liberté que de données (groupes de dose). Par exemple, pour des réponses binaires, un maximum de vraisemblance peut être calculé en insérant les rapports entre les réponses positives et le nombre de sujets exposés dans la vraisemblance binomiale (McCullagh et Nelder, 1989):
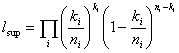
La déviance (-2 × la différence en log-vraisemblance) peut être approchée en tant que variable aléatoire chi-carré, avec des degrés de liberté égaux aux nombres de groupes de dose, moins le nombre de paramètres du modèle.
La même méthode peut être employée pour le classement des modèles. Pour comparer deux modèles, on commence par calculer les vraisemblances maximales pour les deux modèles, puis on détermine la déviance (-2 × la différence en log-vraisemblance). Cette déviance peut à présent être vérifiée par rapport au chi-carré avec des degrés de liberté égaux à la différence du nombre des paramètres des deux modèles, au seuil de signification souhaité (Hogg et Craig, 1994).
L'approximation chi-carré est asymptotiquement correcte pour de grands échantillons. En outre, le test du rapport des vraisemblances n'est valable que pour des modèles qui sont hiérarchiquement emboîtés, ce qui signifie que le modèle le plus général peut être converti en modèle le moins général, en manipulant les paramètres. La complexité des modèles peut être surmontée en remplaçant le rapport de vraisemblance par un critère d'information, comme celui d'Akaikes (AIC). Ceci réduit le nombre de paramètres, pour trouver un équilibre entre la validité de l'ajustement et la parcimonie des paramètres (nombre minimum de paramètres nécessaire).
D'une manière générale, les méthodes bayésiennes ont une validité plus grande car elles permettent la comparaison entre tous les types de modèles, même non hiérarchisés. La validité de l'ajustement peut être comparée avec des facteurs de Bayes, et il existe aussi un critère d'information correspondant, appelé Critère d'information bayésien (BIC) (Carlin et Louis, 1996).
Il est indispensable de déterminer l'incertitude des paramètres. Plusieurs catégories de méthodes peuvent être appliquées, notamment:
La majorité des analyses dose-réponse liées à des micro-organismes pathogènes ont jusqu'à présent uniquement pris en considération les réponses binaires (infecté/non infecté; malade/non malade). Étant donné que, dans un tel contexte, chaque groupe de dose peut contenir un mélange de réponses, il est impossible d'analyser l'hétérogénéité caractérisant la réponse (distinction de l'incertitude et de la variation). Les modèles d'infection établis en fonction de la quantité de pathogènes excrétés, ou de l'élévation d'une ou plusieurs variables immunitaires, ou d'une combinaison de ces deux paramètres, offrent de meilleures possibilités d'analyser l'hétérogénéité au sein de la population hôte et de la population pathogène, ainsi que leur distinction.
![]()
![]()
![]()
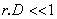 , cette formule est approximée par:
, cette formule est approximée par: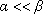 and
and 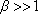 , la fonction hypergéométrique confluente
de Kummer
, la fonction hypergéométrique confluente
de Kummer 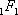 est approximativement égale à la formule bêta-poisson:
est approximativement égale à la formule bêta-poisson: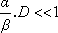 , cette formule est approximée par
, cette formule est approximée par 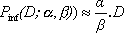 .
. comme pour
comme pour  , alors que
, alors que 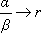 , la formule bêta-Poisson est équivalente
au modèle exponentiel.
, la formule bêta-Poisson est équivalente
au modèle exponentiel.