


En recherche forestière, un certain nombre de cas sont étudiés à l’aide d’applications statistiques autres que les plans ou techniques classiques d’analyse ou d’échantillonnage. Ces méthodes particulières sont entièrement subordonnées aux concepts afférents aux disciplines considérées de sorte que, pour bien comprendre toutes leurs implications, il est indispensable d’avoir une bonne maîtrise des statistiques et des disciplines en jeu. Quelques-uns de ces cas particuliers seront brièvement examinés dans ce chapitre. On notera que chacun des cas décrits ci-dessous a été assez largement développés et que cette section ne représente qu’un ensemble de base. Nous invitons nos lecteurs à se reporter, le cas échéant, à d’autres ouvrages, pour mieux comprendre les variations possibles, aussi bien dans la structure des données que dans la forme d’analyse.
6.1. La génétique et l’amélioration des plantes
6.1.1. Estimation de l’héritabilité et du gain génétique
Les variations observées dans un groupe d’individus comprennent une part de variation génétique, ou héréditaire, et une part de variation non héréditaire. La fraction héréditaire de la variation totale est appelée coefficient d’héritabilité au sens large. La variance génotypique peut elle-même être subdivisée en variance génétique additive et non additive. Le rapport de la variance génétique additive à la variance phénotypique totale est appelé coefficient d’héritabilité au sens strict et est désigné par h2. On a donc,
![]()
Le gain génétique ou amélioration génétique par génération peut être défini comme l’augmentation de la productivité dérivant d’un changement de la fréquence génique dû le plus souvent à la sélection.
L’héritabilité et le gain génétique peuvent être évalués par deux méthodes, au choix. L’estimation la plus directe est dérivée de la relation entre les parents et leur descendance, et s’obtient en mesurant les parents, en cultivant leurs descendants et en les mesurant. L’autre méthode consiste à examiner la descendance de familles pleinement ou à demi apparentées, de faire une analyse de la variance et de calculer l’héritabilité comme fonction des variances. Dans ce contexte, il est indispensable de posséder une connaissance approfondie des statistiques pour comprendre la partie théorique. Les formules que l’on trouvera plus loin dans cette section ne sont données qu’à titre de référence. De plus, nous avons volontairement renoncé à couvrir les multiples variations qui pourraient résulter d’irrégularités dans le plan. Nous illustrerons ce qui précède à l’aide d’un testage de la descendance de familles à demi apparentées, qui est le plus utilisé dans le secteur forestier en raison de sa simplicité.
Les estimations de l’héritabilité et du gain génétique s’appliquent exclusivement aux expériences à partir desquelles elles ont été obtenues. Il suffit parfois d’en modifier un léger détail pour obtenir des résultats tout à fait différents. Il est donc recommandé, lorsque l’on décrit les expériences, d’accompagner le plan expérimental et les procédures de calcul des détails et des explications voulus. Il est bon également d’établir la fiabilité statistique de chaque estimation de l’héritabilité, c’est pourquoi les formules permettant de la calculer figurent aussi dans cette section. Pour en savoir plus, le lecteur pourra se référer à Falconer (1960), Jain (1982) et Namkoong et al. (1966).
Nous illustrerons ces techniques à l’aide des données du Tableau 6.1, obtenues à l’issue d’un essai sur la descendance de bambous conduit à Vellanikkara et Nilambur, dans le Kerala ; le testage portait sur 6 familles, et a été répété 3 fois pour chaque station, sur des parcelles de 6 arbres chacune. Les données du Tableau 6.1 faisaient partie d’un plus grand ensemble.
Tableau 6.1. Données sur la hauteur issues d’un test sur la descendance de bambous, avec répétitions, conduit sur deux stations, dans le Kerala.
