![]()
![]()
![]()
par Hélène Dessard
L'objectif de cette annexe est de rappeler quelques définitions et principes généraux de base sur la théorie de l'échantillonnage. Ils permettront à l'utilisateur de mieux saisir les fondements des différentes techniques de sondage et, par la suite, de choisir une classe de plans d'échantillonnage sensée répondre à l'objectif poursuivi, en s'appuyant davantage sur des considérations statistiques que sur des intuitions relevant de projections personnelles.
L'objectif de l'échantillonnage est de connaître les propriétés d'une population à partir de l'analyse d'une fraction de celle-ci. Cette pratique est née de l'impossibilité de procéder, pour des raisons de coûts et de temps, à des recensements exhaustifs des caractéristiques d'une population, à commencer par sa taille! On ne cherche pas à connaître, en général, les valeurs de la (les) caractéristique(s) sur tous les éléments de la population, mais plutôt à inférer (en termes statistiques) ou à «prédire» et «extrapoler» (en termes courants) une fonction de ces valeurs, à partir d'un échantillon, donc d'un sous-ensemble de ces valeurs. Bien évidemment, comme on examine seulement une partie de la population, la prédiction sera entachée d'une erreur due au fait que l'on échantillonne. Elle est appelée erreur d'échantillonnage et c'est elle qu'on cherche à minimiser en choisissant le plan de sondage le plus pertinent pour obtenir la meilleure prédiction possible.
Population finie U: c'est l'ensemble des N unités sur lesquelles on mesure un (ou plusieurs3 ) caractère Y = (Y1,Y2,... YN). On cherche à connaître certaines caractéristiques d'une population finie4 , notées q appelées aussi paramètres. Cet ensemble possède autant de dimensions qu'il y a de caractéristiques à estimer. Si on s'intéresse au total du nombre d'arbres et à la hauteur moyenne du peuplement, alors q est un vecteur de longueur 2.
Echantillon5 : c'est un sous-ensemble, de taille n W N, de la population à partir duquel certains caractères de la population vont être «estimés». La façon dont il est constitué définit également ses propriétés comme l'occurrence multiple d'une même unité (lorsqu'on effectue un tirage avec remise), l'ordre des unités, etc.
Estimateur: c'est simplement une fonction des données Φ (s), par exemple une somme pondérée, lorsque l'on calcule une moyenne. L'estimateur est une variable aléatoire et, à ce titre, il est aussi caractérisé par sa distribution de probabilité sur l'ensemble des échantillons (on parle alors de sa distribution d'échantillonnage). Il possède donc une espérance et une variance. Pour estimer un paramètre, on a parfois plusieurs estimateurs disponibles et un critère de choix pratique est l'erreur quadratique moyenne: l'espérance du carré de l'écart entre l'estimateur et la valeur vraie du paramètre, soit E [(Φ (s) - q )2 ]. En effet plus celle-ci est petite, plus la précision de l'estimation est grande.
Plan d'échantillonnage6 : d'un point de vue statistique, le plan désigne en fait la loi de probabilité définie sur l'ensemble des échantillons possibles, c'est-à-dire la probabilité de sélection d'un échantillon. Par exemple, si la population est constituée de trois éléments {1,2,3}, l'ensemble des échantillons non ordonnés sans remise de taille 2 est ζ = {{1,2},{1,3},{2,3}}.
Pour chaque échantillon s de ζ, on définit P(s) Ž 0,
avec
![]()
Par exemple: P({1,2}) = 0,6; P({2,3}) = 0,3; P({1,3}) = 0,1. On est dans le cadre d'un plan à probabilités inégales.
Stratégie d'échantillonnage: combinaison du choix du plan d'échantillonnage et de l'estimateur.
Probabilité d'inclusion: probabilité d'appartenance à l'échantillon d'une unité i (probabilité simple πi) ou de deux unités i et j simultanément (probabilité double ou conjointe πij) (Cochran, 1977). On les calcule de la façon suivante:
![]()
En reprenant l'exemple précédent, on a:
π1 = 0,7; π2 = 0,9; π3 = 0,4.
