Data collation, harmonisation and sharing
An overview of the data acquisition and sharing process is provided in the figure below.
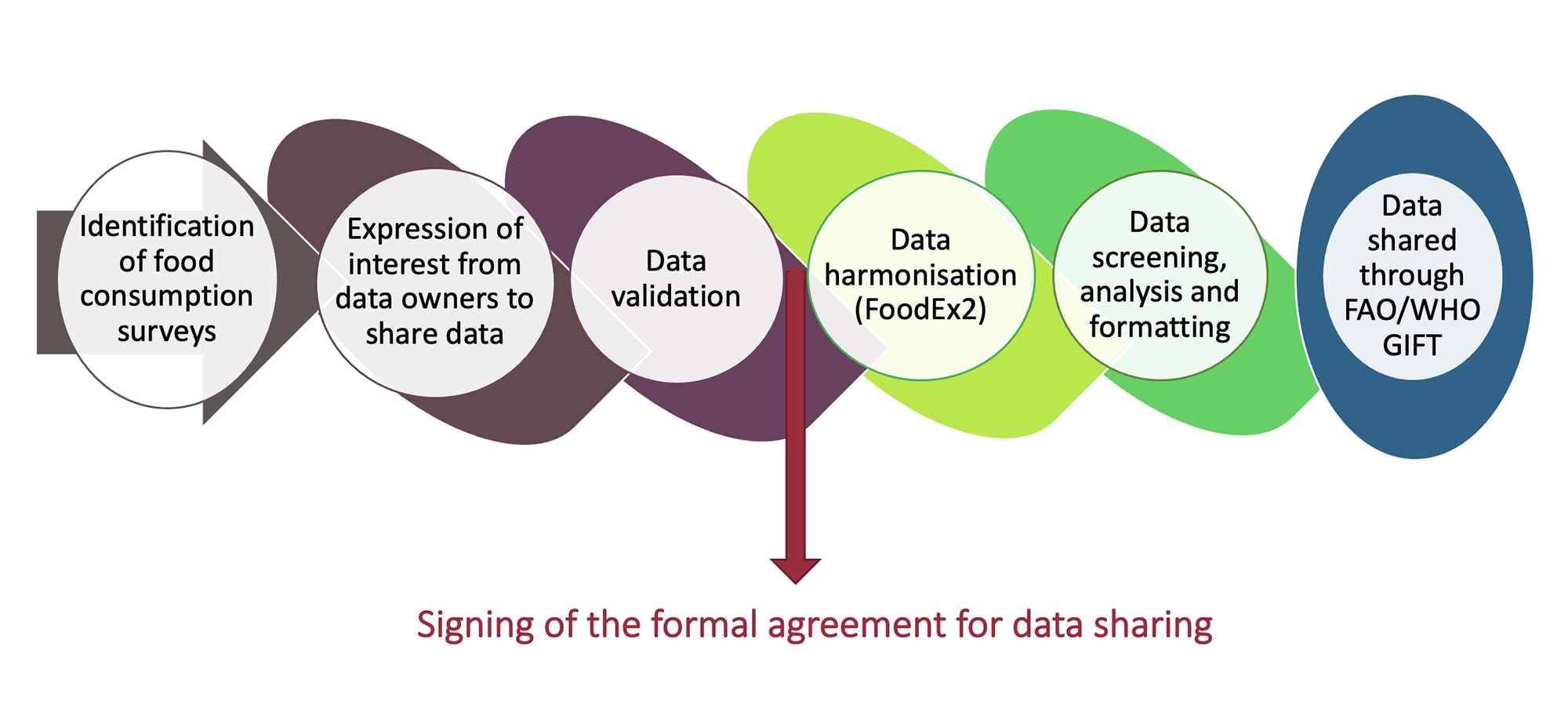
Only dietary surveys matching the following minimum criterion are shared through FAO/WHO GIFT:
- Unit of data collection: individuals.
- Methods for dietary data collection: 24-hour recalls, food records (weighed or estimated), or other quantitative methods, such as 12-hour recalls and direct food weighing. Only quantitative methods that involve recording of portion sizes are considered.
- Coverage of the diet: all foods and beverages consumed (including water if possible, but not compulsory).
- Year of data collection: 1980 or later.
- Geographical coverage: national and sub-national surveys.
- Sample size for which dietary data were collected: 100 or more subjects.
- Other representativeness criteria: no evidence of strong selection bias, such as surveys covering only participants with medical conditions.
- Additional criteria for high-income countries: nationally representative surveys.
All datasets are screened, analysed and formatted according to the FAO/WHO GIFT microdata template and FAO/WHO GIFT codebook before inclusion in the platform. This process includes the renaming and recoding of variables according to the codebook, screening for potential errors, and identification of missing values and outliers. The data analysis and formatting are done using the R programming language and RStudio free software.
Country names and administrative region classification
The country name and the name of the administrative regions available in the datasets are mapped to the Global Administrative Unit Layers Administrative Unit Layers (GAUL) initiative.
Identification of outliers
Key variables in the dataset are analysed for the presence of outliers, namely variables for weight, height, amount consumed and energy and nutrient values. This step is aimed at identifying potential errors or extreme values that could impact the results generated from the dataset. Extreme values are discussed with the data provider and an agreement on how to deal with outliers is sought. If an extreme value is considered implausible and likely to affect the statistics presented in the platform, and no solution is identified together with the data provider, FAO may replace the extreme value and impute with a plausible value, specifically for the purpose of calculating the indicators and summary statistics presented in FAO/WHO GIFT. For each dataset, information on how outliers were treated are available in the survey metadata (i.e. survey details). FAO does not remove or treat outliers from the microdata disseminated through the platform, unless the data provider requests it. Users downloading the microdata for further analysis should screen the dataset for potential outliers that could affect their results and treat them accordingly.
Identification of missing values
All variables are screened for missing values. Missing values are not accepted for compulsory variables such as subject ID, food name and amount consumed. Missing values for other variables are discussed with the data provider and an agreement on how to deal with them is reached. If a nutrient variable contains missing values that could influence the results presented in the indicators and summary statistics, and underestimate nutrient intake, the results are not presented for the given nutrient. Information on how missing values were handled are available for each dataset in the metadata (i.e. survey details). Missing values are never imputed by FAO in the microdata disseminated through the platform unless the data provider requests it. Users downloading the microdata for further analysis should screen the dataset for missing values that could affect their results and treat them accordingly.
Food composition values
Energy and nutrient values available in the datasets shared through FAO/WHO GIFT are provided by the data providers. FAO does not match food consumption datasets to food composition data for the FAO/WHO GIFT platform. If issues related to the food composition values are encountered during the data analysis process, they are discussed with the data provider and an agreement reached on how to resolve them.