|
Hauteur (en cm) deux ans après la plantation |
|||||||||||||
|
Site I - Vellanikkara |
Site II – Nilambur |
||||||||||||
|
Famille |
Famille |
||||||||||||
|
Bloc |
Arbre |
1 |
2 |
3 |
4 |
5 |
6 |
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
1 |
142 |
104 |
152 |
111 |
23 |
153 |
24 |
18 |
18 |
31 |
95 |
57 |
|
2 |
95 |
77 |
98 |
29 |
48 |
51 |
58 |
50 |
24 |
26 |
42 |
94 |
|
|
3 |
138 |
129 |
85 |
64 |
88 |
181 |
32 |
82 |
38 |
30 |
43 |
77 |
|
|
4 |
53 |
126 |
118 |
52 |
27 |
212 |
27 |
23 |
65 |
86 |
76 |
39 |
|
|
5 |
95 |
68 |
25 |
19 |
26 |
161 |
60 |
56 |
46 |
20 |
41 |
82 |
|
|
6 |
128 |
48 |
51 |
25 |
26 |
210 |
75 |
61 |
104 |
28 |
49 |
29 |
|
|
2 |
1 |
185 |
129 |
78 |
28 |
35 |
140 |
87 |
26 |
78 |
25 |
29 |
54 |
|
2 |
117 |
131 |
161 |
26 |
21 |
79 |
102 |
103 |
57 |
37 |
72 |
56 |
|
|
3 |
135 |
135 |
121 |
25 |
14 |
158 |
74 |
55 |
60 |
52 |
83 |
29 |
|
|
4 |
155 |
88 |
124 |
76 |
34 |
93 |
102 |
43 |
26 |
139 |
40 |
67 |
|
|
5 |
152 |
75 |
118 |
43 |
49 |
151 |
20 |
100 |
59 |
49 |
24 |
42 |
|
|
6 |
111 |
41 |
61 |
86 |
31 |
171 |
80 |
98 |
70 |
97 |
54 |
47 |
|
|
3 |
1 |
134 |
53 |
145 |
53 |
72 |
109 |
54 |
58 |
87 |
17 |
25 |
38 |
|
2 |
35 |
82 |
86 |
32 |
113 |
50 |
92 |
47 |
93 |
23 |
30 |
38 |
|
|
3 |
128 |
71 |
141 |
24 |
37 |
64 |
89 |
33 |
70 |
29 |
26 |
36 |
|
|
4 |
89 |
43 |
156 |
182 |
19 |
82 |
144 |
108 |
47 |
30 |
36 |
72 |
|
|
5 |
99 |
71 |
121 |
22 |
24 |
77 |
100 |
70 |
26 |
87 |
24 |
106 |
|
|
6 |
29 |
26 |
55 |
52 |
20 |
123 |
92 |
46 |
40 |
31 |
37 |
61 |
|
Pour estimer l’héritabilité et le gain génétique, sur la base d’un examen de la descendance de familles à demi apparentées, on procède en plusieurs étapes:
*Etape 1. Etablir un test de la descendance répété portant sur la descendance obtenue par pollinisation libre de f familles, répétée b (pour bloc) fois sur chacune des s stations, sur des parcelles de n arbres. Mesurer un caractère, comme la hauteur, et calculer l’analyse de la variance comme indiqué dans le Tableau 6.2. La descendance d’une plante femelle quelconque constitue une famille.
Tableau 6.2. Représentation schématique de l’analyse de la variance relative à un test de la descendance de familles à demi-apparentées pratiqué sur plusieurs plantations.
|
Source de variation |
Degré de liberté (df) |
Somme des carrés (SS) |
Carré moyen
|
|
Station |
s - 1 |
SSS |
MSS |
|
Bloc dans la station |
s (b - 1) |
SSB |
MSB |
|
Famille |
f - 1 |
SSF |
MSF |
|
Famille x Site |
(f - 1)(s - 1) |
SSFS |
MSFS |
|
Famille x Bloc dans la station |
s(f - 1) (b - 1) |
SSFB |
MSFB |
|
Arbre dans la parcelle |
bsf (n - 1) |
SSR |
MSR |
Les formules permettant de calculer les différentes sommes des carrés de la table d’analyse de la variance sont données plus loin, de même que la formule du facteur de correction (C.F.). Soit yijkl l’observation correspondant au l-ème arbre appartenant à la k-ème famille du j-ème bloc dans la i-ème station. Soit G le total général, Si le total de la i-ème station, Fk le total de la k-ème famille, (SB)ij le total du j-ème bloc dans la i-ème station, (SF)ik le total de la k-ème famille dans la i-ème station, (SBF)ijk le total de la k-ème famille dans le j-ème bloc de la i-ème station.
C F = ![]() (6.1)
(6.1)
=![]()
=1100531.13
SSTO = ![]() (6.2)
(6.2)
= (142)2+(95)2+…….+(61)2 - 1100531.13
= 408024.87
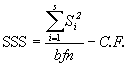 (6.3)
(6.3)
=![]() -1100531.13
-1100531.13
= 48900.46
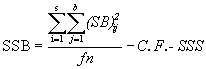 (6.4)
(6.4)
= ![]() -1100531.13 - 48900.46
-1100531.13 - 48900.46
= 9258.13
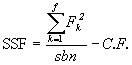 (6.5)
(6.5)
= ![]() - 1100531.13
- 1100531.13
= 80533.37
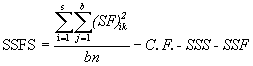 (6.6)
(6.6)
= ![]() - 1100531.13 - 48900.46 - 80533.37
- 1100531.13 - 48900.46 - 80533.37
= 35349.37
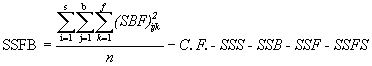 (6.7)
(6.7)
= ![]() - 1100531.13 - 48900.46 -
- 1100531.13 - 48900.46 -
9258.13 - 80533.37 - 35349.37
= 45183.87
![]() (6.8)
(6.8)
= 408024.87 - 48900.46 - 9258.13 - 80533.37 -35349.37 - 45183.87
= 188799.67
Les carrés moyens se calculent de la manière habituelle en divisant les sommes des carrés par leurs degrés de liberté. Les résultats qui précèdent peuvent être mis en tableau (voir Tableau 6.3).