Variable d'intérêt: variable mesurée sur les unités de l'échantillon dont on cherche à estimer une fonction, c'est-à-dire un total, une moyenne, un ratio, etc.
Variable auxiliaire7 : variable corrélée à la variable d'intérêt connue sur toutes les unités de la population avant la réalisation de l'inventaire.
Représentativité: un d'échantillon est dit «représentatif» lorsque aucune des probabilités d'inclusion n'est nulle. En d'autres termes, toute unité a une chance non nulle d'appartenir à l'échantillon. C'est le plan d'échantillonnage qui définit ces probabilités. Si l'on désire obtenir une estimation précise, il est nécessaire d'accroître l'intensité d'échantillonnage dans les zones de plus forte variabilité, contrairement aux zones plus homogènes.
Modèle de superpopulation: l'approche classique considère que les caractères mesurés sont fixes, la procédure d'échantillonnage forme alors à elle seule la base de l'inférence8 . L'approche modèle considère que les caractères observés sont en fait des réalisations de variables aléatoires. La population à laquelle on s'intéresse est elle-même un échantillon aléatoire d'une (ou plusieurs) superpopulation. L'échantillon provient alors d'un double tirage: le premier consiste à tirer les N valeurs observées de la population, le deuxième est constitué du plan d'échantillonnage, conditionnellement à ces valeurs. L'inférence est donc également réalisée en s'appuyant sur le modèle. Cette approche peut s'avérer extrêmement utile pour choisir un plan de sondage.
Robustesse: ce concept très général signifie qu'une procédure ou un système soumis à une perturbation produit des résultats similaires à ceux obtenus sans perturbations.
Informations a priori, a posteriori: bien que cette notion ait été abordée via la définition d'une variable auxiliaire, on accordera à l'information auxiliaire une portée plus générale. Lorsque l'information est incorporée a priori, les stratégies d'échantillonnage sont plus nombreuses et l'utilisateur a peut-être plus de chance de bien choisir son plan (au prix d'une évaluation plus coûteuse!). Lorsque l'information est utilisée a posteriori, elle sert à «redresser les estimateurs», comme l'estimateur poststratifié, mais souvent l'information reste sous-utilisée. Dans tous les cas, si on dispose d'une ou plusieurs variables auxiliaires, il est préférable de s'en servir a priori, lorsque c'est possible.
Les propriétés théoriques des plans d'échantillonnage ne sont cependant pas suffisantes pour déterminer le plus performant. En effet, les campagnes de relevés ont des coûts (financier, en temps, en pénibilité également), qui varient selon les endroits. Or ces coûts sont des facteurs qui limitent la réalisation correcte d'un plan d'échantillonnage, spécialement en ce qui concerne la taille de l'échantillon. Rappelons que, in fine, on souhaite estimer certaines caractéristiques de la population avec une précision que l'on se fixe a priori. Atteindre cette précision, pour une stratégie donnée, dépend de la variabilité de la caractéristique au sein de la population. Si celle ci est élevée, il est évident que la taille de l'échantillon devra être importante. Parmi toutes les stratégies envisageables, la précision désirée ne sera pas obtenue au même coût. Ainsi en situation de contrainte, il est indispensable d'évaluer les stratégies d'échantillonnage par un rapport entre la précision et le coût appelé efficience.
Même si l'on s'est efforcé de choisir le plan d'échantillonnage qui semble le plus pertinent, ce choix est toujours un pari. Il n'est guère simple d'évaluer les risques liés à tel ou tel plan, même en décomposant l'erreur quadratique moyenne en fonction des différents paramètres caractérisant un plan de sondage (taux de sondage, nombre de placette, surface et forme des placettes, etc.), ces paramètres n'étant pas indépendants les uns des autres. Par exemple, quand la taille des placettes augmente, le coefficient de variation entre les placettes diminue selon une relation du type:
![]()
avec cv le coefficient de variation de Y, l'écart-type de Y, est la moyenne des Yi, k et b des coefficients positifs, et S la surface de placette. En général, b < 0,5 et de ce fait, pour un même taux de sondage surfacique, la précision diminue avec la taille des placettes, mais en revanche l'efficience peut être améliorée.
