![]()
![]()
![]()
| RWA/87/012-Aide-mémoire No135 | RWA/87/012/TRAM/135 |
par
P. MANNINI et M. LAMBOEUF
DOSSIERS:
DP 9/10
MINAGRI
RR/PNUD
FAOR
Rijavec, FIO
West, RAFR
Everett, DIPA
Greboval, IFID
Chrono
Diary: Mannini
| PNUD/FAO-RWA/87/012 | février, 1991 |
La quantité importante de données biologiques recueillies dans le cadre de l'activité du projet, nécessite une organisation et un archivage sur support informatique de telle sorte que ces données soient facilement accessibles a tous moments et pour divers types d'analyse.
Les données de base se présentent sous forme de feuilles de saisie en exemplaire unique qui risquent facilement se mélanger ou de s'égarer. Ces données ainsi recueillies ne sont que du matériel non traité et non archivé de manière pratique et rationnelle, c'est dans le but d'éviter la perte de cette information qu'un système d'archivage informatisé a été mis au point.
Les noms commerciaux des programmes et logiciels cités dans ce document et utilisés dans le projet pour le traitement des données, n'engagent en aucune manière la responsabilité des auteurs et de l'Organisation des Nations Unies pour l'Alimentation et l'Agriculture.
2.1 Généralités
Il est possible de schématiser le flux de données de leur récolte jusqu'à leur élaboration et analyse. Les données sont à la base de tout système d'archivage et leur récolte est le premier élément dans un processus de recherche, il en constitue une étape fondamentale. Ces données doivent être représentatives de la population échantillonnée. La qualité des résultats de l'analyse dépendront de celle des données et de leur représentativité. Les sources de biais sont d'origines diverses et on doit toujours s'efforcer de minimiser leurs effets.
L'organigramme de la FIGURE 1 résume la structure et le flux des données archivées depuis leur saisie jusqu'aux programmes d'application.
Les informations recueillies sur des bordereaux de saisie et classés selon un critère approprié, constituent déjà un système d'archives mais qui manque de flexibilité et dont l'utilisation est lente.
Dans le cas des données archivées au projet, les éléments d'information recueillis à partir de chaque poisson sont les suivants: longueur à la fourche, poids du corps, sexe et maturité sexuelle. Les données sont ensuite transposées dans deux types de fichier informatique, l'un au format des programmes ELEFAN et LFSA et l'autre de dBase III.
Dans le premier cas, les éléments saisis correspondent à toutes les mesures de longueur regroupées en classes de taille. Les fichiers résultants sont ordonnés selon la date et le lieu de l'échantillonnage, ils constituent le point de départ des méthodes de gestion des stocks basées sur les distributions de fréquences de taille. ELEFAN et LFSA comprennent des sous-programmes qui utilisent ces fichiers pour l'application d'un certain nombre de modèles bio-mathématiques.