Tableau 6.3. Table d’analyse de la variance pour un testage de la descendance de familles à demi-apparentées, pratiqué sur plusieurs plantations, à partir des données du Tableau 6.1.
|
Source de variation |
Degré de liberté (df) |
Sommes des carrés (SS) |
Carré moyen
|
|
Station |
1 |
48900.46 |
48900.46 |
|
Bloc-dans la station |
4 |
9258.13 |
2314.53 |
|
Famille |
5 |
80533.37 |
16106.67 |
|
Famille x station |
5 |
35349.37 |
7069.87 |
|
Famille x Bloc- dans la station |
20 |
45183.87 |
2259.19 |
|
Arbre- dans la parcelle |
180 |
188799.67 |
1048.89 |
En général, dans les études statistiques, on divise de plusieurs manières les carrés moyens les uns par les autres pour obtenir des valeurs de F qui servent ensuite à tester la signification. Toutefois, comme les carrés moyens sont par nature complexes, puisqu’ils contiennent généralement des variabilités dues à plusieurs facteurs, on les fractionne en composantes de la variance selon les équivalents présentés dans le Tableau 6.4.
Tableau 6.4. Composantes de la variance des carrés moyens pour un test de la descendance de familles à demi-apparentées, pratiqué dans plusieurs plantations.
|
Source de variation |
Composantes de la variance des carrés moyens |
|
Station |
Ve + n Vfb + n b Vfs + nf Vb + nfb Vs |
|
Bloc-dans la station |
Ve + n Vfb + nf Vb |
|
Famille |
Ve + n Vfb + n b Vfs + nbs Vf |
|
Famille x Station |
Ve + n Vfb + nb Vfs |
|
Famille x Bloc- dans la station |
Ve + n Vfb |
|
Arbre- dans la parcelle |
Ve |
Dans le Tableau 6.4, Ve , Vfb , Vfs , Vf , Vb , et Vs sont les variances dues respectivement à l’arbre dans la parcelle, à la famille x bloc dans la station, à la famille, au bloc dans la station, et à la station.
*Etape 2. Une fois les carrés moyens calculés, identifier chacun d’entre eux à sa composante de la variance, comme dans le Tableau 6.4. Commencer par le bas du tableau de manière à calculer les variances suivantes par un processus de soustraction et division. Pour ce faire, soustraire le carré moyen dans la parcelle (Ve) du carré moyen famille x bloc (Ve + nsVfb) pour obtenir nsVfb ; diviser ensuite par ns pour obtenir Vfb. Procéder de la même manière jusqu’au haut du tableau.
*Etape 3. Après avoir calculé les variances, évaluer l’héritabilité des moyennes des familles à demi-apparentées.
Héritabilité de la Famille 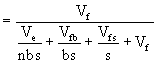 (6.9)
(6.9)
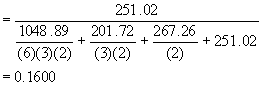
En général, la sélection se fait sur la base des moyennes familiales, plus fiables que les moyennes par parcelle ou par arbre.
*Etape 4. Si la sélection est basée sur les performances d’arbres individuels, on calcule l’héritabilité individuelle. Dans un test de la descendance de familles à demi-apparentées, les différences entre familles représentent un quart seulement de la variance génétique additive ; le reste représente les variations au sein des familles. On multiplie donc Vf par 4 lorsque l’on calcule l’héritabilité individuelle. En outre, comme la sélection est basée sur des arbres individuels, toutes les variances sont insérées en totalité dans le dénominateur. La formule donnant l’héritabilité individuelle est donc,
Héritabilité individuelle ![]() (6.10)
(6.10)
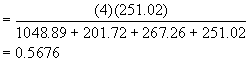
Si les familles ne sont testées que dans une seule plantation, les procédures de test et de calcul sont très simplifiées. Au total, les degrés de liberté sont nfb -1; les carrés moyens et les variances de la station et de la famille x station sont éliminés du Tableau 6.2. Les familles ne sont mesurées que sur une station, alors qu’elles pourraient avoir une croissance très différente ailleurs. La valeur calculée de Vf est en réalité une combinaison de Vf et Vfs. L’héritabilité calculée à partir des données provenant d’une seule plantation est donc surévaluée.