Ardilly (1994) explique aussi que «même s'il s'agit d'un paramètre aussi simple qu'une moyenne, on montre qu'il n'existe pas de plan de sondage optimal, c'est-à-dire pas de combinaison «miracle» entre méthode d'échantillonnage et méthode d'estimation qui donne lieu, quelles que soient les valeursYi prises par les N individus de la population, à une erreur quadratique moyenne plus petite que celle que l'on peut obtenir avec n'importe quel autre plan de sondage».
Nous rappellerons dans un premier temps les avantages et inconvénients des plans conventionnels, des plans sous modèle, puis nous discuterons des approches nouvelles qui semblent plus appropriées à l'évaluation d'une ressource rare et dispersée comme celle des arbres hors forêt.
Plans conventionnels. On dénomme ainsi tous les plans d'échantillonnage dont l'inférence est basée sur la distribution de probabilité définie sur l'ensemble des échantillons. Sont exclus les plans dits séquentiels où le recueil des données se poursuit tant que les propriétés de l'estimateur n'ont pas satisfait à un certain critère. Ces plans traditionnels sont décrits de façon générale par Cochran (1977) et dans un cadre forestier par De Vries (1986) et FAO (1973). Leurs propriétés sont bien connues et ces plans sont applicables plutôt pour évaluer la ressource forestière «dans la forêt». Cela dit, ils peuvent aussi convenir à l'évaluation des arbres hors forêt, à condition que ceux-ci ne soient pas trop isolés et trop dispersés. Il est donc souhaitable d'avoir une idée de la dispersion et de la densité de la ressource à estimer. On se contentera de donner ici le principe de base des principaux plans conventionnels, ainsi que quelques éléments qui permettent d'évaluer l'aptitude des plans à répondre à la question.
Plans aléatoires à un niveau:
Plans aléatoires à plusieurs niveaux:
Le plan aléatoire simple est universel, ne requiert aucune information préalable sur la population et permet d'appliquer toutes les méthodes statistiques classiques. En contrepartie, les précisions des estimateurs seront souvent plus faibles que celles des autres plans.
Le plan systématique, très utilisé en écologie, est intéressant par sa facilité de mise en œuvre et par le recouvrement régulier d'une zone d'étude. Il est plus avantageux que le plan aléatoire simple lorsque la population présente une autocorrélation positive ou une tendance linéaire, mais peut s'avérer catastrophique si la variable présente une périodicité coïncidant avec le pas de la grille.
Les autres plans sont fondés sur la disponibilité d'une information structurale.
Le plan à probabilités inégales est fondé sur une probabilité de sélection d'unité dépendante de la valeur de la variable auxiliaire associée. On distingue ici la probabilité de sélection de la probabilité d'inclusion: la probabilité de sélection est la chance qu'une unité soit tirée au cours de la constitution de l'échantillon, alors que la probabilité d'inclusion représente la chance qu'une unité se retrouve dans l'échantillon, une fois l'échantillon formé. Ce plan est recommandé lorsque la variable d'intérêt est à peu près proportionnelle à la variable auxiliaire, que celle-ci varie beaucoup d'une unité à l'autre et que le coût unitaire de mesure est indépendant de l'unité.
Le plan stratifié offre toujours des gains de précisions appréciables lorsque la stratification est correctement faite sur la base d'un critère aussi lié que possible à la variable d'intérêt. En revanche, si les limites des strates sont mal établies, la précision peut devenir très faible. En principe, le nombre de strates accroît la précision, jusqu'à un certain point. On peut utiliser des méthodes de classification pour déterminer le nombre de strates et leurs limites.
Le plan en grappes repose sur la même idée que le plan stratifié, mais leurs champs d'application respectifs sont les suivants: lorsque la variance intraclasses est forte et la variance interclasses faible, on emploie le plan en grappes et le plan stratifié, quand le niveau des variances est inversé.