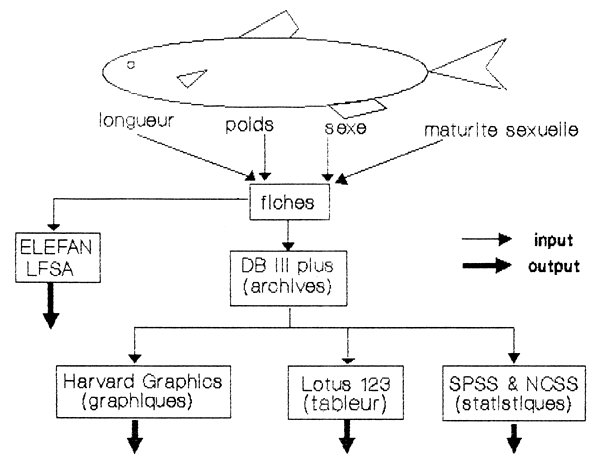
FIGURE 1 Collecte et traitement des données: flux de l'information
Les fichiers destinés à l'utilisation des programmes ELEFAN et LFSA ne comprennent que des données de longueur. Dans les fichiers dBase III, en plus des informations précédentes, sont aussi stockées d'autres informations comme le poids, le sexe et la maturité sexuelle. Ils sont un outil idéal pour la manipulation de grandes quantités d'informations. Ils sont en pratique la transposition informatisée du document source mais présentent l'avantage de permettre manipulations, tri, réorganisation, etc…
Les fichiers ainsi crées peuvent être facilement protégés et reproduits. Les données peuvent être transférées au format d'autres programmes d'application: statistiques modèles d'application, traitement de texte, graphiques, etc…
2.2 Les programmes ELEFAN et LFSA
LFSA “Length Frequency Stock Assessment” et ELEFAN “Electronic Length Frequency Analysis” sont deux programmes développés indépendamment pour répondre à des besoins semblables, c'est pourquoi ils présentent des similitudes dans les options proposées. Sans vouloir entrer dans le détail il est bon cependant de souligner que les méthodes de calcul utilisées sont différentes d'un programme à l'autre tout en tendant vers un même but. Il s'agit de logiciels spécialisées à l'usage des biologistes des pêches et permettant à partir de données d'échantillonnages de fréquences de tailles de déterminer un certain nombre de paramètres de l'espèce et de la pêcherie considérée (croissance, mortalité naturelle et par pêche, sélectivité des engins de pêche, analyse de population virtuelle, etc.).
Ces logiciels ont pour avantage principal de faciliter la tâche des biologistes en réduisant considérablement le temps nécessaire au traitement de la masse de données élémentaires généralement très importante, ils permettent aussi d'aller plus loin dans des analyses qui seraient pratiquement inconcevables à la main.
Il faut cependant insister sur le fait que ces deux logiciels ne peuvent être utilisés de façon fiable que par des utilisateurs ayant une bonne compréhension de la théorie de l'échantillonnage et des méthodes d'analyse que ces programmes utilisent.
2.3 La base de données dBase III +
L'expression “gestion d'une base de donnée” indique bien qu'il s'agit d'un système permettant d'archiver et de classer des quantités importantes d'informations ayant à son centre un ensemble contenant toutes ces informations, groupées en enregistrements contenant plusieurs éléments d'informations liés ensemble comme indiqué en exemple au TABLEAU 1.
| DATE | LONGUEUR | POIDS | SEXE | MATURITE |
| 16/01/90 | 62 | 3.41 | M | 3 |
| 16/01/90 | 101 | 10.25 | F | 5 |
| 16/01/90 | 94 | 9.01 | F | 4 |
| 16/01/90 | 82 | 7.18 | F | 5 |
| 24/01/90 | 66 | 2.90 | M | 2 |
| 24/01/90 | 74 | 4.34 | M | 5 |
TABLEAU 1 Exemple de données stockées dans la base de données
L'ordinateur n'apporte pas d'élément nouveau à la gestion d'une base de données mais il en facilite les manipulations et rend son utilisation plus rapide et plus performante.
2.4 Le logiciel Harvard Graphics
Il s'agit d'un logiciel de présentation graphique présentant de larges possibilités de présentation de données brutes et de résultats. La présentation graphique des phénomènes biologiques ou de la dynamique d'un pêcherie facilite grandement la compréhension des phénomènes en synthétisant visuellement leur évolution. Harvard Graphics est dans ce sens un outil performant qui permet à partir des résultats d'autres logiciels de traitement, d'intégrer directement les données pour les présenter.
2.5 Les programmes NCSS et SPSS
“Number Cruncher Statistical System” et “Statistical Package for Social Sciences” sont des logiciels statistiques intégrés très performants. Ils présentent toutes les possibilités d'analyse statistiques normales et non paramétriques qui sont fréquemment utilisées dans le traitement des données biologique et des pêcheries. Comme précédemment indiqué il est indispensable pour en faire une bonne utilisation, de connaître le théorie statistique et de respecter les conditions d'application des tests et la représentativité des données à traiter.