L’enregistrement et l’analyse de données concernant un arbre individuel sont les phases les plus laborieuses, puisqu’elles absorbent souvent 75% des efforts de mesure et de calcul. Si les données sont analysées en termes de moyenne par parcelles plutôt que de moyennes par arbre, les estimations de Vfb, Vfs, et Vf ne varient pas, mais Ve ne peut pas être déterminé. Le terme (Ve/nbs) est souvent si petit qu’il est sans incidence sur l’estimation de l’héritabilité familiale. L’héritabilité individuelle est en revanche légèrement surévaluée si l’on omet Ve. On gagnera du temps en ne prenant en considération que les moyennes familiales sur des stations différentes, c’est à dire en calculant seulement Vfs et Vf . Normalement, l’élimination du terme Vfb/bs entraîne une légère surestimation de l’héritabilité familiale, alors que la suppression du terme Vfb peut être à l’origine d’une surévaluation plus importante de l’héritabilité individuelle.
*Etape 5. Calculer l’erreur type de l’estimation de l’héritabilité individuelle grâce à l’expression,
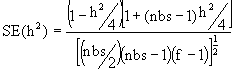 (6.11)
(6.11)
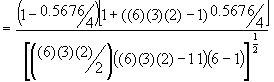
= ![]()
L’erreur type de l’héritabilité familiale est approximativement donnée par,
![]()
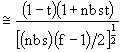 (6.12)
(6.12)
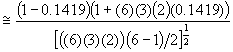
![]()
où t est la corrélation au sein d’une classe (ou corrélation intraclasse), égale à un quart de l’héritabilité individuelle.
Les formules précédentes sont correctes si Ve = Vfb = Vfs. Toutefois, si l’une de ces quantités est nettement supérieure aux autres, le terme nbs sera réduit en conséquence. Par exemple, si, Vfs est nettement supérieur à Vfb ou Ve , on peut remplacer nbs par s.
L’estimation de l’héritabilité familiale calculée plus haut s’applique exclusivement dans le cas où les familles sélectionnées sont celles qui ont les meilleures performances globales dans toutes les plantations. Il arrive qu’un sélectionneur choisisse des familles qui ne sont supérieures que dans une seule plantation. Dans ce cas, l’héritabilité familiale se calcule comme précédemment, mais en remplaçant Vfs par Vfs/s au dénominateur.
Si un sélectionneur se base sur les moyennes de parcelles, seule l’héritabilité familiale est calculée selon la formule ci-dessus, à la différence près que Vfs et Vfb sont respectivement remplacés par Vfs /s et Vfb /bs au dénominateur.
*Etape 6. Pour calculer le gain génétique à partir d’un test de la descendance de familles à demi apparentées, on utilise la formule permettant d’obtenir l’amélioration génétique dérivant d’une sélection familiale.
Gain Génétique = Différentiel de sélection x Héritabilité familiale (6.13)
où Différentiel de sélection = (Moyenne des familles sélectionnées – moyenne de toutes les familles)
Pour calculer le gain attendu d’une sélection de masse dans un tel test de la descendance, on utilise la formule,
Gain attendu de la sélection de masse = Différentiel de sélection x héritabilité individuelle (6.14)
où Différentiel de sélection = (Moyenne des arbres sélectionnés – Moyenne de tous les arbres)
6.1.2. Interaction génotype - environnement
Le phénotype d’un individu est la résultante de son génotype et du milieu dans lequel il se développe. Les effets d’un génotype et de l’environnement ne sont pas toujours indépendants. Une différence particulière dans l’environnement peut avoir plus d’effet sur certains génotypes que sur d’autres, et le classement des génotypes peut varier s’ils sont mesurés dans des environnements différents. Ce jeu réciproque d’effets génétiques et non génétiques sur l’expression phénotypique est appelé interaction génotype - environnement. Lorsqu’un génotype réagit différemment à une série d’environnements, cela signifie que cette interaction existe.
L’environnement d’un individu est fait de tout ce qui a une influence sur son développement, à l’exception de son génotype. On peut donc dire que l’environnement est la somme de tous les facteurs non-génétiques externes à l’organisme. Comstock et Moll (1963) font une distinction entre le micro et le macro-environnement. Le micro-environnement est celui d’un seul organisme, à l’exclusion de tout autre qui se développerait en même temps et pratiquement au même endroit. Plus spécifiquement, les différences micro-environnementales sont des fluctuations de l’environnement qui se produisent même lorsque des individus sont apparemment soumis à des traitements identiques. En revanche, le terme macro-environnement désigne l’ensemble des environnements, potentiels ou effectifs, dans une zone et une période de temps déterminées. Un macro-environnement est donc en quelque sorte l’ensemble des micro-environnements qu’il pourrait contenir. Les différences de stations, de climat et même de pratiques de gestion sont des exemples de différences macro-environnementales. On notera que l’effet d’un micro-environnement sur un organisme, et ses interactions avec différents génotypes sont habituellement très faibles. De plus, étant donné qu’un micro-environnement est par nature incontrôlable et imprévisible, ses interactions avec les génotypes sont difficilement discernables. En d’autres termes, seule la déviation macro-environnementale et son interaction avec un génotype peuvent être isolées et soumises à un test de signification.