Enfin, le plan à plusieurs degrés est bien adapté aux populations naturellement hiérarchisées ou si l'on désire estimer les paramètres d'intérêt pour différents niveaux de la population.
Echantillonnage adaptatif en grappe. Ce plan comporte deux étapes. La première consiste à choisir un premier échantillon d'unités selon un plan classique. La seconde étape est équivalente à la deuxième phase d'un sondage en grappes, mais selon une procédure adaptative: la poursuite de l'échantillonnage est fonction de la valeur de la variable mesurée. La population est constituée par l'ensemble des unités issues de la partition9 du domaine d'étude. On sélectionne tout d'abord un sous-ensemble d'unités par un plan conventionnel pour un taux de sondage donné. Puis, sur chaque unité u, le caractère y est mesuré: si y satisfait une condition préalablement définie, toutes les unités dans le voisinage de u sont également mesurées. Le processus est poursuivi tant que la variable y observée sur chaque unité voisine satisfait la condition.
Par exemple, imaginons de petits bosquets dispersés en faible densité sur une assez grande surface. Il est évident que dans cette situation le plan aléatoire simple est fort peu performant. Le paramètre à estimer est le nombre total d'arbres de la région. La région est découpée en sous-unités u (carrées ou rectangulaires) sur lesquelles on mesure la variable y, le nombre d'arbres contenus dans u. La condition retenue est la présence de un arbre (au moins). Le voisinage d'une unité est formé des huit cellules qui l'entourent immédiatement. On tire d'abord l'échantillon de départ par un tirage aléatoire simple, puis pour chacune des unités de l'échantillon, on mesure y.
Si y ≥ 1, alors les huit unités du voisinage sont observées, puis pour chacune, on examine de nouveau les unités de leur voisinage si y Ž 1, sinon les mesures sont stoppées. Si l'unité de l'échantillon de départ ne satisfait pas la condition, son voisinage n'est pas visité.
En définitive, toutes les unités appartenant à l'échantillon de départ et toutes celles qui ont fait l'objet d'une mesure (y compris les cellules de voisines où y = 0) font partie de l'échantillon final. On voit donc qu'on a réalisé un plan d'échantillonnage en grappes de tailles variables.
Cette technique est particulièrement adaptée à l'évaluation d'une ressource rare, regroupée en agrégats, eux-mêmes assez dispersés dans la région d'étude. Ce type d'inventaire n'a été que rarement appliqué, dans l'état actuel de la bibliographie, et donc peu évalué en situation réelle. Par contre, Thompson (1992) a systématiquement comparé les plans conventionnels avec leur version adaptative, qui comporte le même type de plan dans la première phase. Sur la base de ces études, l'efficience de l'ASC est d'autant plus élevée par rapport aux autres plans que la taille de l'échantillon est importante et que la population est plus fortement agrégée.
Echantillonnage en transect guidé. C'est de nouveau un plan en deux phases nécessitant une variable auxiliaire dans la seconde phase. Cette technique, proposée par Ståhl et al. (2000), n'a jamais été mise en œuvre sur le terrain et n'a fait l'objet que d'une comparaison (par simulation) avec un échantillonnage systématique en transects continus. Néanmoins, nous la présentons ici, car elle pourrait s'avérer très prometteuse dans certains cas.
On découpe le domaine d'étude en transects composés de plusieurs bandes jointives découpées en quadrats. A chaque quadrat est associée une valeur de la variable auxiliaire. On commence par constituer un échantillon de transect selon un certain plan. Puis on définit un chemin de passage d'un quadrat à l'autre en fonction d'une stratégie de sélection dépendant de la variable auxiliaire.