2.6 Le système HADAS
Le système HADAS “Hydro Acoustic Data Acquisition System” est un ensemble qui comporte une interface à processeur très rapide permettant à partir d'enregistrements sur cassette magnétique de numériser les échos des poissons, complétée par un programme de traitement qui à partir de ces informations numérisées permet l'analyse de la densité de poissons en nombre et sa répartition par tranches de profondeur et par classes de taille.
2.7 Le tableur LOTUS
Il suffit de rappeler ici que les tableurs du type de LOTUS sont des logiciels qui permettent le traitement de données nécessitant des quantités de calculs importantes. Ce programme n'est pas limité à un type de données ou d'analyse sa seule limitation est celle de la capacité de l'utilisateur à configurer le programme et à obtenir ce qu'il en attend.
Dans le cadre de notre projet ce logiciel est utilisé pour diverses applications nécessitant des calcuts importants, on citera en particulier:
l'analyse des données des prospections acoustiques fournies par le système HADAS ci-dessus, qui permet de déterminer la biomasse du stock d'Isambaza du lac kivu par régions profondeur et classes de taille; et
le traitement des données de “KTVUSTAT”, un système d'évaluation des captures réelles dans le lac Kivu basé sur l'analyse et l'extrapolation des données à partir d'un nombre restreint de points d'échantillonnages répartis autour du lac.
Il est difficile ici de décrire simplement les résultats obtenus à partir de l'utilisation du système ci-dessus, car il sont très divers et illimités. Ces résultats font l'objet de nombreuses publications et analyses publiées dans le cadre du projet et il n'est pas l'objet de ce document de les reprendre.
On se contentera ici d'analyser les bénéfices que le projet tire de l'utilisation de ce système et de voir quelles en sont les limitations éventuelles.
Le TABLEAU 2 schématise le domaine d'application des différents logiciels utilisés.
| LOGICIELS | dBase III | ELEFAN LFSA | Harvard Graphics | Lotus 123 | SPSS NCSS |
| Gestion de données | A | B | |||
| tableur | A | ||||
| graphiques | B | A | B | B | |
| statistiques | B | A | |||
| applications biomathématiques | A |
(A) Caractère spécifique
(B) Possibilité limitée
TABLEAU 2 Logiciels utilisés et domaines d'application
La disponibilité d'archives informatisées peut être considéré comme le premier résultat qui permettra d'améliorer les performances des futures activités de recherche
ELEFAN et LFSA permettent de déterminer à partir des données de longueur des poissons les paramètres fondamentaux de la population, c'est à dire, les paramètres de l'équation de croissance de Von Bertalanffy, la relation taille-poids, les estimations de la mortalité totale, le schéma de recrutement, les rendements et la biomasse par recrues et l'analyse de population virtuelle.
Les fichiers dBase III + transférés sur LOTUS ou sur Harvard Graphics ou encore sur SPSS ou NCSS permettront la visualisation graphique des phénomènes biologiques, comme par exemple l'évolution de la maturité sexuelle ou la répartition des sexes.
SPSS et NCSS apportent la possibilité lorsque cela est nécessaire, d'analyser les données sur le plan statistique: régressions, statistiques descriptives, analyse de variance, statistiques non-paramétriques.
Lorsque l'analyse est terminée, il est toujours possible de la reprendre avec d'autres hypothèses ou après avoir ajouté des données nouvelles.
Enfin, les résultats peuvent facilement être transférés dans un programme de traitement de texte pour la publication finale
La principale limitation que l'on pourrait trouver à ce système est la nécessité de la part des utilisateurs de bien connaître les logiciels et leur utilisation et aussi de bien comprendre les méthodes d'analyse et de traitement qui sont impliquées. La formation et la pratique régulière sont la condition pour une bonne utilisation.
Il est aussi très important de veiller à la fiabilité et à la représentativité des données qui sont utilisées pour s'assurer d'obtenir des résultats exacts.
![]()
![]()
![]()