L’une des méthodes employées pour détecter une interaction génotype-environnement consiste à analyser les données provenant d’un essai multi-stations, comme dans le Tableau 6.2, et à tester la signification du terme d’interaction Famille x Station. On compare la valeur calculée de F à sa valeur tabulaire dans le cas de (f-1)(s-1) et s(f-1)(b-1) degrés de liberté (Voir Tableau 6.5).
Si l’interaction n’est pas significative ou ne comporte pas de différences notables de classement entre les meilleures familles ou clones, celles-ci peuvent être ignorées et les sélections seront faites sur la base de la performance moyenne du génotype, sur toutes les stations examinées. En revanche, si les interactions sont importantes et peuvent être assez bien interprétées pour pouvoir déterminer à l’avance les endroits où certains génotypes auront une croissance excellente ou, au contraire, médiocre, elles ne peuvent pas être ignorées. Pour déterminer si elles sont significatives, on procède comme suit : Regrouper les données provenant de plusieurs plantations suivant les caractéristiques de la station (nord/sud ; sec/humide ; peu fertile/fertile). Déterminer la quantité d’interaction à l’intérieur de ces groupes et entre eux. Si une part importante de l’interaction peut être imputable au regroupement, faire des sélections distinctes pour les stations représentatives de chaque groupe de plantation. Ensuite, la procédure correcte consiste à faire une analyse de variance distincte et une estimation de l’héritabilité pour chaque groupe de plantation au sein duquel les interactions sont trop faibles ou trop difficiles à interpréter pour avoir une signification pratique.
Tableau 6.5. Analyse de la variance pour un test multi-plantations de la descendance de familles à demi-apparentées.
|
Sources de variation |
Degrés de liberté |
Somme des carrés |
Carré moyen |
F calculé |
F Tabulaire5 % |
|
Station |
1 |
48900.46 |
48900.46 |
||
|
Bloc dans la station |
4 |
9258.13 |
2314.53 |
||
|
Famille |
5 |
80533.37 |
16106.67 |
||
|
Famille x station |
5 |
35349.37 |
7069.87 |
|
2.71 |
|
Famille x bloc dans la station |
20 |
45183.87 |
2259.19 |
||
|
Arbre dans la parcelle |
180 |
188799.67 |
1048.89 |
* Significatif au seuil de 5% .
Une autre approche consiste à utiliser la technique de régression pour répartir la composante de variabilité de l’interaction génotype – environnement entre ses fractions linéaires et non linéaires, en vue d’évaluer la stabilité des génotypes sur une série d’environnements (Freeman et Perkins, 1971). Un examen plus approfondi de cette méthode n’a pas sa place dans cette section.
6.1.3. Plans de vergers à graines
Un verger à graines est une plantation d’arbres génétiquement supérieurs, isolés pour réduire la pollinisation de sources externes génétiquement inférieures, et gérée de manière intensive pour produire des récoltes de graines fréquentes, abondantes et faciles à ramasser. Pour ce faire, on désigne des clones (sous la forme de greffons ou de boutures) ou des plantules descendant d’arbres sélectionnés pour les caractéristiques recherchées. La présente section décrit certains plans utilisés pour l’établissement de vergers à graines, principalement à des fins statistiques. Des ouvrages sur l’amélioration génétique des arbres, comme celui de Wright (1976) et Faulkner (1975) donnent des informations sur plusieurs autres aspects de la planification des vergers à graines, notamment sur le type de clones ou de plantules utilisés pour la plantation, le nombre de clones ou de familles, les écartements de plantation, et sur d’autres éléments connexes.
Dans le cas de vergers à graines de clone, les plants d’un même clone sont appelés ramets. Toutefois, dans cette section, les termes " clone " ou " ramet ", tels qu’ils s’appliquent dans des vergers à graines de clones, sont utilisés à des fins descriptives. On peut adopter des plans analogues pour les vergers à graines de plantule, et dans ce cas on dira " descendance " au lieu de " clone " et " parcelle familiale " au lieu de " ramet ". Les parcelles familiales peuvent être composées d’un seul arbre ou de groupes de plusieurs arbres.
Un plan entièrement randomisé (PER) avec sélection entièrement aléatoire de tous les ramets disponibles de tous les clones, entre toutes les positions de plantation disponibles sur la station, est le plus simple à concevoir, sur le papier. Toutefois, sa réalisation pose parfois des problèmes liés à la plantation, ou au greffage in situ et à la réimplan tation de chaque ramet à un stade ultérieur, en particulier si le verger est grand et contient de nombreux clones. S’il est prévu de pratiquer des éclaircies systématiques en enlevant un arbre sur deux ou un rang sur deux, le plan peut être encore amélioré en faisant des randomisations distinctes pour les ramets qui doivent être laissés en place et pour ceux qui seront supprimés lors des éclaircies. Assez souvent, la randomisation est limitée par des restrictions, par exemple par une interdiction de planter deux ramets du même clone l’un à côté de l’autre à l’intérieur des rangées ou des colonnes, ou bien dans des positions adjacentes, en diagonale ; ou qu’au moins deux ramets différents s’intercalent entre des ramets du même clone. Ces restrictions supposent généralement de manipuler les positions des ramets sur le plan, qui perd alors son caractère purement aléatoire, mais il est rare que cette perte soit réellement significative. Cette stratégie vise essentiellement à éviter les risques de consanguinité.