Par exemple, un échantillon de transect est constitué par un tirage aléatoire simple ou bien par un tirage à probabilités inégales proportionnelles à la somme de la variable auxiliaire sur le transect. Les auteurs ont examiné trois stratégies de sélection des quadrats lors de la deuxième phase:
Les auteurs comparent l'échantillonnage par transect guidé (GTS) au plan traditionnel par transects continus (TCS), pour un taux d'échantillonnage identique et six types de forêts classées selon l'abondance et la dispersion de la ressource. Ils concluent que le GTS est plus efficace que le TCS lorsque la population est clairsemée et que la meilleure précision est obtenue avec la stratégie 2. Ils notent également que cette méthode doit être étudiée de façon plus approfondie avant d'être appliquée sur le terrain !
Echantillonnage par ensembles classés. Cette méthode est peu utilisée, alors qu'elle peut s'avérer intéressante dans les cas où la variable d'intérêt est difficilement observable ou trop coûteuse à mesurer. La procédure comporte deux phases et repose sur l'existence d'une variable concomitante. On constitue en premier lieu un échantillon aléatoire simple de taille m x m que l'on scinde de façon aléatoire en m échantillons de taille m. Les unités de chaque échantillon sont ensuite rangées dans l'ordre croissant sur la base de l'observation de la variable concomitante. Cette «observation» recouvre tous les moyens d'évaluation peu coûteux, comme un classement visuel (par la taille, couleur...) ou l'avis d'experts, etc. Au cours de la deuxième phase, on mesure la variable d'intérêt sur m unités sélectionnées de la façon suivante: l'unité de rang 1 dans le premier échantillon, l'unité de rang 2 dans le deuxième et ainsi de suite jusqu'à la m-ième dans le dernier. Cette deuxième phase est répétée r fois, à partir de r nouvelles scissions aléatoires des m2 unités. En tout, mr mesures sont effectuées. Cette méthode est une alternative à l'inventaire stratifié aléatoire, beaucoup plus efficace lorsque les coûts de la stratification sont élevés comparés à ceux du classement et que la variable auxiliaire est faiblement corrélée avec la variable d'intérêt. C'est aussi une des rares techniques capable d'intégrer des informations non quantitatives (servant de base de classement) comme des opinions d'experts.
Face, d'une part, à l'émergence du concept d'information auxiliaire, et d'autre part, à la difficulté de définir une stratégie d'échantillonnage optimale, certains statisticiens comme Basu (1971), Brewer (1963), Royall (1971) ont proposé, dans les années 70, de structurer les valeurs de la variable d'intérêt: ils ont simplement considéré que les valeurs Yi n'étaient plus des quantités fixes, mais des variables aléatoires réelles. La population observée n'est donc elle-même qu'une réalisation de la collection des variables aléatoires. On parle donc souvent de modèle de superpopulation. L'avantage mathématique est immédiat, l'information totale contenue par le paramètre de taille N, c'est-à-dire par (Y1, Y2,... Yn), peut être entièrement résumée dans le cas le plus simple par un nombre, on peut penser que les variables Yi sont identiquement et indépendamment distribuées selon une loi de Poisson (définie par un seul paramètre λ). On peut alors montrer que cette nouvelle approche permet de définir des plans optimaux dans certaines familles de plans d'échantillonnage. Les calculs des erreurs sont simplifiés par la réduction de la taille du paramètre dont elles dépendent et des plans peuvent être comparés. Une autre conséquence de cette approche est que le choix de l'estimateur devient complètement indépendant du plan d'échantillonnage, en d'autres termes, on peut constituer son échantillon à sa guise. Bien évidemment, cette méthode comporte quelques risques liés à l'adéquation du modèle avec la distribution réelle de la variable. Si le modèle est très éloigné de la réalité, l'inférence peut donner de très mauvais résultats, c'est-à-dire des estimateurs très biaisés ou à variance très élevée.
Deux courants se dégagent dans la littérature: les plans dont l'inférence est totalement dépendante du modèle et ceux qui s'appuient sur un modèle tout en restant robuste par rapport à lui (Särndal et al., 1992).
Dans de nombreux cas, il sera particulièrement intéressant de mixer plusieurs stratégies de sondage: par exemple, on pourra commencer par stratifier l'espace, puis dans chacune des sous-régions, adopter un plan qui semble adapté à la sous-population sondée (un échantillonnage systématique, à probabilité inégale, etc.; un échantillon qui dépendra des informations dont on dispose sur chacune d'entre elles).
Les expressions des estimateurs et leurs caractéristiques statistiques deviennent alors compliquées, voire intraitables analytiquement, si bien que la comparaison entre plans complexes n'est pas envisagée, ni même avec des plans «simples». L'utilisation de ce type de plan repose sur un pari: on supposera que l'efficacité sera supérieure, si on a opté pour plusieurs plans sensés être adaptés aux formes de variabilité des sous-populations auxquelles ils sont appliqués.
Dans cette dernière partie, nous résumons les étapes de l'analyse qui devrait aider l'utilisateur à choisir la catégorie de plans qui répond le mieux à son objectif (encadré 49).
Incorporer l'information. Comme on l'a souligné dans les paragraphes précédents, il est essentiel d'examiner si des variables auxiliaires existent. Si elles sont disponibles avant l'échantillonnage, il faut choisir entre deux stratégies: elles sont incorporées soit dans le plan, soit dans la phase d'estimation. En fait, le choix est guidé par la nature de la variable et le degré de liaison supposé ou connu avec la variable d'intérêt. Si elles ne sont pas disponibles, de toute évidence, le sondeur tentera de mesurer les moins coûteuses et les plus informatives.
Modéliser les contraintes. Les variances des estimateurs sont des fonctions décroissantes de la taille de l'échantillon; pour un plan donné, il suffit donc d'accroître la taille de l'échantillon pour augmenter la précision de l'estimateur et par conséquent le coût de l'inventaire (ainsi que le temps de sa réalisation). Un bon critère de choix du plan d'échantillonnage est le rapport entre précision et coûts, encore appelé efficience. Le calcul de ce ratio implique que l'on puisse quantifier (voire estimer) les coûts d'observation des unités de la population, qui comprennent: la mesure de la variable d'intérêt, des variables auxiliaires et les coûts fixes (salaires, matériel de mesure, le traitement des données, etc.). En principe, on recherche ensuite la stratégie qui maximise l'efficience.
Evaluer l'efficience du plan. Dans la plupart des cas, le calcul analytique ne permettra pas de comparer les efficiences de chaque plan envisagé. On procède par simulations: il faut commencer par modéliser la distribution des valeurs de la variable d'intérêt sur l'ensemble des unités de la population, celle des variables auxiliaires, des coûts, puis pour chaque stratégie, constituer un ensemble d'échantillons à partir desquels le biais et la variance des estimateurs seront évalués. Comparer plusieurs stratégies s'avère donc vite fastidieux, c'est pourquoi il est vivement recommandé de procéder à un prééchantillonnage. Il s'agit de récolter les observations sur quelques unités (choisies elles-mêmes selon un plan probabiliste ou non), qui permettent d'obtenir une idée de la variabilité du phénomène étudié. Cette information permet de réduire le champ des possibles aussi bien en matière de distributions des variables qu'en types de plans. Elle permet aussi d'évaluer le degré de corrélation entre variables d'intérêt et auxiliaire. Même sans réaliser une telle étude, le prééchantillonnage sert à fixer le taux de sondage (pour un plan donné). Il est donc, ne serait-ce qu'à ce titre, intéressant de l'effectuer avant la réalisation de l'inventaire. Penser au prééchantillonnage implique aussi repenser l'évaluation de l'efficience: il faut inclure le coût du prééchantillonnage dans celui de l'inventaire et là encore, la question de stratégie se pose de nouveau en terme d'efficience! Quelle taille doit posséder le prééchantillon, selon quel plan doit-il être constitué? Il nous semble essentiel de posséder une information de qualité (pas trop imprécise) avant de procéder à l'inventaire et par conséquent d'y mettre le prix. Si on décide de garder le même plan, une partie de l'inventaire sera déjà effectué. Sinon, on devrait parvenir à une précision égale ou supérieure pour des coûts similaires, puisque le plan retenu sera en principe plus efficient, donc moins coûteux et compensera le coût du préinventaire.