Nous illustrerons ce qui précède par la représentation graphique d’un plan entièrement randomisé comportant une dizaine de répétitions, relatif à dix clones plantés, avec un anneau d’isolation.
Figure 6.1. Représentation schématique d’un PER, comportant dix répétitions, concernant 10 clones, avec un anneau d’isolation autour des ramets de chaque clone.
|
4 |
7 |
4 |
8 |
5 |
10 |
7 |
6 |
4 |
7 |
|
8 |
3 |
9 |
1 |
2 |
1 |
3 |
5 |
3 |
5 |
|
6 |
1 |
5 |
3 |
10 |
5 |
10 |
9 |
7 |
10 |
|
8 |
4 |
2 |
1 |
9 |
7 |
6 |
3 |
5 |
8 |
|
5 |
7 |
3 |
6 |
2 |
3 |
5 |
2 |
10 |
2 |
|
1 |
10 |
4 |
7 |
10 |
6 |
8 |
4 |
1 |
5 |
|
9 |
7 |
6 |
3 |
5 |
2 |
7 |
3 |
6 |
2 |
|
1 |
5 |
2 |
10 |
1 |
3 |
10 |
5 |
4 |
9 |
|
8 |
10 |
4 |
7 |
5 |
7 |
8 |
2 |
1 |
6 |
|
7 |
2 |
8 |
6 |
1 |
4 |
6 |
7 |
10 |
4 |
Ces concepts peuvent être élargis aux plans expérimentaux en blocs aléatoires complets (PEBAC) ou aux plans en blocs incomplets, comme les treillis examinés dans le chapitre 4 de ce manuel, qui permettent de contrôler plus facilement la composante d’erreur. Toutefois, la randomisation à l’intérieur des blocs est ordinairement modifiée pour respecter les restrictions concernant la proximité des ramets d’un même clone. Ces plans d’expérience sont surtout appropriés pour les études comparatives de clones, mais ils ont des inconvénients, notamment : le PEBAC ne fonctionne pas bien avec un grand nombre de clones ; les treillis et les autres plans en blocs incomplets ne sont disponibles que pour certaines combinaisons déterminées de nombre de clones et de nombres de ramets par clone, et sont inapplicables dans le cas d’éclaircies systématiques qui détruiraient le plan.
La Bastide (1967) a mis au point un programme informatique qui fournit un plan réalisable pour des nombres déterminés de clones, de ramets par clone, et pour un rapport déterminé entre les lignes et les colonnes. Ce programme comporte deux contraintes : premièrement, il faut un double anneau de clones différents pour isoler chaque ramet d’un même clone (qui sont plantés dans des rangs disposés en quinconce) ; une combinaison quelconque de deux clones adjacents ne peut se trouver qu’une seule fois dans une direction spécifique quelconque (voir Figure 6.2.). Ce plan peut être appelé " plan de permutation des combinaisons de voisinage ".
Figure 6.2. Fragment d’un plan de permutation des combinaisons de voisinage relatif à 30 clones, avec les restrictions au caractère aléatoire imposées par La Bastide (1967) dans son programme informatique, à savoir i) 2 anneaux de clones différents isolent chaque ramet, et ii) une combinaison quelconque de deux clones adjacents ne peut pas se retrouver plus d’une fois dans une direction spécifique quelconque.
L’idéal est que le plan soit construit pour un nombre de répétitions égal au nombre de clones diminué de un, de façon à ce que chaque clone se trouve à côté de chaque autre clone une fois dans chacune des six directions possibles. Pour trente clones, il faudrait donc 29 ramets par clone, soit au total 870 greffons, même s’il n’est pas toujours possible de construire des plans de cette taille. Même dans ce cas, les petits blocs qui ont été créés sont pour l’instant les meilleurs plans dont on dispose pour garantir, au moins en théorie, la permutation maximale des combinaisons de voisinage et la production minimale de frères complets dans la descendance du verger. Chakravarty et Bagchi (1994) et Vanclay (1991) décrivent de bons programmes d’ordinateur permettant de construire des plans de permutation de voisinage relatifs à des vergers à graines..