Passer d'une échelle à l'autre? On pourrait reposer la question en termes plus statistiques: comment passer d'une estimation locale à une estimation globale ? Si la géostatistique répond bien à ce problème, il n'est pas certain, en revanche, que les plans de sondages puissent à eux seuls répondre à cette question. La méthode la plus simple consiste à faire une règle de trois pour passer d'un petit domaine à un domaine plus vaste. On suppose alors implicitement que la distribution des variables est la même sur les deux domaines. Beaucoup d'études géostatistiques (Cressie, 1991) ont au contraire montré que la variabilité s'accroissait avec l'extension du domaine et, par conséquent, ce procédé risque fort de produire des estimations entachées d'un biais élevé et de sous-estimer les variances. On peut aussi utiliser un modèle (modèles dans des sous-régions) de la population pour la zone considérée: les paramètres sont estimés à partir de (des) échantillon(s). Dans cette optique, l'échantillonnage peut être alors optimisé afin de fournir des estimations précises des paramètres du (des) modèle(s). Le plan de sondage qui répondrait le mieux à cette préoccupation serait l'échantillonnage à plusieurs degrés ou plusieurs phases, voire l'échantillonnage systématique, lorsque l'on est sûr de l'absence de périodicité de la variable.
Validation: une démarche nécessaire. En général, on ne sait pas si le plan d'échantillonnage et la taille de l'échantillon conviennent. Il serait quand même intéressant de pouvoir mesurer réellement l'adéquation du plan de sondage à l'objectif poursuivi. Pour cela, on peut imaginer plusieurs procédures. On peut augmenter la taille de l'échantillon afin de couvrir une plus grande variabilité (éventuelle) et utiliser ensuite des méthodes de rééchantillonnage statistiques (Davison et Hinkley, 1997), ou des méthodes de validation croisée (Droesbeke et al., 1987). On peut aussi choisir un échantillon dont certains sous-échantillons pourraient être issus d'autres plans de sondages, quitte à ajouter par la suite quelques unités judicieusement choisies. Par exemple, on peut réaliser un sondage stratifié aléatoire qui permette aussi un sondage en grappes.
D'une part, pour obtenir la meilleure précision avec un même taux de sondage, il vaut mieux en théorie de nombreuses petites placettes (unité de sondage) que peu de grandes placettes; mais l'efficience ne suit pas ce principe (figure 6). Il existe une taille de placette optimale qui dépendra notamment des coûts locaux de déplacements et de personnels.
D'autre part, il faut que l'échantillon observé sur chaque placette soit représentatif de la population étudiée. Par exemple, un seul arbre peut-il représenter un parc arboré ?
Cette contrainte a deux implications:
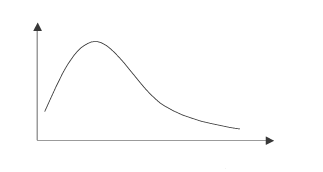
Figure 6. Evolution de l'efficience en fonction de la taille des placettes.
Pour la forme des unités de sondage, la théorie recommande les placettes circulaires, qui ont le moins d'arbres de limite par rapport aux autres formes à surface égale. Cependant, il est évident que cette forme circulaire ne s'accorde pas aux types d'arbres hors forêt ayant une géométrie linéaire (haies, brise-vent, arbres d'alignement), pour lesquels on préférera des placettes rectangulaires allongées. De plus, en pratique, les grandes placettes circulaires ne sont pas toujours faciles à installer.
7 Ou encore appelée covariable ou variable concomitante: en fait ces termes sont moins stricts dans la mesure où ils indiquent des variables qui ne sont pas mesurées nécessairement sur l'ensemble de la population.
9 Partition: découpage d'une surface en unités contiguës, non chevauchantes et dont la réunion forme la surface totale.
10 Les références bibliographiques figurent à la fin de la première partie.
![]()
![]()
![]()