Lorsque l’on établit des vergers à graines, on part ordinairement de l’hypothèse que chaque clone (ou ramet, ou parcelle familiale ou plantule) du verger fleurira à la même période ; aura le même cycle de grosse floraison périodique ; sera complètement inter fécondable avec tous ses voisins et produira un nombre identique de semences viables par plant; aura le même degré de résistance à l’autostérilité ; et aura un taux de croissance et une forme de couronne similaires à tous les autres plants. Comme chacun sait, il n’en est, et n’en sera probablement jamais ainsi. Pour obtenir de bons résultats, un sélectionneur doit être patient et observateur et rassembler sans relâche toutes les informations essentielles sur le comportement des clones, leurs compatibilités et leurs facultés de combinaison, et en tenir compte pour améliorer les générations prochaines et successives de vergers à graines. Ce type de plans utilise le maximum de données existantes.
6.2.1. Equations de volume et de biomasse
Dans de nombreux domaines de recherche forestière, comme la sylviculture, l’écologie ou la science du bois, on doit déterminer le volume ou la biomasse des arbres, le plus souvent, d’une partie spécifique de l’arbre. Comme les méthodes physiques de mesure du volume et de la biomasse sont destructrices, on peut recourir à des équations préétablies pour obtenir des estimations de ces caractéristiques. Ces équations varient d’une espèce à l’autre, et pour une espèce donnée, d’un peuplement à l’autre. Les estimations se rapportant à un seul arbre manquent parfois de précision, mais elles sont valables si on les refait pour plusieurs arbres, et si l’on additionne les résultats, comme pour calculer le volume d’un peuplement. Dans tous les cas où l’on ne dispose pas d’une équation appropriée, on devra établir une équation prédictive. Il faut pour cela déterminer le volume ou la biomasse réels d’un ensemble d’arbres-échantillons et les relier, par une analyse de la régression, à des mesures non-destructrices telles que le diamètre à hauteur d’homme ou la hauteur des arbres.
(i) Mesure du volume et de la biomasse d’un arbre
La détermination du volume d’une partie spécifique de l’arbre, telle que le fût ou une branche, s’obtient, en général, en découpant la partie considérée en grumes, puis en mesurant celles-ci. Les grumes coupées aux fins de la recherche font généralement 3 mètres de long, sauf celle de l’extrémité supérieure qui peut mesurer jusqu’à 4,5m. Cependant, si le dernier tronçon fait plus de 1,5m de long, on le considère comme une grume et on le met de côté. Le diamètre, ou la circonférence, se mesure au centre et aux deux extrémités de la grume, ou en bas, au milieu et au sommet des grumes, selon le cas. On mesure aussi la longueur de chaque grume. Les mesures peuvent être prises sur ou sous écorce, après l’avoir enlevée. Selon les mesures dont on dispose, on peut calculer le volume de chaque grume à l’aide de l’une des formules du tableau ci-dessous.
|
Volume de la grume |
Observations |
|
|
Formule de Smalian |
|
|
Formule de Huber |
|
|
Formule de Newton |
où b est la circonférence de la base de la grume,
m est la circonférence de la partie centrale de la grume
t est la circonférence du fin bout de la grume
l est la longueur ou la hauteur de la grume
Pour expliquer le calcul du volume d’un arbre à l’aide des formules ci-dessus, nous prendrons les données sur la longueur et la circonférence (du bas, du milieu et du bout) de différentes grumes d’un arbre, reprises dans le Tableau 6.6.
Tableau 6.6. Circonférences (du bas, du milieu et du bout) et longueurs des grumes d’un teck.
|
Circonférence (cm) |
Volume des grumes (cm)3 |
||||||
|
Numéro de la grume |
Bas (b) |
Milieu (m) |
Bout (t) |
Longueur (l) |
Formule de Smalian |
Formule de Huber |
Formule de Newton |
|
1 |
129.00 |
99.00 |
89.00 |
570.00 |
556831.70 |
444386.25 |
481868.07 |
|
2 |
89.00 |
90.10 |
91.00 |
630.00 |
405970.57 |
406823.00 |
406538.86 |
|
3 |
64.00 |
60.00 |
54.90 |
68.00 |
19229.35 |
19472.73 |
19391.60 |
|
4 |
76.00 |
85.00 |
84.60 |
102.00 |
52467.48 |
58621.02 |
56569.84 |
|
5 |
84.90 |
80.10 |
76.20 |
111.00 |
57455.84 |
56650.45 |
56918.91 |
|
Total |
1091954.94 |
985953.45 |
1021287.28 |
||||
En additionnant les volumes de chaque grume, on obtiendra la valeur du volume de l’arbre ou de la partie considérée. On peut exprimer ce volume en m3 en divisant la valeur obtenue (en (cm)3) par 1000.000.
Dans le commerce du bois, la mesure utilisée est généralement le volume, mais certains produits comme le bois de feu ou le bois de trituration se vendent aussi au poids. Le poids est aussi la mesure standard pour de nombreux produits forestiers mineurs. En recherche, on se réfère de plus en plus souvent à la biomasse. Il est certes plus facile de déterminer le poids plutôt que le volume, mais divers problèmes, comme le caractère variable de la teneur en humidité et de l’épaisseur de l’écorce, font que cette mesure n’est pas fiable. On exprime donc en général la biomasse en poids sec des parties de l’arbre (tronc, branches, et feuilles). On utilise des méthodes destructrices pour déterminer la biomasse d’arbres individuels, en les abattant et en séparant les parties, comme le tronc, les branches, les rameaux et les feuilles. Il importe de bien définir toutes les parties constituantes de l’arbre: par exemple, tout matériel issu du tronc, dont la circonférence mesurée sur écorce est inférieure à 10 cm, fait partie du bois des branches. Les différentes parties doivent être pesées immédiatement après l’abattage. Si l’on veut obtenir des poids séchés à l’étuve, les échantillons sont prélevés à ce stade. Au moins trois échantillons d’environ 1 kilo doivent être prélevés sur le tronc, les branches et les rameaux de chaque arbre ; ensuite il faut les peser et les emporter au laboratoire pour le séchage à l’étuve. Le poids sec total de chaque partie constituante de l’arbre est ensuite estimé en appliquant le rapport poids frais / poids sec observé dans l’échantillon, au poids frais total correspondant des parties constituantes de l’arbre. Par exemple,
![]() (6.15)
(6.15)
où FW = Poids frais
DW = Poids sec
Pour illustrer ceci par un exemple, nous prendrons les données du Tableau 6.7.
Tableau 6.7. Poids frais et poids sec de disques-échantillons prélevés sur le fût d’un arbre
|
Disque |
Poids frais (kg) |
Poids sec (kg) |
|
1 |
2.0 |
0.90 |
|
2 |
1.5 |
0.64 |
|
3 |
2.5 |
1.37 |
|
Total |
6.0 |
2.91 |
![]()
DW total du fût de l’arbre = 460.8 kg
(ii) Estimation d’équations allométriques
Les données sur le volume ou la biomasse ainsi que sur le diamètre à hauteur d’homme (dbh) et la hauteur issues de l’observation d’arbres-échantillons, sont utilisées pour développer des équations prédictives, à l’aide de techniques de régression. Pour les équations de biomasse, on prend parfois comme variable de régression un diamètre mesuré à un point plus bas que la hauteur de poitrine. Le volume, ou la biomasse, est la variable dépendante et les fonctions du dbh et de la hauteur sont les variables indépendantes de la régression. On trouvera ci-dessous quelques formes classiques d’équations prédictives du volume ou de la biomasse.
y = a + b D + c D2 (6.16)
ln y = a + b D (6.17)
ln y = a + b ln D (6.18)
y0.5 = a + b D (6.19)
y = a + b D2H (6.20)
ln y = a + b D2H (6.21)
y0.5 = a + b D2H (6.22)
ln y = a + b ln D + c ln H (6.23)
y0.5 = a + b D + c H (6.24)
y0.5 = a + b D2 + c H + d D2H (6.25)
Dans toutes ces équations, y représente le volume ou la biomasse de l’arbre, D est son diamètre mesuré, de manière uniforme pour tous les arbres-échantillon, à hauteur d’homme ou à un point plus bas, H sa hauteur et a, b, c des coefficients de régression (ln indique le logarithme naturel).
En général, plusieurs formes d’équations sont adaptées aux données, et la plus appropriée est choisie sur la base de certaines mesures, comme le coefficient de détermination ajusté, ou l’indice de Furnival. Ce dernier doit impérativement être utilisé si l’on doit comparer des modèles comprenant des variables dépendantes de formes différentes.
![]() (6.26)
(6.26)
où R2 est le coefficient de détermination, donné par le rapport de la somme des carrés de régression à la somme totale des carrés (voir Section 3.7)
n est le nombre d’observations concernant la variable dépendante
p est le nombre de paramètres intervenant dans le modèle
L’indice de Furnival se calcule comme suit. Pour chaque modèle intervenant dans l’analyse de la variance, on calcule la racine carrée du carré moyen de l’erreur. A partir des observations, on détermine, pour chaque modèle, la moyenne géométrique de la dérivée de la variable dépendante par rapport à y. La moyenne géométrique d’un ensemble de n observations est définie par la racine n-ème du produit des observations. L’indice de Furnival de chaque modèle s’obtient ensuite en multipliant les valeurs correspondantes de la racine carré du carré moyen de l’erreur par l’inverse de la moyenne géométrique. Par exemple, la dérivée de ln y est (1/y) et l’indice de Furnival est dans ce cas,
Indice de Furnival = 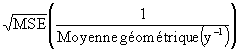 (6.27)
(6.27)
La dérivée de y0.5 est (1/2)(y - 0.5) ; l’Equation (6.27) devra donc être modifiée en conséquence si la variable dépendante est y0.5.
A titre d’exemple, prenons les données du Tableau 6.8 sur le poids sec et le diamètre à hauteur d’homme de 15 acacias.
